




 本文涵盖了MySQL的基础理论,如SQL语言组成部分、数据库范式、MySQL架构和存储引擎的作用。讨论了SQL查询执行流程、数据格式与关键字的差异,强调了事务的ACID特性、隔离级别以及锁的概念。还深入讲解了存储引擎MyISAM和InnoDB的区别,以及索引的类型和作用。此外,提到了性能优化、日志文件和高可用性策略。
本文涵盖了MySQL的基础理论,如SQL语言组成部分、数据库范式、MySQL架构和存储引擎的作用。讨论了SQL查询执行流程、数据格式与关键字的差异,强调了事务的ACID特性、隔离级别以及锁的概念。还深入讲解了存储引擎MyISAM和InnoDB的区别,以及索引的类型和作用。此外,提到了性能优化、日志文件和高可用性策略。
本文目录如下:
精通MySQL — 基础 MySQL 知识
一、基础理论
SQL语言包括哪几部分?每部分都有哪些操作关键字?
数据库的三大范式是什么?
第一范式:表的每一列都 不可分割。第二范式:要求实体的属性 完全依赖 于 主关键字,即不存在 部分依赖。第三范式:消除 非主键 之间的 传递依赖 关系,即不存在 传递依赖。
说说 MySQL 的基础架构?存储引擎有什么作用?
MySQL 基础架构包含三部分:客户端、Server层、存储引擎层。
Server 层:负责 连接管理、权限认证 等操作;将 API请求 转换为 存储引擎 可以理解的操作。存储引擎层:位于最底层,存储引擎 负责管理 数据文件、索引文件、数据读写操作。
⼀条 SQL 查询语句 的 执行流程?
- 1.先由
Server 层检查该语句是否有 执行权限 ,没权限则返回 错误信息。- 2.有权限则由 分析器 进行 语法分析 ,判断 sql 语句 是否有 语法错误。
- 3.若没有语法错误,则 优化查询语句,然后交给
存储引擎层进行处理 ,返回 执行结果。
什么是视图?为什么要使用视图?
视图是一个虚表,只存放 定义,而不存放对应的数据。- 视图能够 简化 操作, 可以更清晰的表达查询。
二、数据格式 & 关键字
2.1 MySQL中常用的 数据类型 有哪些?
2.1.1 数值列类型
| 列类型 | 列类型介绍 | 列类型大小 |
|---|---|---|
tinyint | 十分小的数据 | 1个字节 |
smallint | 较小的数据 | 2个字节 |
int | 标准的整数 | 4个字节 (常用) |
bigint | 较大的数据 | 8个字节 |
float | 浮点数 | 4个字节 |
double | 浮点数 | 8个字节 |
decimal | 字符串形式的浮点数 | 在 金融计算 的时候,一般是使用decimal |
2.1.2 字符串类型
| 列类型 | 列类型介绍 | 列类型大小 |
|---|---|---|
char | 字符串固定大小 | 0~255 |
varchar | 可变字符串,常用的变量 String | 0~65535 |
tinytext | 微型文本 | 2^8-1 |
text | 文本串,用于保存大的文本 | 2^16-1 |
2.1.3 时间日期列类型
| 列类型 | 列类型规范 | 列类型介绍 |
|---|---|---|
date | YYYY-MM-DD | 日期格式 |
time | HH:mm:ss | 时间格式 |
datetime | YYYY-MM-DD HH:mm:ss | 最常用的时间格式 |
timestamp | 时间戳,1970.1.1到现在的毫秒数 | 也较为常用 |
MySQL中 char 和 varchar 的区别是什么?
char(n):固定长度,长度不够的部分用空格补充;适用场景:存储 用户ID 等长度固定的字段。varchar(n):可变长度。
总结:从 空间 上考虑 varcahr 比较合适;从 效率 上考虑 char 比较合适。
MySQL里记录 货币 用什么字段类型好?
- 在 MySQL 中,金额用
DECIMAL类型。DECIMAL类型的值作为 字符串 存储,⽽不是作为 二进制浮点数 存储,和 Java 中的 BigDecimal 类似。
blob 和 text 有什么区别?
blob用于存储二进制数据(字节字符串),主要用于存储 图片 等 非文本数据。text用于存储字符串(字符字符串),主要用于存储 文章 等 文本数据。
MySQL 中 Exists 和 IN 有什么区别?
