






目录
- **需要明白的参数:**
- **⭐第一次选举(重启后的选集)**
- **⭐选举过程**
- **⭐选举的特点**
- **⭐第二次选举(运行中的重新选举)**
- **选举过程**
- **⭐选举算法实现**
需要明白的参数:
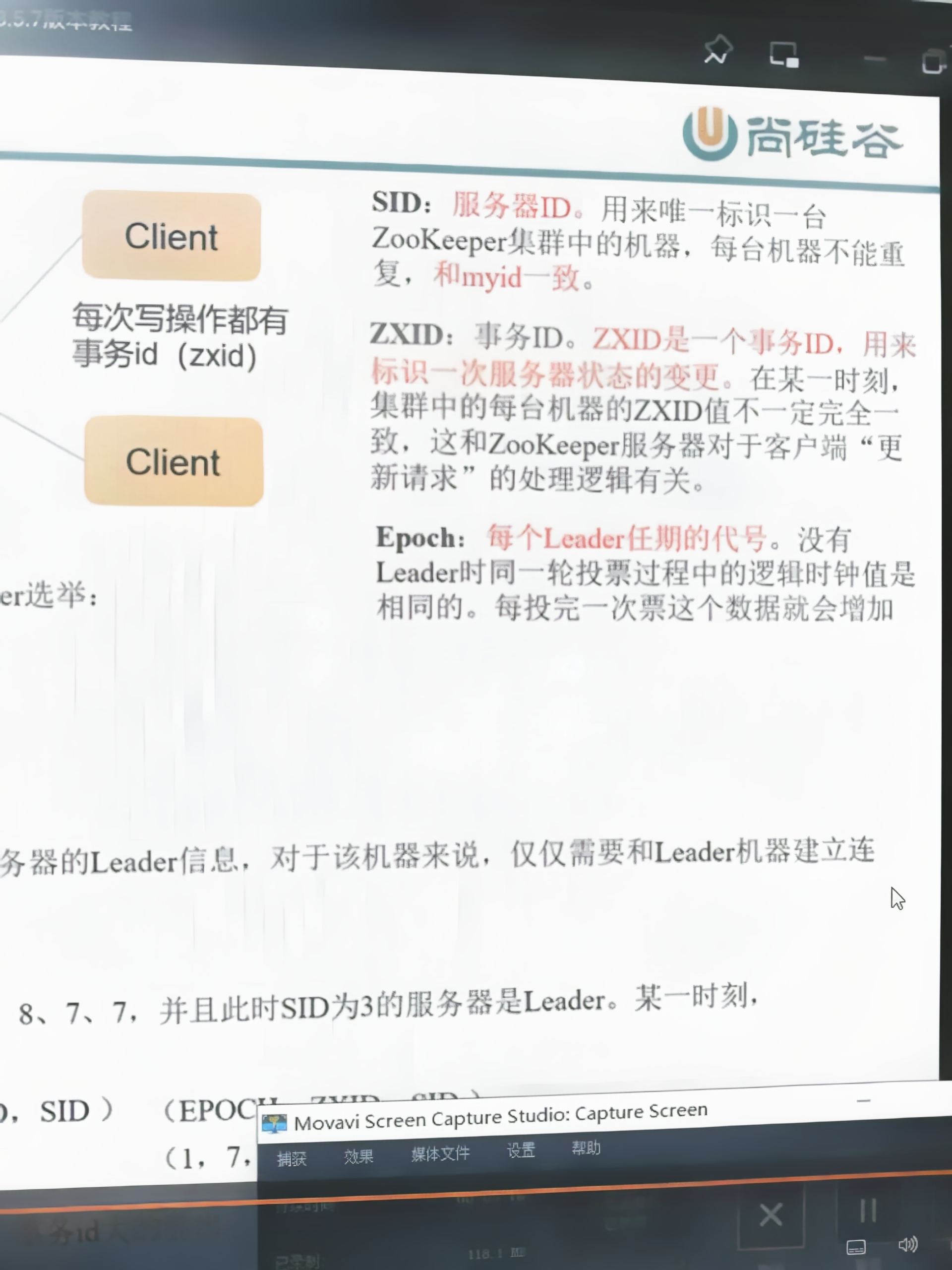
-
myid:每台服务器,每个节点的唯一标识,不可重复
-
zxid:事务id,初始值为0,每完成一次读写操作,都会+1
(leader先完成一次,再由follower按序依次完成) -
epoch:每个leader的任期代号,对于某个节点,每经过一次leader的选举成功,+1
当某个节点挂掉重启后,正好参与一次选举,那么它的epoch为“1”
⭐第一次选举(重启后的选集)
(五个节点组成的集群)
注:
由zoo.cfg文件配置的server的顺序,可知节点的启动顺序
第一次选举与myid有重要联系,超过半数节点的投票的节点,当选leader
- 投票原则:
比较myid,myid小的节点,把票投给myid大的节点 - 例:
Hadoop101的myid为1
Hadoop102的myid为2
Hadoop103的myid为3
Hadoop104的myid为4
Hadoop105的myid为5
⭐选举过程
①每个节点给各自投票
此时每个节点各一票
②广播投票(原则上比较myid)
101投给102
102把自身现有的两票投给103
103现在有3票,超过了集群一半个数的票,Hadoop103当选leader
104与105即使myid更大,但已经选举出了leader,此时也无济于事
③达成共识
当某台服务器获得 超过半数(Quorum) 的投票时,成为 Leader,状态变为 LEADING;其他服务器变为 FOLLOWING
⭐选举的特点
- 所有服务器的 zxid 均为 0,因此 myid 更大的服务器会胜出
- 生产环境中通常会将 myid 最大的服务器最后启动,避免重复选举
⭐第二次选举(运行中的重新选举)

当节点发生宕机,失去与集群其他节点的通讯时,会请求选举,此时就有如下两种情况
-
①宕机的节点是follower,此节点与其他节点交流时,发现leader还存在,则放弃选举
并将此节点与leader连接,并动态同步一下 -
②宕机的节点是leader,开始选举
选举过程
-
自投票阶段:每台服务器投票给自己投票内容为
(myid, 当前最大 zxid, 当前 epoch+1)。 -
广播与比较:同样广播投票并按以下优先级比较:
- 优先 epoch 更大的服务器,epoch大者,直接胜出
- 其次zxid更大的服务器,epoch相同时,比较zxid,大者胜出
- zxid 相同则选择 myid 更大的服务器
- 同步确认:新 Leader 产生后,会与 Follower 同步数据,确保所有服务器的数据一致
⭐选举算法实现
ZooKeeper 默认使用 FastLeaderElection 算法(基于 TCP 通信),核心流程如下:
- LOOKING 状态:服务器发起投票
- 投票队列:维护一个投票集合,记录收到的所有投票
- 统计 Quorum:检查是否有投票获得半数以上支持
- 状态切换:确认 Leader 后,切换为
FOLLOWING或LEADING

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









