




 本文详细解析了GDB调试原理,教你如何设置断点,定位CPU占用高的问题,以及如何使用Valgrind检测内存泄漏。还讨论了栈与堆效率差异及构造函数不可继承的原因。
本文详细解析了GDB调试原理,教你如何设置断点,定位CPU占用高的问题,以及如何使用Valgrind检测内存泄漏。还讨论了栈与堆效率差异及构造函数不可继承的原因。
字节面经
文章目录
GBD调试的原理
gdb调试可以用vscode的launch进行配置,同时也可以用用Cmake进行一个编译在进行调试
GBD调试包括两个程序:(1) gdb程序,(2)被调试程序
- 本地调试 上面两个程序都运行在本地
- 远程调试 调试程序在一台电脑,被调试程序在另外一台电脑
gdb的调试命令
run , step , next , continue , quit
break n , delete n , enable n , disable n
where : 显示当前位置
bt :(backtrace) 列出调用栈
set args : 设置变量
watch: 监控某个变量的改变
show args: 查看参数
原理
当我们在终端执行 gdb ./test.out的时候操作系统发生了很多的事
操作系统首先启动gdb进程,这个进程会调用fork()函数创建一个子进程这个子进程做两个事情
(1) 调用系统函数ptrace()
(2)调用execv来加载执行我们的被调试的程序
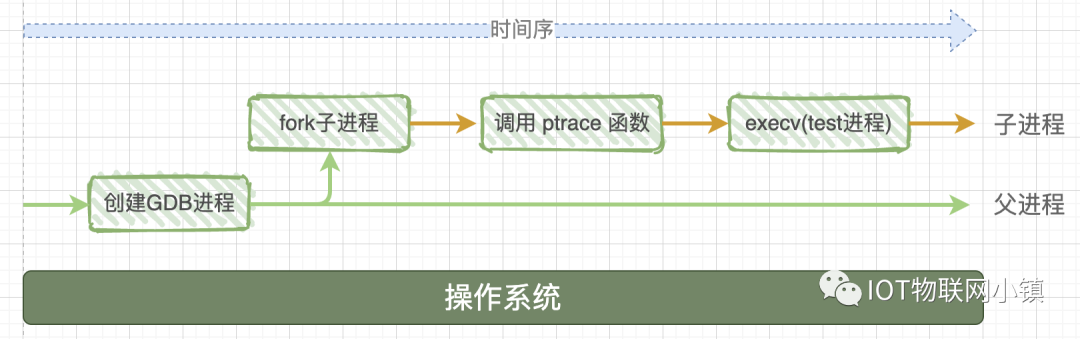
TIPS:
execv(const char* path,char* constargv[])这个函数会停止执行当前的进程,会用path文件路径下的应用进程替换掉被停止的进程,进程的ID没有改变
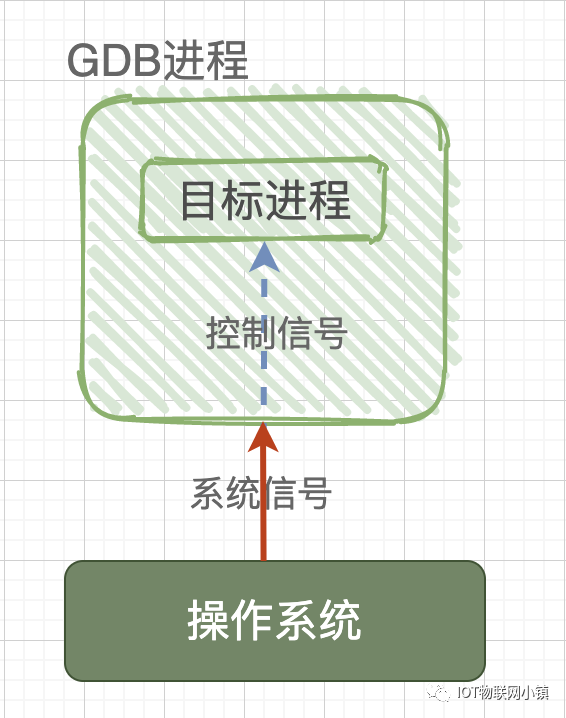
ptrace系统函数是Linux内核提供的一个用于进程跟踪的系统调用,通过它,一个进程(gdb)可以读写另外一个进程(test)的指令空间、数据空间、堆栈和寄存器的值。而且gdb进程接管了test进程的所有信号,也就是说系统向test进程发送的所有信号,都被gdb进程接收到,这样一来,test进程的执行就被gdb控制了,从而达到调试的目的。
相当于这样一种情况:如果没有 gdb 调试,操作系统与目标进程之间是直接交互的;如果用gdb 来调试程序,那么操作系统发送给目标进程的信号就会被 gdb 截获,gdb 根据信号的属性来决定:在继续运行目标程序时是否把当前截获的信号转交给 test,被调试程序 test 就在 gdb 发来的信号指挥下进行相应的动作。
gdb如何实现断点的呢
其实就是在设置断点的时候,
- 会把源码对应的汇编代码存储到断点表里面
- 在对应的汇编代码的位置替换成中断指令
INT3,当执行发现是INT3的时候,操作系统会发一个信号SIGTRAP给被调试的进程
这时候我们执行run
这时候操作系统发送给被调试进程的所有信号被gdb进程接管了。
gdb接收这个信号,发现这个当前汇编代码执行到的行数,然后去断点链表里面找,发现有当前行数的代码- 将之前替换成
INT3的地方替换成断点链表里面的原来的代码 - 把PC指针回退一步重新设置到断点行
- 等待用户的调试指令
你怎么定位程序cpu使用率高的问题
- 第一步使用
top指令,查看cpu的占用情况,查找是哪一个进程占用的cpu资源比较多 - 接下来就是定位这个进程里面的哪一个线程占用的资源比较多
top -H -p 可以查看
ps aux 也可以
-
pstree可以查看线程树 -
这时候我们就知道是哪一个线程造成了
