




大家好,我是爱酱。本篇将会系统讲解AI偏见(Bias in AI)与可解释性(Explainability, XAI)的核心概念、成因、现实影响、主流方法和工程实践。内容包括定义、数学表达、真实案例、技术路线和两者的关系,适合初学者和进阶者系统理解
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、什么是AI偏见(Bias in AI)?
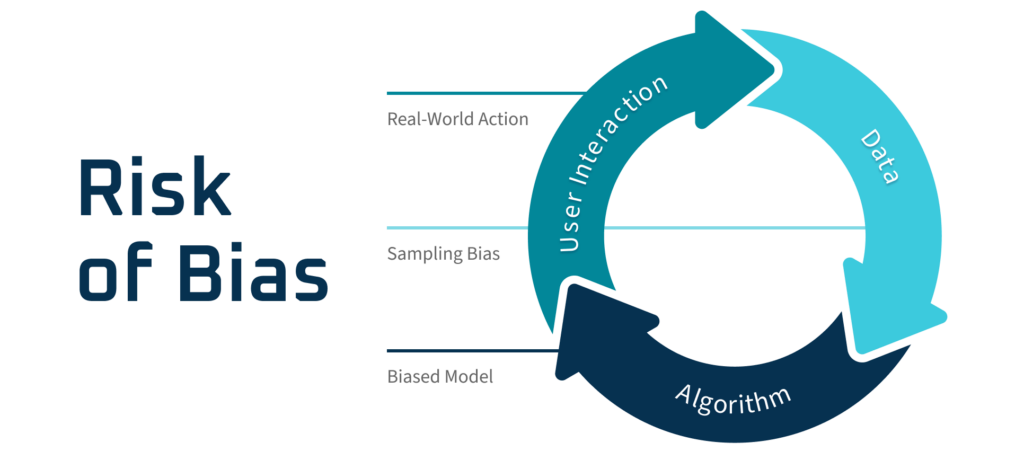
1. 定义
AI偏见(Bias in AI)指的是人工智能或机器学习系统在决策、预测或分类时,系统性地对某些群体、特征或个体产生不公平、歧视性或有偏的结果。这种偏见可能导致某些群体被低估、误判或受到不公正待遇。
-
英文专有名词:AI Bias, Algorithmic Bias, Machine Learning Bias
2. 数学表达
在二分类任务中,如果模型对不同群体的误差率存在显著差异,即体现了偏见。例如,假设、
为不同群体,
、
为其误差率:
若显著大于0,说明模型对群体
和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









