





SE-Bridge:具有一致布朗桥的语音增强
摘要
我们提出了SE桥,这是一种新的语音增强(SE)方法。在最近将扩散模型应用于语音增强之后,我们可以通过求解随机微分方程(SDE)来实现语音增强。每个SDE对应于概率流常微分方程(PF-ODE),PF-ODE解的轨迹由不同时刻的语音状态组成。我们的方法基于一致性模型,该模型确保相同PF ODE轨迹上的任何语音状态都对应于相同的初始状态。通过集成布朗桥过程,该模型能够在没有对抗性训练的情况下生成高清晰度的语音样本。这是首次尝试将一致性模型应用于SE任务,在几个指标上实现了最先进的结果,同时与基于扩散的基线相比,节省了15倍的采样时间。我们在多个数据集上的实验证明了SE Bridge在SE中的有效性。
I.简介
语音增强旨在通过将干净语音与噪声语音分离来提高语音信号的质量,从而提高听觉可懂度或促进ASR和SV等下游任务。SE方法可分为生成增强方法(GEM)和判别增强方法(DEM)。由于GEM直接学习干净语音的分布,而不是噪声和干净语音之间的映射,因此它们可以更好地推广到不同的噪声[1]。这些方法允许模型有效地增强有噪声的语音,即使数据集不包含足够类型的噪声。GEM的常见技术包括基于GAN[2]-[6]、VAE[7]-[12]和归一化流[13]、[14]的技术。最近,基于扩散的方法得到了极大的关注。基于扩散模型的SE方法实现了最先进的性能,并在听觉测试中提高了语音清晰度[15]。然而,由于需要对扩散模型进行多步去噪,使得它们无法满足语音增强对低延迟的要求。在这封信中,我们建议将一致性模型应用于SE,因为一致性模型可以在一步中获得高质量的样本,这可以有效地满足SE对低延迟的需求。同时,我们使用布朗桥随机过程将样本的状态从干净语音的分布逐渐改变为有噪声语音的分布。与[16]将布朗桥应用于扩散模型的方法相比,我们发现与方差爆炸随机微分方程(VE-SDE)的组合可能是不必要的,并且直接使用布朗桥过程能够获得类似甚至更好的增强结果。此外,我们提出的方法可以有效地避免SDE方程扩散系数中超参数的调整。一致性模型实现了单步增强,从而避免了对基于扩散的模型中使用的采样过程的逐步调度所需的经验设置的需要。此外,SE模型可能在下游任务中表现出过度抑制[17]。为了验证我们提出的方法对下游任务的支持,我们还通过实验证明了下游任务模型性能的有效增强。
二、 方法

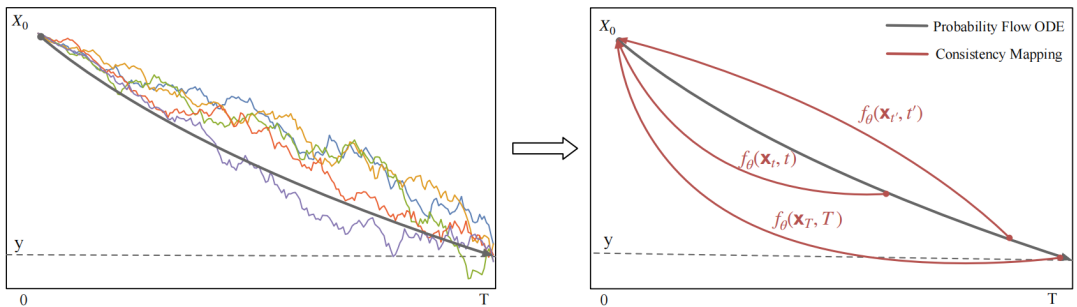
图1。拟建SEBridge概述。左侧图中间的粗黑线表示PF-ODE的轨迹。通过平滑地添加噪声,我们将干净的语音x0转换为有噪声的语音y。左侧面板中剩余的彩色线表示具有固定末端的五个模拟布朗桥随机过程。右边是自一致性的演示,其中相同PF-ODE轨迹上的过程状态对应于相同的初始状态。



三、 实验
在本节中,我们简要介绍了实验的数据集、评估指标和相关配置。我们的实验主要分为两部分,第一部分是SE的实验,其中包括SE桥与其他GEM和DEM的比较。第二部分是下游任务的实验。此外,SE Bridge的源代码将在网上找到1。
A.基线