cpu资源占用率较高的线程- 这时候就需要我们取查看线程的在做什么,这时候我们可以看看线程的堆栈
pstack进程号- 也可以用
strace来进行线程追踪的系统调用
pstack是gstack的软连接面试基于gdb封装的脚本
内存泄露
内存泄露检测工具valgrind
valgrind是一个强大的工具,最常用的功能是用它来检测内存泄漏和非法内存的使用。要想让valgrind报告的更加细致,请使用-g进行编译。
基本命令如下:
$ valgrind --tool=memcheck --leak-check=yes program
可以检测如下问题:
- 如果malloc/realloc/calloc和free的数量不同,则会报告如下的内容。
==3375== HEAP SUMMARY:
==3375== in use at exit: 128 bytes in 1 blocks
==3375== total heap usage: 4,900 allocs, 4,899 frees, 29,477,380 bytes allocated
- 如果有第一个问题,则会报告哪里申请的内存没有进行释放:
==3375== 128 bytes in 1 blocks are definitely lost in loss record 1 of 1
==3375== at 0x4C2AC3D: dd (d.c:299)
==3375== by 0x50C44F2: cc (c.c:112)
==3375== by 0x5211824: bb (b.c:526)
==3375== by 0x518643B: aa (a.c:398)
==3375== by 0x400EB3: main (main.c:37)
如上表示在文件d.c的299行,有申请内存,没有进行释放。
- 使用未初始化的变量:
==3375== Conditional jump or move depends on uninitialised value(s)
==3375== at 0x5121568: bb (b.c:1035)
==3375== by 0x511DE92: aa (a.c:60)
==3375== by 0x400FB3: main (main.c:64)
如上说明,在b.c文件的1035行,使用了未初始化的变量。
- 多次free的问题
==3375== Invalid free() / delete / delete[] / realloc()
==3375== at 0x4C2BD57: free (vg_replace_malloc.c:530)
==3375== by 0x4005AA: aa (a.c:9)
==3375== by 0x4005BA: main (main.c:14)
如上表示,在a.c文件的9行,进行了第2次的free调用。同时也会有如下的提示,表明申请与释放的次数不同。
==3375== HEAP SUMMARY:
==3375== in use at exit: 0 bytes in 0 blocks
==3375== total heap usage: 1 allocs, 2 frees, 4 bytes allocated
- 非法内存操作:
==3375== Invalid write of size 4
==3375== at 0x40059B: aa (a.c:8)
==3375== by 0x4005BC: main (main.c:14)
==3375== Address 0x51fc044 is 0 bytes after a block of size 4 alloc'd