IN则用于判断一个值是否在指定的值列表中。Exists用于判断表中 是否存在记录,即使记录为空也可以。Exists 更高效。- 注:MySQL 会把 IN 的查询语句改成 Exists 再去执行。
# 下面两句话等价 SELECT * FROM table_name WHERE column_name IN ('value1', 'value2'); SELECT * FROM table_name WHERE EXISTS (SELECT * FROM table_name WHERE column_name = 'value1' OR column_name = 'value2');
UNION 与 UNION ALL 的区别?
UNION:会合并 重复的记录行UNION ALL:不会合并 重复的记录行- 从效率上说:UNION ALL 要⽐ UNION 快很多,因为 不需要合并数据。
count(*) 与 count(列名) 的区别?
从 执行结果 来说:
count(*)不会 过滤空值。count(列名)会 过滤空值。
从 执行效率 来说:
- 如果 列为主键,
count(列名)效率优于count(*)- 如果 列不为主键,
count(*)效率优于count(列名)count(1)=count(*)
delete、truncate 和 drop 的区别?
delete:根据条件 删除行数据truncate:删除全表数据,保留表结构drop:删除全表数据,删除表结构注:执行速度一般来说:drop > truncate > delete
三、事务【重要】
数据库 事务 的特性 (ACID)?
事务是一个不可分割的 操作序列,也是数据库 并发控制 的基本单位。事务 的四大特性:
原子性: 事务 要么全部 执行成功,要么全部 不执行。一致性: 事务 前后 数据的完整性 必须 保持一致。
【举例:转账前后,两人的总金额 一致】隔离性: 事务 之间 互不干扰。持久性: 事务 一旦提交,它对数据库的改变就应该是 永久性的。
注:分布式 的 CAP 原则:一致性、可用性、分区容错性。
事务有几种 隔离级别?
| 级别 | 名字 | 含义 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读取未提交 | 可读取其它事务未提交的结果 | √ | √ | √ | |
| 2 | 读取已提交 | 只能读到其他事务已经提交的修改 | × | √ | √ | Oracle |
| 3 | 可重复读 | 同一条件的查询返回的结果是一样的 | × | × | √ | MySQL |
| 4 | 可串行化 | / | × | × | × |
[了解] 事务有几种 传播级别?
MySQL — 事务的传播级别有什么作用?有哪些事务的传播级别?
| 传播级别 | 描述 | 优点 |
|---|---|---|
加入当前事务 (默认级别) | 如果已经存在一个事务,就 加入当前事务 | 确保了 一组操作 要么 全部成功,要么 全部回滚,保持了 一致性 |
挂起当前事务 | 如果已经存在一个事务,就 挂起当前事务 | 子事务 不会受到 外部事务 的影响,可以 独立提交 或 回滚 |
嵌套创建事务 | 如果已经存在一个事务,就 在当前事务中嵌套创建一个事务 | 可以 独立提交 或 回滚,但只有在 主事务提交 时才会被 永久保存 |
什么是脏读?不可重复读?幻读?
脏读:事务A 读取了 事务B 更新的数据,然后 事务B 回滚操作,那么 事务A 读取到的数据是 脏数据。不可重复读:事务A 多次读取同一数据,事务B 在 事务A 读取过程中,更新了数据,导致 事务A 多次读取同一数据 结果不一致。幻读:当 事务A 读取某个范围内的记录时,事务B 又在该范围内插入了新的记录,当 事务A 再次读取该范围的记录时,会产生 幻行。
总结:
- 脏读 是因为
事务回滚。- 不可重复读 是因为
修改数据。- 幻读 是因为
新增或删除数据。
什么是 MVCC?
MVCC是一种 并发控制机制,它可以提高数据库的 并发性。MVCC允许多个事务 同时读写数据库,同时保持数据的 一致性 和 隔离性。MVCC通过 undo log 和 版本链 实现。
什么是间隙锁 | 幻读 是如何解决的?
InnDB 使用
间隙锁来解决幻读问题:
- 对于 键值 在 范围条件内 但 不存在 的 数据,叫做
间隙(GAP)。- 使用 范围条件 查询时,InnDB 会对
间隙数据进行 加锁。
四、存储引擎【重要】
存储引擎:MyISAM 和 InnoDB 的区别?
InnoDB:支持事务,支持行级锁。支持崩溃恢复。MyISAM:不支持事务,支持表级锁。不支持崩溃恢复。
如何选择 数据引擎?