为了评估我们的方法的有效性,我们与多个典型的语音增强模型进行了实验比较,包括六个GEM和两个DEM。在这些模型中,SGMSE+[15]作为我们的主要基线。SGMSE+建立在SGMSE[1]的基础上,并用NCSN++[21]取代了原始的深层复杂U-Net。SGMSE+在生成模型中提供了卓越的性能,与最先进的判别模型性能相当,并具有更好的泛化能力。我们选择SGMSE+作为我们的基线,以展示我们提出的基于一致性模型的语音增强方法相对于最佳扩散模型方法的优势。
B.数据集
a) SE:
我们使用了与基线[15]相同的数据集:WSJ0-CHiME3和VoiceBank DEMAND[22]-[24]。对于WSJ0-CHiME3,我们采用了[15]中概述的噪声混合方法。VoiceBank DEMAND数据集,一个广泛认可的单通道语音增强基准数据集。在这项研究中,我们对原始波形从48 kHz下采样到16 kHz。
b) ASR和SV:
为了在两个下游任务上评估我们提出的方法,我们通过在Librispeech[25]测试集中向干净语音添加噪声来创建测试集。我们使用CHiME3数据集来生成噪声。添加噪声的过程与WSJ0-CHiME3数据集中使用的过程类似。具体而言,我们从CHiME3噪声集中随机选择一个噪声,并将信号均匀采样到0-20dB的SNR。然后,我们将噪声和语音混合以创建测试集,我们称之为Librispeech-CHiME3测试集。
C.绩效指标
我们在三项任务中使用了最常用的评估指标。
a) SE:
我们使用语音质量感知评估(PESQ)作为我们的SE指标,PESQ的得分从1到4.5不等,这是单通道语音增强任务最常见的指标之一。除此之外,我们还使用了扩展短时目标清晰度(ESTOI,得分范围从0到1)、标度不变信噪比(SI-SDR),以dB为单位测量,值越大意味着增强性能越好。
b) ASR:
我们报告了单词错误率(WER),它是ASR中的一个标准度量,反映了ASR模型输出和基本事实转录之间的单词级编辑距离,其值越低,识别性能越好。
c) SV:
我们报告了等误率(EER),其目的是检测同一个人是否说出了两种不同的口语。值越低表示性能越好。
- 配置(Configuration )
a) SE:
我们使用的数据输入表示和DNN网络架构与[15]一致,后者使条件得分网络(NCSN++)结构支持复杂的频谱图。具体来说,我们在信道维度上组合输入数据的实部和虚部后,使用它们进入网络。我们在Nvidia 3090上训练了深度神经网络,使用Adam优化器,初始学习率为10-4,批量大小设置为8。此外,我们使用了梯度累积策略,每四个批次进行一次梯度更新。离散步骤的最大数量N设置为30,并且我们设置最小过程时间ε=0.001最大过程力矩T=0.999,以确保数值稳定。
b) ASR和SV:
两个GEM和两个DEM分别用于ASR和SV的下游任务。在数据集选择方面,SE Bridge和SGMSE+的训练数据为WSJ0-CHiME3,MetricGAN+和Conv TasNet的训练数据是VoiceBank DEMAND。他们的测试集都是Librispeech-CHiME3。我们对这四个模型进行了再训练,分别比较了语音增强前后测试集在两个下游任务中的性能。对于ASR和SV,我们使用语音大脑[30]工具包中的预训练模型。对于ASR模型,我们使用在LibriSpeech[25]上预先训练的Transformer[31]+TransformerLM模型。对于SV模型,我们使用在VoxCeleb[33]上预训练的ECAPA-TDNN嵌入模型[32]。
