






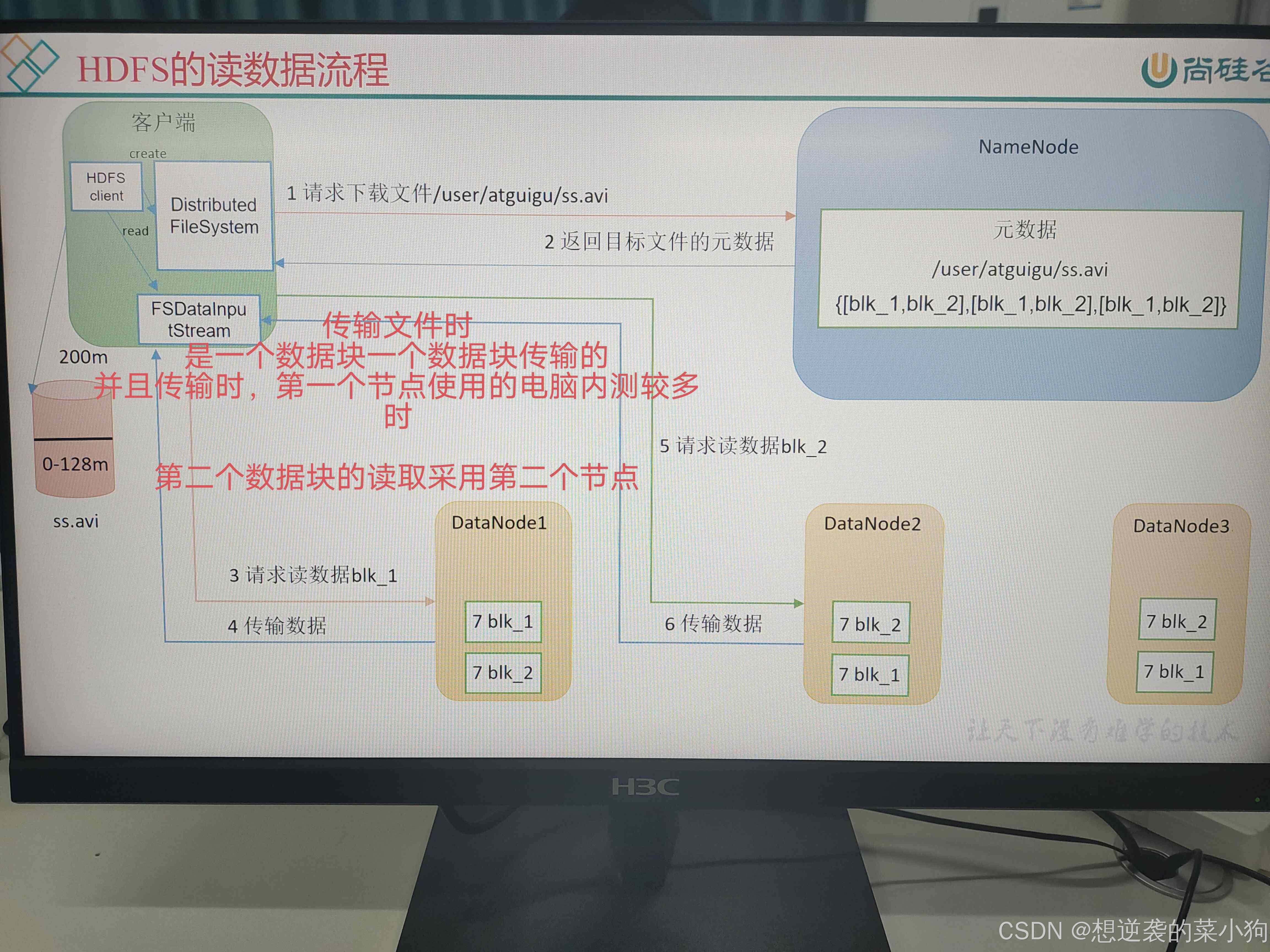
⭐读 操作需要的设备
客户端
NameNode
DataNode
⭐第一步 发送读取请求
- 客户端:
打招呼,向NameNode请求想要下载的元数据
PS:
(元数据包括被分为了哪些数据块以及数据块的副本在哪个DataNode存放)
⭐第二步 获取元数据
- NameNode:
返回文件的元数据,告诉每个数据块的位置
⭐第三步 按块读取数据
客户端通过FSDataInputStream(一个支持分布式读取的数据流)逐个数据块的下载文件
下载有两种方式
- 第一种:
可以只使用用一个DataNode,但是数据块只能逐个下载 - 第二种:
并行传输,不同数据块可以并行在不同的DataNode中下载,如果某个DataNode故障,客户端会自动切换到其他副本所在的节点,确保读取过程不中断
⭐第四步 最终合并文件
所有数据块下载完成后,客户端将它们按顺序拼接成完整的文件(如ss.avi),返回给用户
关键点:
- HDFS通过将文件切块、多副本存储,实现了高速读取和高容错性
- 客户端会根据节点负载动态选择最优的DataNode,提升效率
- NameNode不直接参与数据传输,只负责管理元数据,减轻了中心节点的压力


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









