




本人项目地址大全:Victor94-king/NLP__ManVictor: 优快云 of ManVictor
原文地址: 如何从头训练大语言模型: A simple technical report - 知乎
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
大模型时代,倒不是看谁代码写的好了,只有涉猎广泛,有训练经验,能进行Infra的debug,肯认真做数据,才是王道。所以我觉得眼下最有价值的文章,还得看大厂技术报告。
1. Model Architecture
分两块讲:语言模型本身和对应的tokenizer构建。这部分没什么好说的,比较简单,大家都差不多。
基本都是llama的魔改,不过今年大家更关注inference消耗和长文本了,所以出现了各种各样的变体。其中Deepseek的MLA架构一枝独秀。不过我不想讨论MoE。
与图像生成模型还在忙着争论模型架构不同,主流自回归LLM基本都是casual attention,只是各家对MHA做了优化而已,目的是为了尽可能减少kv cache, 从而在更少的显存消耗上做到更快的推理速度,降本增效。
1.1 MQA->GQA->MLA
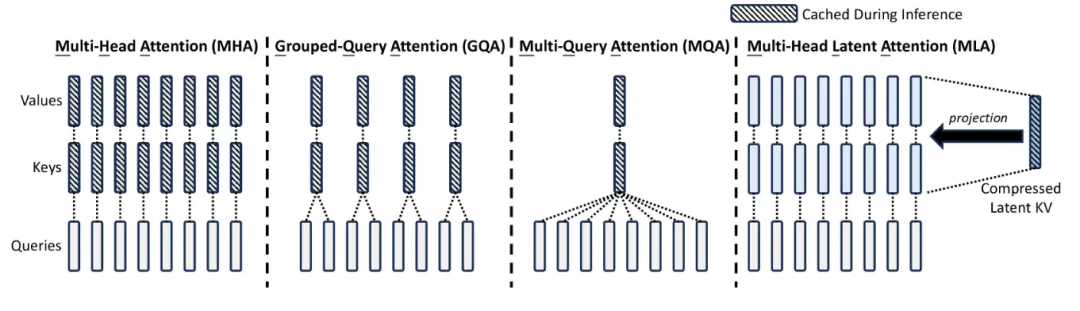
- MQA :把多头注意力里的多个attention head去对应一个K与V,非常朴素的想法,是kv cache节约的上界。过于暴力,今年应该没人用了。
- GQA :介于MHA与MQA之间,把attention head分成多个group, 组内共享KV,十分自然的过渡。
- MLA :只需要少量的 KV 缓存,相当于只有 2.25 组的 GQA,但却能获得比 MHA 更强的性能。不过没法直接使用ROPE倒是一个弊病,需要做一些改动。虽然MLA会增加一些计算,但是推理速度无疑是很快的。
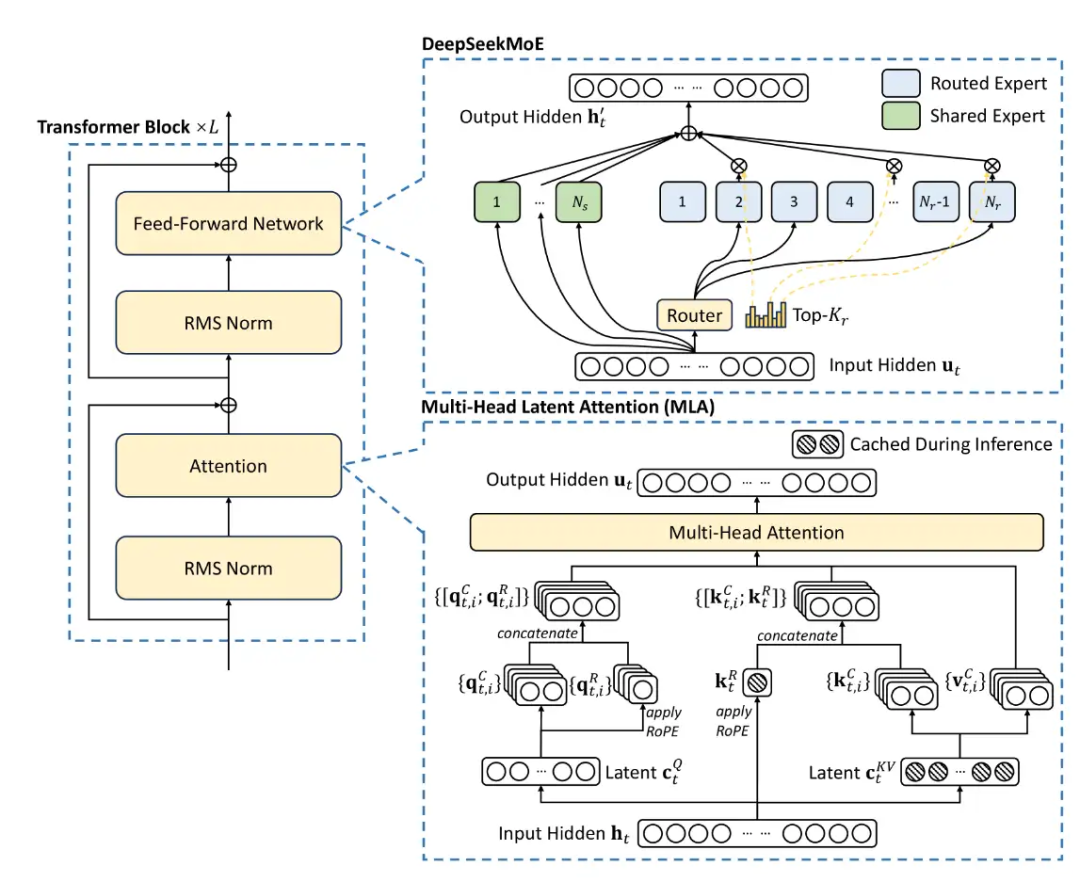
1.2 Norm, Activation, Initialization
现在主流共识是用RMSNorm和SwiGLU, 比layernorm和relu两个老东西效果好多了,训练也更稳定。(不过GLM是用的GeLU和deepnorm)
为了保证训练稳定(实在太难了),一般采用预归一化,先归一化,再残差计算。据说post-norm效果更好,但不够稳定。