默认使用
InnoDB即可。
InnoDB:适合并发读写或增删改频繁的场景,因为 InnoDB 支持 事务 和 行锁。MyISAM:适合查询频繁的场景。
InnoDB 和 MyISAM 的索引结构有什么区别?
InnoDB中的主键索引的 叶子节点 存储的是实际数据,也就是聚簇索引。MyISAM中的主键索引的 叶子节点 存储的是数据地址。就是 普通的主键索引 。- 总结:
InnoDB和MyISAM的 索引结构 主要区别在于主键索引,除了 主键索引 之外都是非聚簇索引。
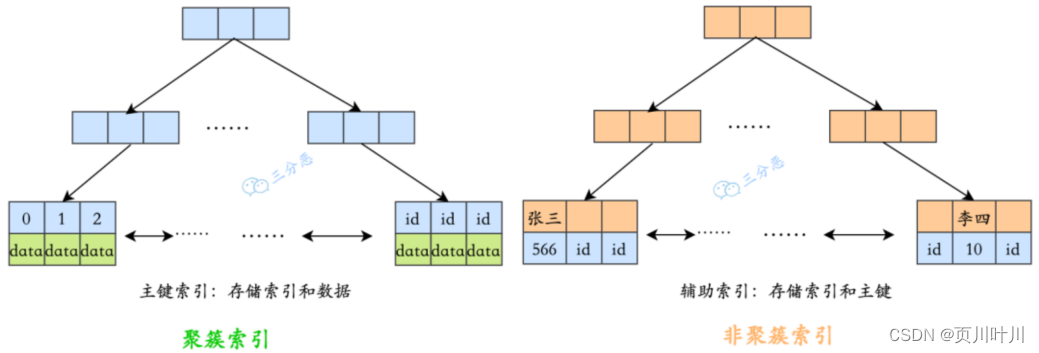
聚簇索引 与 非聚簇索引的区别?
聚簇索引:叶子节点 就是实际数据。非聚簇索引: 叶子节点 存储的是 主键键值 ,一次查询 后需要根据 主键键值 在 主键索引 上进行回表查询- ⼀个表中只能有⼀个
聚簇索引,但是可以有多个非聚簇索引。
注:
聚簇索引决定了数据的 物理存储顺序,因此在查询中可以直接提供 实际数据。
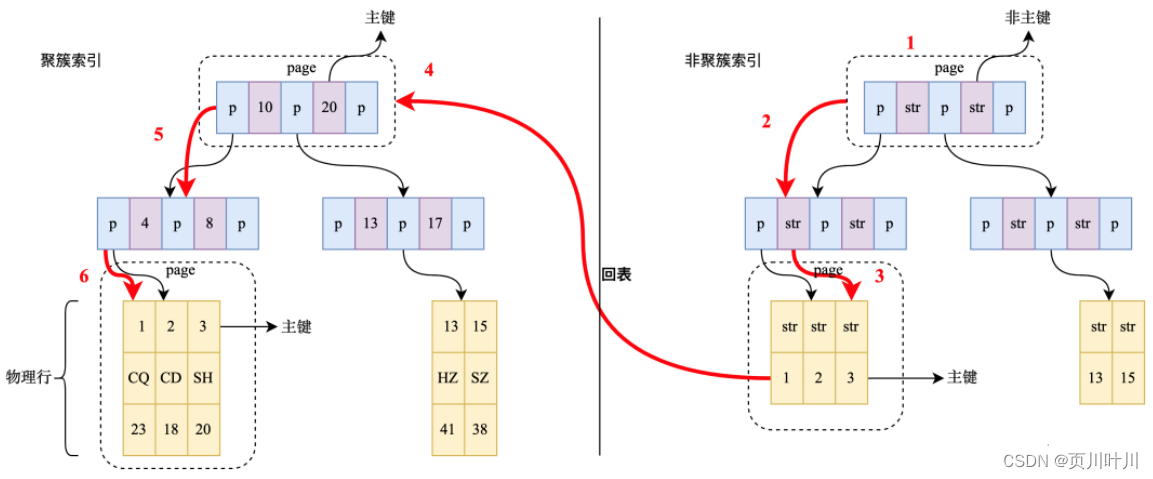
谈一谈 MySQL 中的回表?