==3375== at 0x4C2AC3D: malloc (vg_replace_malloc.c:299)
==3375== by 0x40058E: aa (a.c:7)
==3375== by 0x4005BC: main (main.c:14)
如上表示,使用malloc申请了4个字节的内存,但在a.c的第8行,对第4(从0开始计数)个字节进行了写操作。
valgrind主要检测的是动态内存相关的错误。当然valgrind也只是个工具。应该在平时写代码时组织好代码。
另外这个是trace所以要从后往前看
kill某个有名称的进程
kill -9 进程名
9就是SIGCHLD信号
voliate
其实这个参数主要是防止编译器优化的;
比如在硬件buff里面写数据
BYTE[4]=0x22;
BYTE[4]=0x25;
BYTE[4]=0x42;
BYTE[4]=0xa2;
如果没有加valiate编译器就会优化只保留最后一条
最硬件来说这四条命令是四个操作
但是编译器直接优化的只剩下最后一个操作了,这个就达不到我们的预期效果
voliate的第二个用法是在多线程的环境下的,也就是保证变量的可见性
适用于多个线程都要用到某一个变量同时该变量的值被更改时
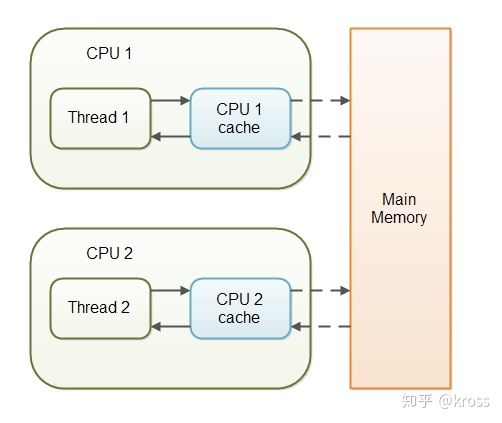
当一个多线程程序执行在一个多核心的机器上时,就会出现真正的并行情况,每个线程都独立的运行在一个CPU上,每个CPU都有属于自己独立的周边缓存。
那么此时,一个变量被两个线程操作,从内存复制到CPU缓存时,就可能出现两份了,这个时候就会出现问题,比如说简单的自增操作,就会变成,你加你的,我加我的,这样运行的效果就会偏离预期。线程1在CPU1上只看得见自己的缓存变量,线程2在CPU2上,也只看得见自己的缓存变量,它们都认为这是正确的、唯一的变量。这样也就导致程序运行结果偏离了预期。
volatile关键字就是用来处理这种可见性的问题。
当一个变量被标记为volatile的时候,这个变量将被放在主存里面,而不是CPU的缓存里面。当这个变量被读取的时候,是从主存读取,当这个变量被写入的时候,是写入到主存。
所以其实被volatile修饰变量访问效率要低一些
栈的效率为什么比堆要高
因为栈是机器系统提供的数据结构,计算机底层会对栈提供支持,分配专门的寄存器存放栈的地址,压栈,出栈都有专门的指令取执行,所以栈的效率要高于堆
另外的话,我们在堆里面分配内存机制是复杂的,它会根据一定的算法(最佳适应,最坏适应,邻近适应,首次适应),这时候如果有足够的大小才进行申请资源
总结就是
- 有寄存器对栈直接寻址(
ESP,EBP),而堆的访问只能通过页表间接寻址 - 栈中的数据命中率高(局部性原理)
- 栈是编译的时候已经知道大小,运行的时候系统自动的分配空间,而堆是动态分配,所以栈的速度要快
- 栈是先进后出的队列结构,比起堆里面的数据结构要简单一点,
- 栈中内存空间的分配有先进先出而堆中有复杂的空间分配算法,首次适应算法,最优适应算法,邻近适应算法
为什么构造函数不可以被继承
- 就算构造函数被继承了,那么名字也不一样,也不可能成为子类的构造函数,当然也不可能成为普通的成员函数
- 如果继承了,那么父类的变量初始化子类也要干,这个时候父类私有的子类看不见也没办法去进行构造。这时候的解决方法就是,在子类的构造函数里面调用父类的构造函数


















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