参数初始化策略看模型大小而定。某些策略似乎能缓解loss spike现象,可见Spike No More: Stabilizing the Pre-training of Large Language Models
https://arxiv.org/pdf/2312.16903
1.3 Long Context
今年大家都卷起来了,似乎没有1M窗口都不好意思发布模型,“大海捞针”实验上kimi还是一枝独秀。
位置编码都是ROPE, 不少工作都在探究ROPE怎么做外推/内插。此前基本就是PI和NTK。后续训练中也有逐步增大ROPE基频的.
qwen报告里使用了Dual Chunk Attention(DCA),这是training free的;后面用yarn调整注意力权重做外推.
1.4 Tokenizer与词表
不少工作都是直接挪用的别人的tokenizer, 如果自己从头训,好处可能是在自己数据上有更高的压缩率(词表大小相同的情况下)。主流算法都是BPE或者BBPE比较多。实际训练上主要是工程优化并发的问题。
记得评估一下tokenizer的压缩率。压缩率表示文本向量化后的长度,压缩率越高向量越短。多语言的时候也留意一下token的覆盖率,比如llama的中文就不太行,他们的训练数据本身中文就很少 (不知道为什么meta这么做,反而support一些其他的语言比较多)
一个非常重要的问题就是词表的修改。尤其是SFT阶段有些special token, 做agent的时候更重要了,最好不要等模型训起来了再去补词表,否则norm的时候会乱掉,调整起来多少有些麻烦。当然,有些人也有词表剪枝的需求,去掉冗余的token,比如只要英文,这样可以大大减少参数量。
词表的大小也很重要,词表越大,也会导致Loss越大。有些文章在探讨vocal size的scaling law,很有意思:Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies (arxiv.org)。数据瓶颈就减小词表,够的话自然上大词表,vocab size经验一般是64的倍数。
https://arxiv.org/abs/2407.13623v1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











