




实体识别(信息抽取)
1. 信息抽取概述
- 信息抽取定义:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。(Grishman,1997)
- 信息抽取的主要任务:实体识别与抽取、实体消歧、关系抽取、事件抽取
2. 信息抽取的基础:分词和词性标注
2.1中文分词
- 中文以字为基本书写单位,词语之间没有明显的区分标记
- 中文分词就是要由机器在中文文本中词与词之间加上标记。
- 和中文分词相比,英语切分问题相对容易。
2.2词性标注
- Part-of-speech(POS) tagging(词性标注):消除词性兼类歧义,即确定当前上下文每个词是名词、动词、形容词或其他词性的过程。
eg:名词和动词的兼类:爱好,把握,报道。
2.3中文分词的难点:
- 汉语中,字、词、词素和词组的界限模糊:吃饭、吃鱼、吃羊肉、吃羊肉串
- 歧义切分字段处理:
1.交集型歧义:对于汉字串ABC,AB,BC同时成词:研究生物,从小学起等
2.组合型歧义:对于汉字串AB,A、B、AB同时成词:门/把/手/弄/坏/了。门/把手/弄/坏/了。
3.真歧义:歧义字段在不同的语境中确实有多种切分形式:乒乓球拍/卖/完了。乒乓球/拍卖/完了。 - 未登录词(未登录词即没有被收录在分词词表中但必须切分出来的词)识别:
1.实体名词和专有名词:eg.中国人名,中国地名,翻译人名,翻译地名,机构名,商标字号。
2.专业术语和新词语:专业术语、缩略语、新词语。
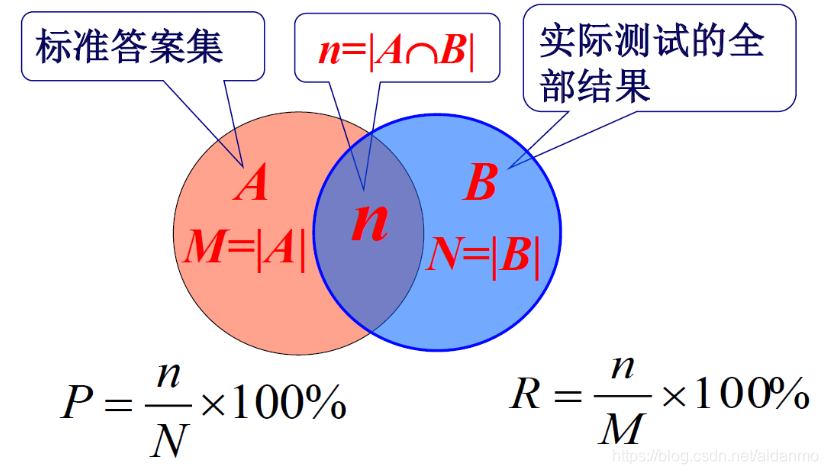
2.4中文分词结果的评价:
- 封闭测试和开放测试
开方测试指的是测试样本不属于训练样本集合,否则称为封闭测试;
封闭测试相当于考试试题都出自于学习过的书本,实际上,通过机械记忆小样本的封闭测试取得100%的精度不存在问题。 - 专项测试和总体测试
专项测试是对特定领域或者特定类型的样本进行测试,反之成为总体测试。
总体测试能反映分词系统的综合效果,专项测试可以反映分词系统针对某个特定领域或者特定类型文本的效果。 - 评价指标:
真确率:测试结果中正确切分或标注的个数占系统所有输出结果的比例。P
召回率:测试结果中正确结果的个数占标准答案总数的比例。R
F值:正确率与召回率的综合值。
F1=2×P×RP+RF1 = \frac{2 \times P \times R}{P + R}F1=P+R2×P×R
2.5基于字典的分词方法
-
方法概述:按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
-
典型方法:
1.正向最大匹配法
2.反向最大匹配法
3.最短路径法(最少分词法) -
eg.
句子:中医治白癜风 词典:中、医、治、中医、医治、白癜风
正向最大匹配法:中医/治/白癜风
反向最大匹配法:中/医治/白癜风
最短路径法:
独立自主/和平/等/互利/的/原则
独立自主/和/平等互利/的/原则 -
正向最大匹配(Forward Maximum Matching, FMM)
1.令i=0,当前指针PiP_iPi指向输入字串的初始位置,执行下面的操作:
2.计算当前指针PiP_iPi到字串末端的字数(即未被切分字串的长度)n,如果n=1,转第4步,结束算法。否则,令m=字典中最长单词的字数,如果n<mn<mn<m,令m=n;
3.从当前PiP_iPi起取m个汉字作为词wiw_iwi,判断:
(1)如果wiw_iwi确实是词典中的词,则在wiw_iwi后添加一个切分标志,转(3);
(2)如果wiw_iwi不是词典中的词且wiw_iwi的长度大于1,将wiw_iwi从右端去掉一个字,转(1)步;否则(wiw_iwi的长度等于1),则在wiw_iwi后添加一个切分标志,将wiw_iwi作为单字词添加到词典中,执行(3);
(3)根据wiw_iwi的长度修改指针PiP_iPi的位置,如果PiP_iPi指向字串末端,转第4步,否则,i=i+1i = i + 1i=i+1,返回(2);
4.输出切分结果,结束分词程序 -
最短路径法
1.相邻节点Vk−1,VkV_{k-1}, V_kVk−1,Vk之间建立有向边<Vk−1,Vk><V_{k-1}, V_k><Vk−1,Vk>,边对应的词默认为Ck(k=1,2,...,n)C_k (k = 1, 2, ..., n)Ck(k=1,2,...,n)。
2.如果w=CiCi+1...Cj(0<i<j<=n)w = C_i C_{i+1}... C_{j} (0<i<j<=n)w=CiCi+1...Cj(0<i<j<=n)是一个词,则节点Vi−1,VjV_{i-1},V_jVi−1,Vj之间建立有向边<Vi−1,Vj><V_{i-1}, V_j><Vi−1,Vj>,边对应的词为w。

3.重复步骤2,直到没有新路径(词序列)产生。
4.从产生的所有路径中,选择路径最短的(词数最少的)作为最终分词结果。
2.6基于统计的分词方法
基于统计的方法需要标注训练语料训练模型,可分为生成式统计分词和判别式统计分词
2.6.1 生成式方法
原理:首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理。
马尔可夫模型
存在一类重要的随机过程(马尔可夫过程):如果一个系统有N个状态S1,S2,...,SNS_1, S_2, ..., S_NS1,S2,...,SN,随着时间的推移,该系统从某一个状态转移到另一状态。如果用qtq_tqt表示系统在时间t的状态变量,那么t时刻的状态取值为Sj(1<=j<=N)S_j (1<=j<=N)Sj(1<=j<=N)的概率取决于前t-1个时刻的状态,该状态的概率为:
P(qt=Sj∣qt−1=Si,qt−2=Sk,...)P(q_t = S_j | q_{t-1} = S_i, q_{t-2} = S_k, ...)P(qt=Sj∣qt−1=S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5479
5479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











