






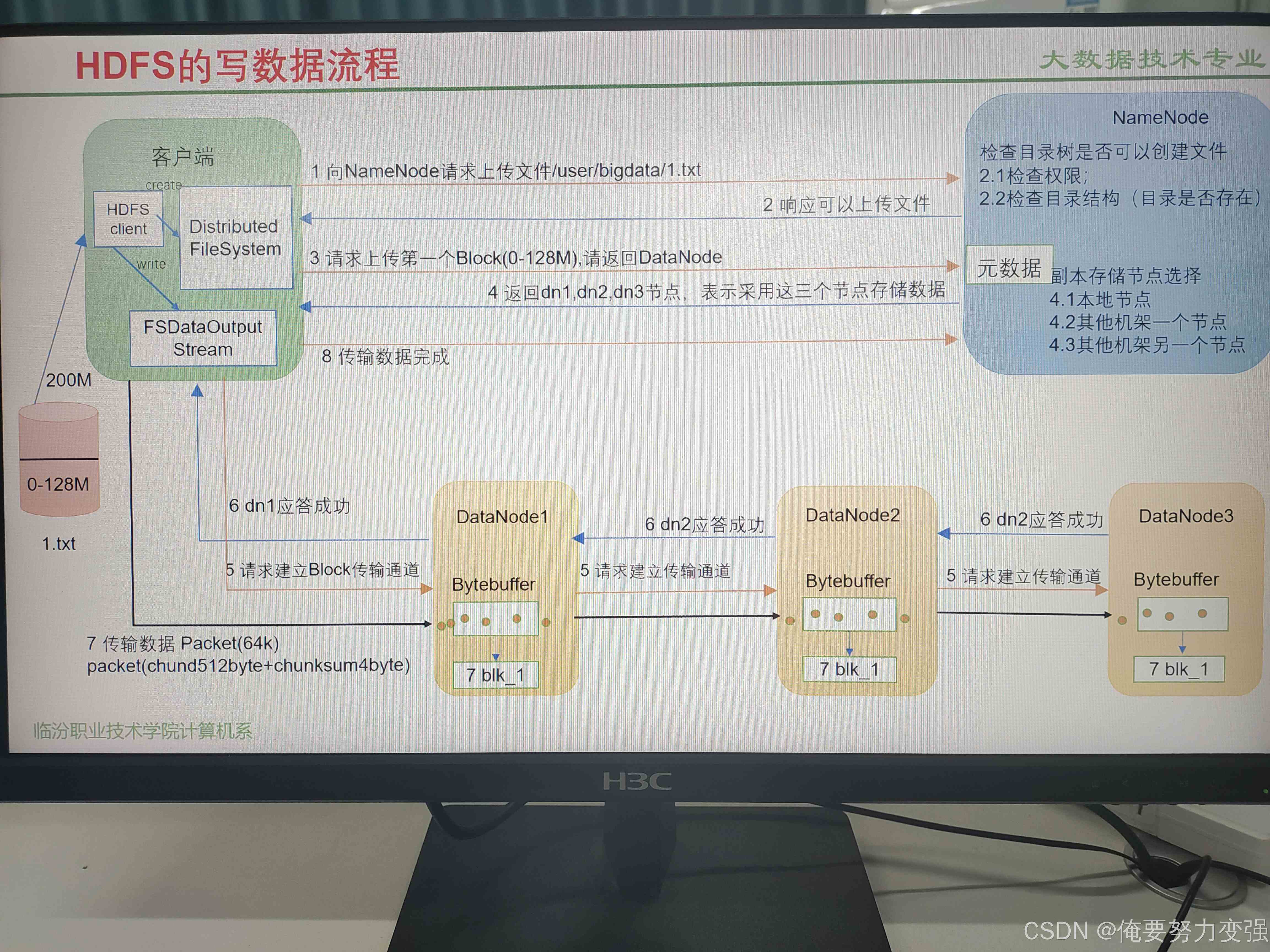
⭐写操作时 需要的组件
客户端
NameNode
DataNode
⭐第一步 发送 上传请求
★客户端:
打招呼,通知NameNode,要在某个位置存入一个文件
★NameNode:
先 检查权限,检查客户端是否有权进行操作
后 检查文件,检查是否有所要写入的位置
最后 通知客户端,是否可以开始执行操作
⭐第二步 上传内容分块 并 分配储存位置
-
客户端上传的内容分块:
客户端将上传的文件内容分成块
要注意,存储的块是一块一块按序存储,不能一起进行
(分块的大小与Hadoop的版本有关)
(1x版本,块的大小为0-64MB)
(2x、3x版本,块的大小为0-128MB) -
找储存节点:
客户端资讯NameNode,第一块存储在哪里,NameNode告诉客户端存储在哪几个DataNode
(默认为三个,一个DataNode对应着一个副本)
(1) 第一个副本
- 策略:优先存储在客户端所在的DataNode(如果客户端不在集群内,则随机选择一个节点)。
- 目的:减少网络传输开销,提升写入速度。
(2) 第二个副本
- 策略:存储在同一机架(Rack)内的另一个DataNode。
- 目的:利用机架内高带宽,保证副本间快速同步,同时避免跨机架传输延迟。
(3) 第三个副本
- 策略:存储在不同机架的另一个DataNode。
- 目的:防止机架级故障(如断电、网络中断)导致数据全部丢失,提升容灾能力。
⭐第三步 建立传输通道
- 通道建立:
客户端与三个DataNode之间建立一条道路(例如dn1、dn2、dn3)
像组队一样建立起传输链:
客户端 -> dn1 -> dn2 -> dn3 - 确保通道的通畅:
客户端依次联系三个DataNode,确保通道的连通
⭐第四步 开始传数据与结束确认
- 拆小包传输:
- 客户端把128MB的块拆成更小的数据包(packet)(如一个数据包64KB),再把一个数据包拆成512个字节的小段(chunk)(带检验码,放置传错)
- 流水线作业:
- 客户端先传给dn1,dn1存下数据后,立刻传给dn2。
- dn2存完再传给dn3。
- 最后dn3存完会逐级回传确认消息(“我存好了!”),最终告诉客户端:“这一包传完了!”
- 容错机制:
- 如果某个DataNode挂了(比如dn2宕机),客户端会重新组队(比如用新节点dn4代替dn2),继续传剩下的数据。
⭐第五步 循环上传
- 完成当前块:
第一个数据块拆分成的数据包全部上传完成后,客户端通知NameNode说,第一块传好了 - 继续上传后续块:
重复 第二步 到 第四步 ,上传第二个块,直到所有内容上传结束
⭐第六步 收尾
- 关闭连接
客户端最后结束与DataNode的连接,NameNode更新元数据,标志数据上传成功

















 3040
3040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