在 MyISAM 存储引擎 里,先通过 非聚簇索引 找到 主键索引 的 键值,再通过 主键索引 查询 数据,它比基于 主键索引 的查询多扫描了⼀棵 索引树,这个过程就叫
回表。
- 例如:
select * from user where name = '张三';
五、索引【重要】
什么是索引?
索引是数据表中的 一列或多列数据。可以用来 加快查询速度。- 创建索引 会生成相应的
索引文件,查询时则不需要 遍历整张表。
常用的 索引 有哪几种类型?
主键索引:用于确定每一条记录的 唯一标识符。唯一索引:确保表中的 某个列的值 是唯一的。普通索引:根据 单个列 的值来查询数据。组合索引:根据 多个列 的值来查询数据。
主键索引 与 唯一索引的区别?
- 一个表只能有一个
主键索引,一个表能创建多个唯一索引。- 主键索引 不能为 null,唯一索引 可以为 null。
为什么使用 索引 会加快查询?
- 数据库 在执行一条 SQL语句 的时候,默认是根据 搜索条件 进行 全表扫描。
- 添加 索引 之后,MySQL 会生成⼀个
索引文件,查询数据时通过 索引文件 查找,大幅减少 扫描行数,从而提高了 查询效率。
索引 有什么缺点?
降低了数据写入的效率:增删改操作 要更新对应的 索引文件。索引占物理空间
创建索引的 原则 有哪些?
创建索引的情况:
查询频率高 的 字段 创建 索引- 经常
排序(order by) 的 字段 创建 索引- 经常
分组(group by) 的 字段 创建 索引- 一般情况尽量创建
唯一索引- 高并发 情况尽量创建
组合索引【参考 最左匹配原则】
不创建索引的情况:
- 频繁
更新的字段 不适合创建索引- 频繁
增删改的表不适合创建索引
创建了A, B 组合索引,使用 B 能否索引
- 在当 A 的值确定的情况下,B 的值也是有序的。即在 A 确定时能使用 B 索引。
- 注:
组合索引遵循最左匹配原则。
索引什么时候会失效?
like以%或者_开头的时候- 对 索引 列进行
计算或使用函数的时候
MySQL 索引用的什么数据结构 (B+树)?
MySQL 的默认 存储引擎 是
InnoDB,它采用的是B+树结构的索引 (聚簇索引)。
B+树中 非叶子节点 存储 多个索引 和 多个分支,一般情况下 3次比较 就能查询到数据。B+树中只有 叶子节点 才会 存储数据,非叶子节点 只存储 键值。- 叶子节点 之间使用 双向指针 连接,形成了⼀个
双向有序链表。
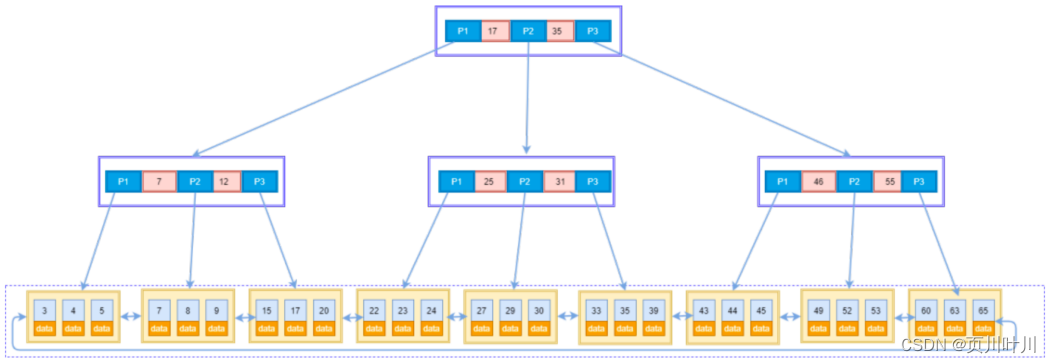
B+树 相比于 B树 有什么优点?
