




这篇文章的测试主要针对两个问题:
- 魔改4090 48G显存的显卡对比原始的4090 24G显卡算力是否有下降?
- 魔改4090 48G显卡对比专业级训练显卡A100 40G,其在模型训练场景到底性能表现如何?
之前比较过3090、4090和5090的算力差异:
使用PyTorch进行显卡AI性能实测
ResNet-50模型实测深度学习场景显卡性能
这里还是使用 ResNet-50 进行模型训练测试。
A100 40G和4090 48G参数对比
两张显卡的参数规格:
| A100 40G | 4090 48G | |
|---|---|---|
| 架构 | Ampere | Ada Lovelace |
| CUDA核心数 | 6,912 | 16,384 |
| 显存容量 | 40GB HBM2 | 48 GB GDDR6X |
| 显存带宽 | 1,555 GB/s | 1,008 GB/s |
| TDP功耗 | 250W | 450W |
| FP32 算力 | 19.5 TFLOPS | 82.6 TFLOPS |
| Tensor FP16 算力 | 312 TFLOPS | 330 TFLOPS |
- 显存方面:4090是魔改后翻倍的48G显存,要大于低版本A100的40G显存,但A100 40G用的HBM2显存,带宽可以接近1.6T/s
- 算力方面:4090在单精度计算上有绝对的优势,半精度Tensor算力两者接近
- A100 PCIe版本的功耗做了限制,所以从耗电量上4090会更大
深度学习模型训练测试
在 晨涧云AI算力平台 分别租用A100 40G和4090 48G的云主机实例。
基于Pytorch框架来训练ResNet-50模型,使用CIFAR-10数据集进行测试对比。
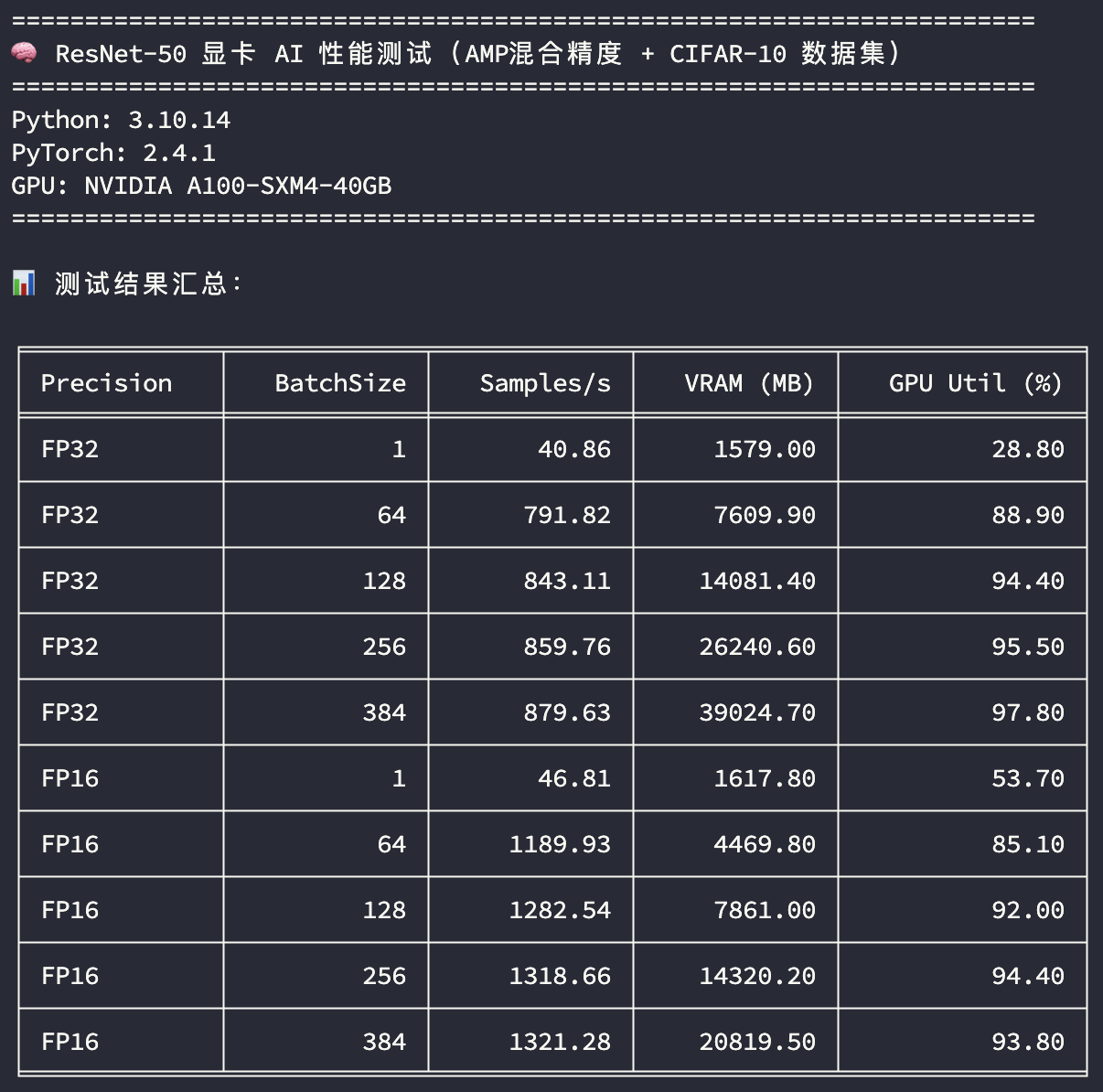
A100 40G测试
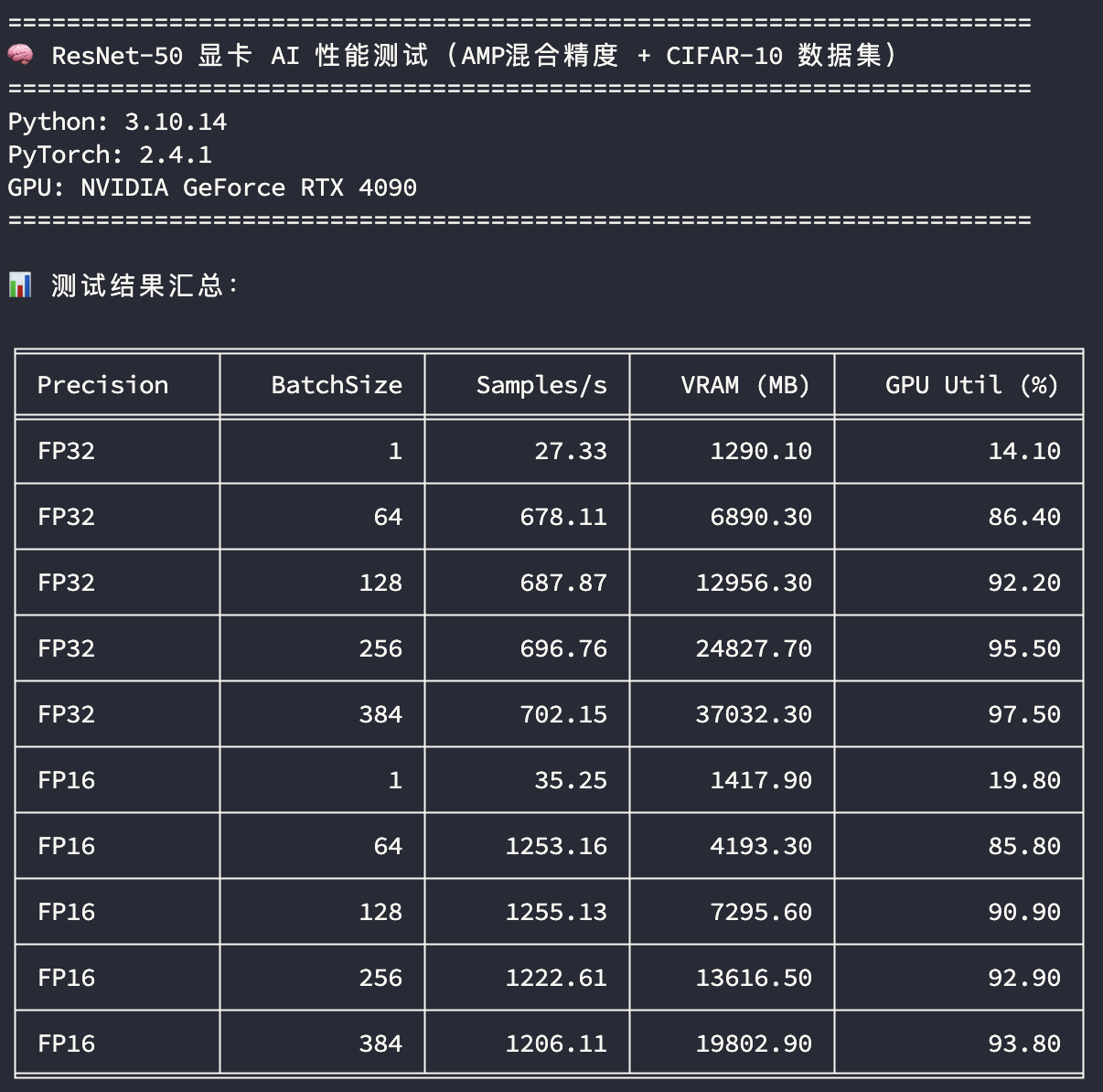
4090 48G测试
补充之前测试的4090 24G的结果:
4090 24G测试
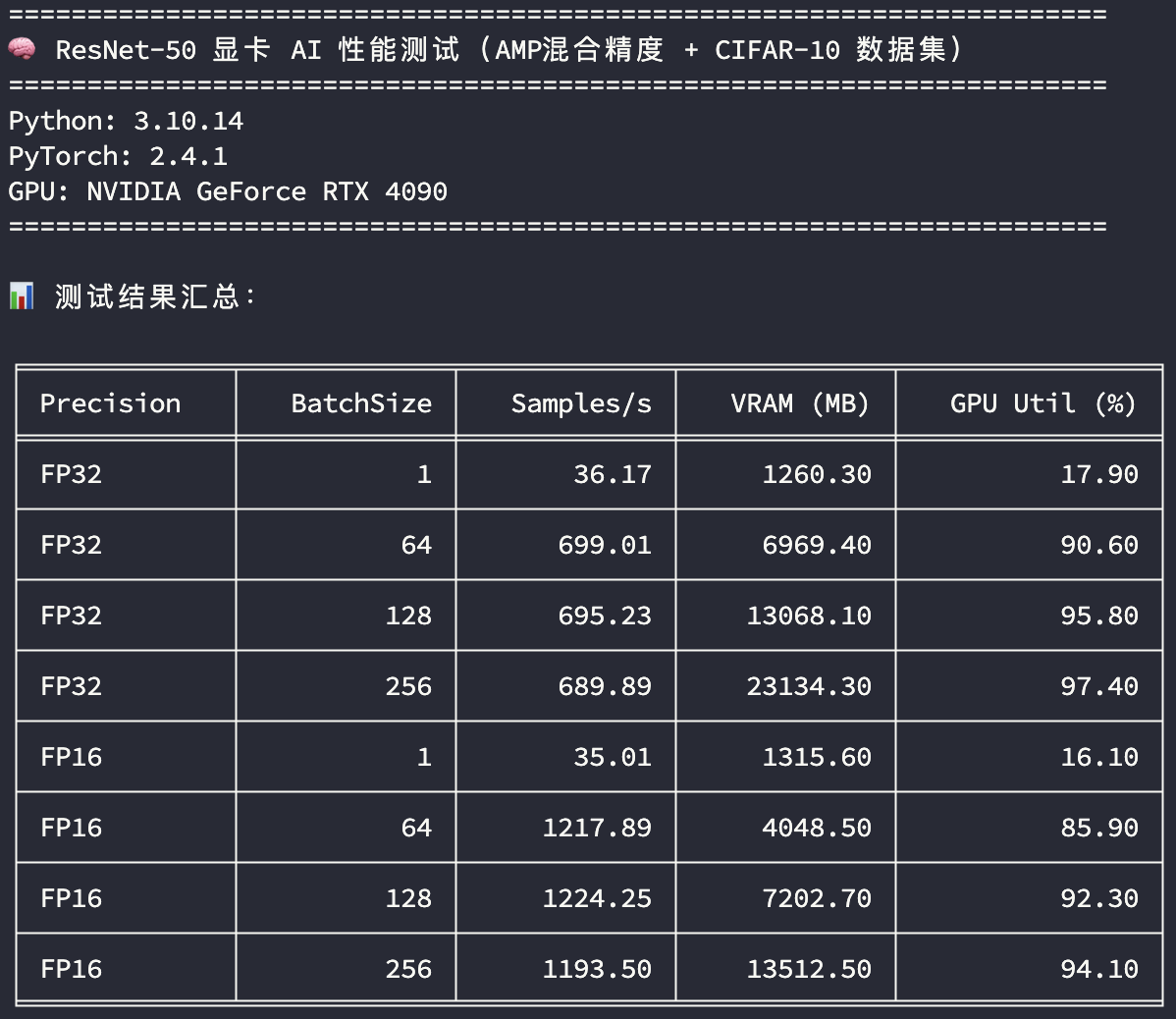
可以看到魔改48G显存的4090显卡在算力方面并没有折损,并且48G显存提供了更多的BatchSize样本吞吐空间。
测试结果解释
使用了FP32和FP16混合训练精度,相比之前3090和4090的测试,因为A100 40G和4090 48G有更大的显存,训练批次在原先的基础上增加了384的BatchSize,看训练吞吐量的差异:
- 精度:FP32 表示使用单精度训练,FP16 表示使用混合精度训练
- BatchSize:训练批次大小
- Samples/s:每秒样本吞吐量
- VRAM (MB):平均显存使用量
- GPU Util (%):平均GPU利用率
看在GPU使用率比较高的场景下(BatchSize>=256),模型训练样本的吞吐速度比较;单精度训练A100 40G的样本吞吐速度是4090 48G的125%,半精度训练A100 40G的样本吞吐速度是4090 48G的105%。
综合而言,A100作为专业级训练卡在训练场景还是有其优势的,而且A100支持NVLink和MIG;但相比4090的算力差距并不明显,而4090在其他场景,特别是图像处理、3D渲染等也非常能打,再加上魔改的48G显存,目前在中端显卡市场可以说是最全面的存在。

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