四、 结果
A.SE
a) 匹配条件下的结果:
SE Bridge和其他最近的GEM在WSJ0-CHIME3和VoiceBank DEMAND数据集上进行了训练,并在匹配的条件下进行了测试(在同一数据集上训练和测试)。表I显示,SE Bridge在两个数据集上的ESTOI和SI-SDR都取得了最好的结果。值得注意的是,我们的模型的SI-SDR在两个数据集上都比其他模型有了显著的改进。在PESQ方面,判别模型取得了最好的结果,MetricGAN+略优于SE Bridge。然而,MetricGAN+在MUSHRA[34]听力实验中表现不佳,随后的实验表明,它的泛化能力比SE Bridge差。
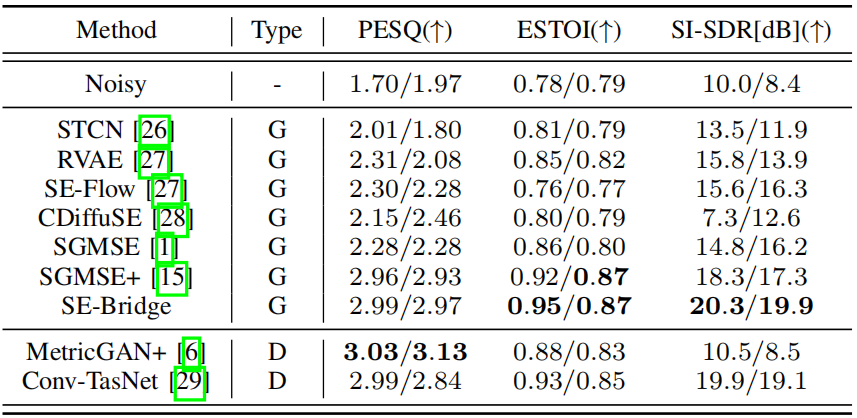
匹配条件下语音增强的实验结果。“/”之前的值表示WSJ0-CHIME3上的结果,“/”之后的值表示VOICEBANK需求上的结果。其中,STCN[26]和RVAE[27]使用WSJ0[22]和VOICEBANK[24]数据集进行无监督训练。
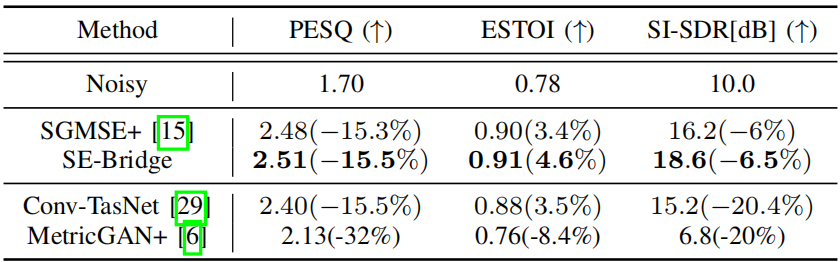
不匹配条件下的语音增强结果,括号中的数字表示不匹配条件和匹配条件下性能的相对变化。
b) 不匹配条件下的结果:
测试集和训练集之间的不匹配可以在一定程度上反映模型的泛化性能。表二报告了失配条件的结果。GEM和DEM的PESQ和SI SDR性能都有所下降,其中DEM显著下降,尤其是在SI SDR中,GEM明显占主导地位。这与生成模型直接学习数据分布的特性有关。我们的模型在三个指标上实现了最佳性能,可以认为已经学习了干净语音的先验分布。
c) RTF:
SGMSE+[15]具有与SE桥相同的网络大小,并且它被认为是最先进的基于扩散的语音增强方法。当SGMSE+[15]达到最佳性能时,我们使用其采样配置来计算其实时因子(RTF)。然后,与SE Bridge实现最佳性能时的RTF相比,我们的模型在SE性能优越的同时,RTF减少了15倍2。
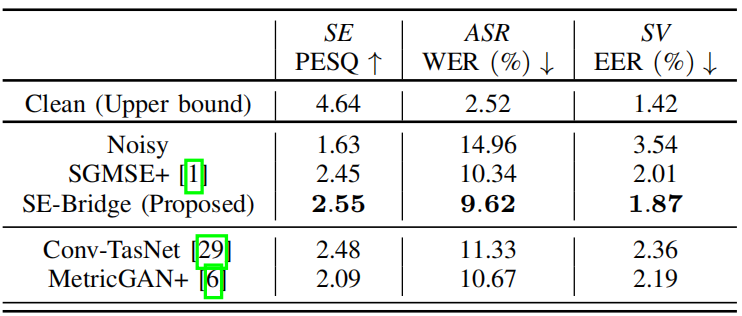
使用SE桥增强的LIBRISPEECH-CHIME3测试集的下游任务的实验结果。
B.ASR和SV
下游任务通常反映语音增强模型能否在提高语音可懂度的同时保留足够的语音信息。表III报告了下游任务的实验结果。所有四个模型都有效地支持两个下游任务,我们提出的模型的性能超过了其他模型。下游任务的性能与PESQ之间存在相关性,如在失配条件下,因此两种判别模型的性能也相对较差,这也可以反映生成语音增强方法在下游任务中的优势。
五、结论
在这封信中,我们使用布朗桥随机过程的一致性模型提出了一种新的语音增强范式。我们的方法简单,但非常有效。与基于扩散的方法相比,它不仅提高了噪声语音的可懂度,而且有效地降低了RTF。我们的实验结果表明,我们提出的方法优于基线,从而获得更好的语音可懂度和更好的下游任务性能。此外,我们提出的SE桥方法可以潜在地应用于其他任务,如相位恢复和图像去噪。总的来说,我们提出的方法为语音增强研究提供了一个新的方向,并为该领域的进一步探索开辟了机会。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