B+树中只有 叶子节点 才会 存储数据,非叶子节点 只存储 键值。叶子节点 之间使用双向指针连接,形成了⼀个双向有序链表。因此有如下优点:
范围查询和排序能力更强扫表能力更强
六、日志【重要】
MySQL 中有哪些日志文件?
bin log 日志:记录了所有 数据变更操作,包括 INSERT、UPDATE、DELETE 等操作。redo log 日志:用于 事物重做 操作。事务 执行前将事务操作记录到 undo Log 中。undo log 日志:用于 事务回滚 操作。事务 执行前将原始数据记录到 undo Log 中。
注:事务中断 进行 恢复 时,是要结合
redo log和bin log进行数据恢复的。
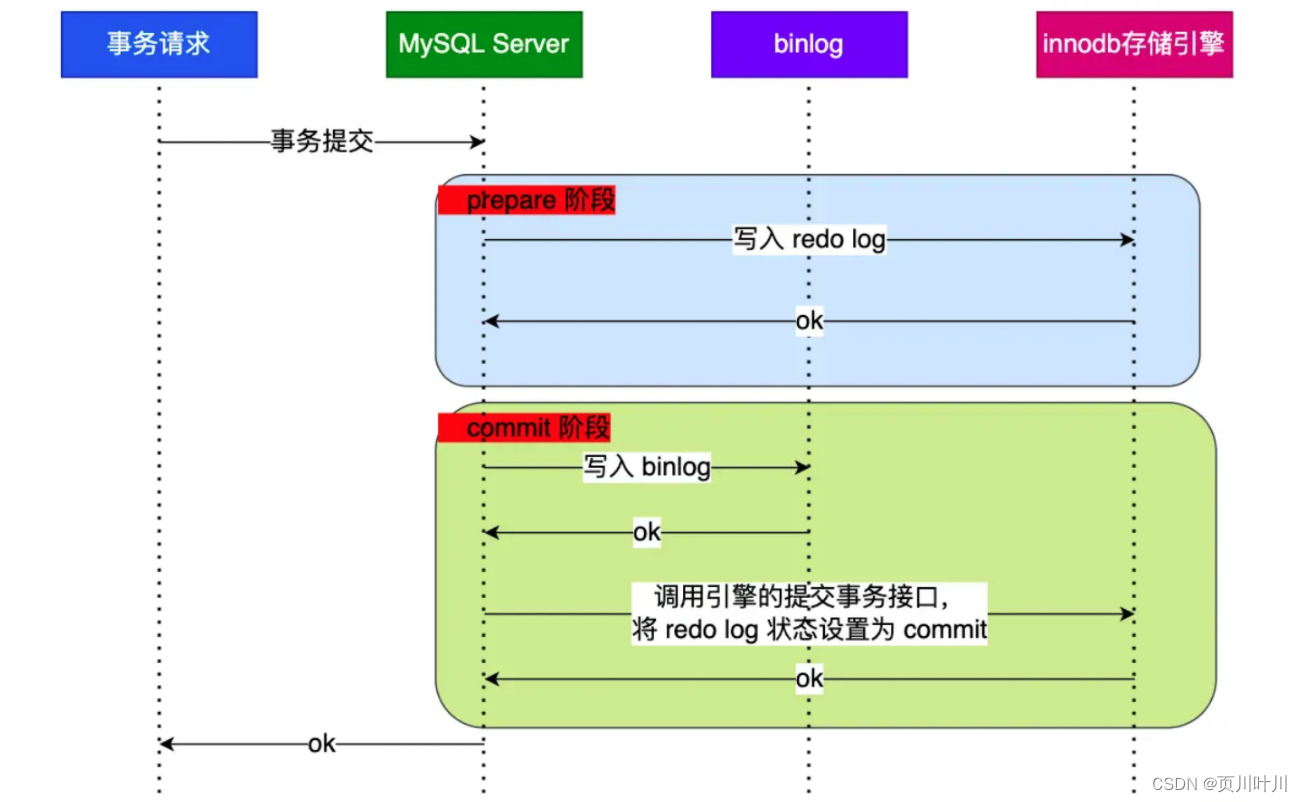
redo log 的 两次提交 的过程?
首先,redo log 写入 代表 事务已提交,bin log 写入 代表 数据已写入。
prepare 阶段:将更新提交到 redo log,然后 redo log 标记状态为 prepare。commit 阶段:将更新写入 磁盘,即写入 bin log,然后 redo log 标记状态为 commit。
redo log 为什么要分两次提交?
【MySQL】一文彻底搞懂 Redo-log 为什么要两阶段提交?
确保数据的持久性:保证 数据 最终会被写入 磁盘,两次提交 的过程也叫做 预写日志(WAL),可以保证 数据一致性 和 可恢复性。提高数据库的性能:将数据首先写入 内存 比直接写入 磁盘 要快得多。
七、锁
表锁 和 行锁 的区别?共享锁 和 排他锁 的区别?
行锁:会死锁。发生 锁冲突 的 概率小,并发度高。表锁:不会死锁。发生 锁冲突 的 概率高,并发量低。- 注:
FOR UPDATE和FOR SHARE都是行锁。
如果按照 兼容性,可分为两种:
共享锁:也叫 读锁,读锁 之间相互 不排斥。排它锁:也叫 写锁,写锁 排斥其他 写锁 和 读锁。- 注:
FOR UPDATE是排他锁;FOR SHARE都是共享锁。
MySQL 的 乐观锁 和 悲观锁 了解吗?
悲观锁:认为 并发访问 时一定会 发生冲突,因此 访问数据 前都会 上锁。
行锁、表锁、共享锁、排它锁都是悲观锁。
乐观锁: 认为 并发访问 时 不会发生冲突,只是在 修改数据 时 检测 数据 是否被修改 (CAS 算法)。
- 乐观锁 只能由 开发人员 在 程序 中实现。
七、高可用 & 性能【重要】
如何做 MySQL 的性能优化?
查询优化:避免使用select *。索引优化:根据索引创建原则合理地 添加索引。使用缓存:使用Redis缓存 查询结果,加快响应速度。分页优化:在数据量比较大,需要考虑分页。读写分离分库分表- 合适的存储引擎:选择正确的 存储引擎。
MySQL请求很慢,如何定位问题?
慢查询日志:查看 MySQL 的 慢查询日志,找出执行慢的 SQL语句。explain语句:使用 explain语句 来分析 慢SQL 的 执行计划。
MySQL 服务器 CPU 飙升的话,要怎么处理呢?
排查过程:
- 使用
top命令查看是不是MySQL 进程导致的。慢查询日志:查看 MySQL 的 慢查询日志,找出执行慢的 SQL语句。explain语句:使用 explain语句 来分析 慢SQL 的 执行计划。
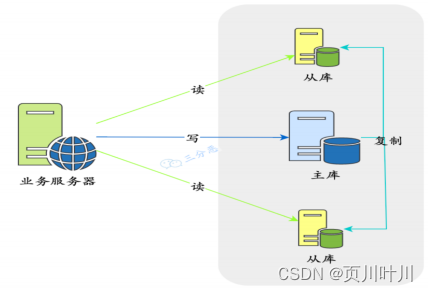
数据库 读写分离 了解吗?
读写分离的基本实现是:
- 1.数据库服务器 搭建
主从集群。(⼀主⼀从、⼀主多从 都可以)- 2.
主节点(master) 处理 写操作,从节点(slave) 处理 读操作。- 3.主节点 通过
主从复制将 业务数据 同步到 从节点。
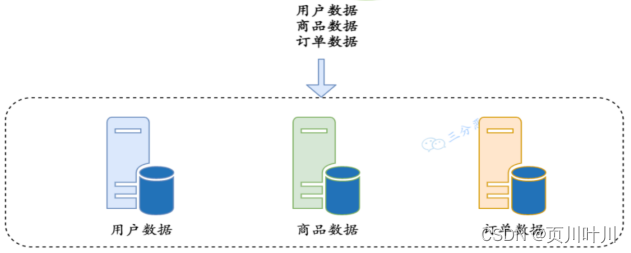
如何进行 分库?
垂直分库:以 表 为依据,按照 业务归属 不同,将 不同的表 拆分到不同的库中。
⽔平分库:以 字段 为依据,按照 ⼀定策略,将⼀个表中的 数据 拆分到多个库中。
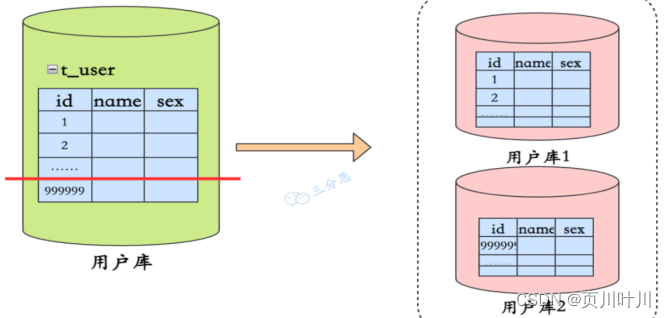
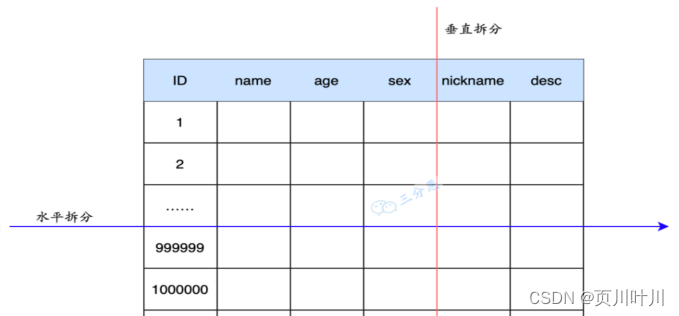
如何进行 分表?
- 水平分表:以 字段 为依据,按照⼀定策略,将⼀个表中的 数据 拆分到多个表中。
- 垂直分表:以 字段 为依据,按照 字段的活跃性,将表中 字段 拆到不同的表(主表 和 扩展表)中。
分库分表会带来什么问题呢?
事务的问题:分库之后无法使用 单机事务,必须使用 分布式事务 来解决。跨库 JOIN 问题:跨库了之后就无法进行 Join操作,只能在业务代码中进行关联。跨节点的 count, group by 以及 聚合函数 问题:只能在业务代码中实现。
八、其他
什么是数据库连接池? 为什么需要数据库连接池呢?
数据库连接池 原理:在 内部对象池 中,维护一定数量的 数据库连接,并对外暴露 数据库连接 的获取和返回方法。
提高响应速度:高并发场景下大量 创建连接程 很费时, 使用连接池可以 提高响应速度。统一的连接管理,避免数据库连接泄漏
如何防止 SQL注入?
权限区分:普通用户 与 系统管理员 的权限要 严格区分。使用合适的ORM框架:好的 ORM框架 可以很大程度防止 SQL注入。推荐使用:MyBatis-Plus。对用户的输入进行验证
精通MySQL — 进阶 MySQL 知识
百万级别以上 的数据如何删除?
当我们对数据进行
增加、修改、删除操作时, 会产生额外的对索引文件的操作, 这些操作会降低 执行效率。所以 删除数据的速度 和 索引数量 是成正比的。
因此删除 百万级别数据 的步骤如下:
- 先 删除索引。
- 然后 删除⽆⽤数据。
- 删除完成后 重新创建索引 (速度很快)。
百万级别以上 大表如何添加字段?
当表中数据量到达 百万级别以上 时,加一个字段就没那么简单,因为可能会 长时间锁表。
大表添加字段,通常有这些做法:
通过中间表转换:创建⼀个 临时的新表,把 旧表的结构 完全复制过去,添加字段,再把 旧表数据 复制过去,删除旧表,新表命名为旧表的名称,这种方式可能会 丢失数据。先在从库添加字段,然后进行主从切换。
100万数据的 A表 和10万数据的 B表进行Join操作,哪个表在前?
- 在进行
表连接 (Join)操作时,通常将较小的表放在前面 效率更高。- 数据库 进行 表连接 时,会从 左表 中选择一行记录,然后在 右表 中查找 匹配的记录。
- 原理:减少 外层循环次数。
商品超卖 的 解决方案?
最优的解决方案:
- 使用 Redis队列 来实现。将要促销的 商品数量 以 队列 的方式存入 Redis,每当用户抢到一件促销商品则从 队列 中 删除一个数据,确保商品 不会超卖。这个方法 效率极高。
// 使用 Redis队列 实现,用户过来直接入队列,然后再将操作更新到数据库
// 最佳体验(redis pconnect 9.481s, 无丢失, 无框架)
public void push() {
// 入队列
jedis.lpush(QUEUE, "1");
}
// 脚本调用pop方法
public void pop() {
String key;
while ((key = jedis.rpop(QUEUE)) != null) {
Shop shop = getShopById(1); // Assuming shop with ID 1
if (shop.getNumber() > 0) {
DB.updateShopNumber(shop.getId(), shop.getNumber() - 1);
}
}
}
批量往数据库导入1000万条数据方法?
使用
批处理,减少 数据库连接次数,同时将 单条插入语句 改为 一次插入多条数据 以提高效率。
- 总结:批处理:一次发送 多条SQL语句
+一条 SQL语句 插入 多条数据


















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











