





语义视听导航(2021)
摘要
最近关于视听导航的研究假设了一个不断发声的目标和限制了音频去指示目标的位置的作用。
我们引入了语义视听导航,其中环境中的对象发出与其语义一致的声音(如冲厕声、门吱吱声),并且声学事件是零星的或持续时间短的事件。
我们提出了一个基于transformer的模型来解决这个新的语义音频目标任务,结合了一个推断的目标描述符,该描述符可以捕获目标的空间和语义属性。
我们的模型的持久多模式记忆使其能够在声学事件停止后很长时间内达到目标。
为了支持这项新任务,我们还扩展了SoundSpace音频模拟,为Matterport3D中的一系列对象提供语义基础声音。我们的方法通过学习关联语义、声学和视觉线索,大大优于现有的视听导航方法。
研究内容
自主代理在连续的动作和感知循环中与其环境交互。代理需要智能地推理其可用的所有感官(视觉、听觉、本体感觉、触觉),以选择适当的动作顺序,以完成其任务。例如,未来的服务机器人可能需要为用户定位和取回物品,在洗碗机停止运行时清空洗碗机,或者在听到客人开始在前厅讲话时前往前厅。
对于此类应用,视觉导航的最新进展构建了使用以自我为中心的视觉旅行到陌生环境中的指定点[23,38,42,10],搜索特定对象[44,9,37,8],或探索和绘制新空间[35,34,13,10,15,10,36]的代理。有限的新工作进一步探索了扩展导航代理的感官套件,以包括听觉。特别是,AudioGoal挑战[11]要求代理使用音频作为关键方向和距离提示导航到发声目标(例如,铃声电话)[11、19、12]。虽然这是令人兴奋的第一步,但现有的视听导航工作有两个关键限制。
首先,先前的工作假设目标物体不断发出稳定的重复声音(例如,警报鸣叫、电话铃声)。虽然这很重要,但它对应于一组狭窄的目标;在现实场景中,对象可能仅短暂发出声音,也可能动态启动和停止!
其次,在现实3D环境模拟器中探索的当前模型中,发出声音的目标既没有视觉体现,也没有任何语义上下文。相反,目标声源任意放置在环境中,与场景和对象的语义无关。因此,音频的作用仅限于提供一个指示对象位置的声音信标。
鉴于这些限制,我们引入了一项新任务:语义视听导航。在此任务中,代理必须导航到(仅在特定时间段发出声音的)位于环境中的上下文对象。语义视听导航扩展了现实世界场景的集合,以包括在环境中语义基础上的短时声学事件。它提供了新的学习挑战。
代理不仅必须学习如何将声音与视觉对象联系起来,还必须学习如何利用对象的语义先验(以及任何声学线索)来推断对象可能在场景中的位置。例如,听到洗碗机停止运转并发出“循环结束”的钟声,应该会提示要搜索的视觉对象以及找到它的可能路径,即朝向厨房而不是卧室。
值得注意的是,在提出的任务中,代理没有获得有关目标的任何外部信息(例如要搜索的对象的位移向量或名称)。因此,代理必须学会利用(在搜索声源时可能随时停止的)零星声学线索,推断即使在声音沉默后,视觉对象也可能发出什么声音。参见图1。
为了解决语义AudioGoal,我们引入了一个深度强化学习模型,学习对象外观和声音之间的关联。我们开发了一个目标描述符模块,该模块允许代理在看到目标对象之前根据接收到的声学线索假设目标属性(即位置和对象类别)。再加上一个transformer,它学习注意其记忆中先前的视觉和声学观察——以预测的目标描述符为条件——来导航到音频源。
此外,为了支持这一研究方向,我们为真实的扫描环境进行了视听模拟,以便将语义相关的声音附加到语义相关的对象上。我们在85个具有各种语义对象及其声音的大规模真实世界环境中评估了我们的模型。我们的方法在视听导航方面优于最先进的模型,SPL绝对提高了8.9%。
此外,我们的模型在处理目标发出的短声信号时具有很强的鲁棒性,并且与竞争对手相比,它更经常在声学观测结束后到达目标。此外,与基线模型相比,我们的模型在存在环境噪声(干扰音)的情况下保持了良好的性能。总的来说,这项工作显示了嵌入式代理通过与3D环境的交互来了解对象的外观和声音的潜力。
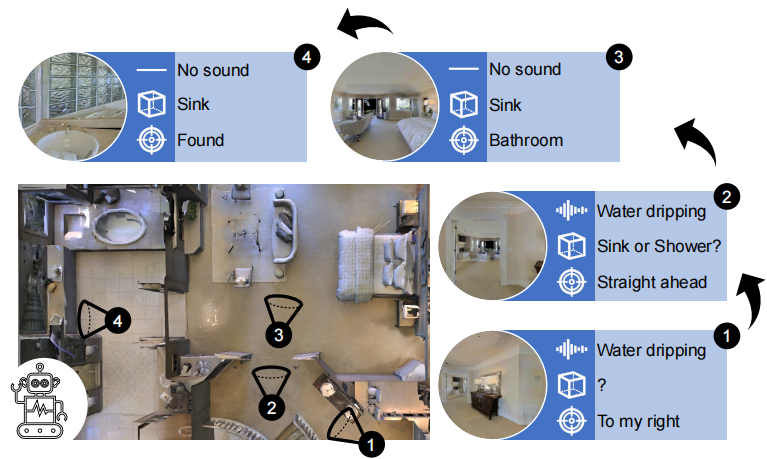
Figure 1: Semantic audio-visual navigation in 3D environments: an agent must navigate to a sounding object. Since the sound may stop while the agent searches for the object, the agent is incentivized to learn the association between how objects look and sound, and to build contextual models for where different semantic sounds are more likely to occur (e.g., water dripping in the bathroom).
图1:3D环境中的语义视听导航:代理必须导航到发声对象。由于声音可能会在代理搜索对象时停止,因此会激励代理学习对象外观和声音之间的关联,并为不同的语义声音更有可能出现的位置建立上下文模型(例如,浴室里的滴水)。
提出的方法&模型架构
我们提出了一种新的语义视听导航任务模型SAVi。SAVi使用持久多模态存储器(multimodal memory)和transformer模型,与基于RNN的架构(例如[11])或反应式架构(例如[19])不同,该模型可以直接关注与当前步骤有不同时间距离的观测(observations),以有效定位目标。
此外,我们的模型学习从显式描述符中的声学事件中捕获目标信息,并使用它来处理其记忆,从而使代理能够发现可能帮助其更快到达目标的任何空间和语义线索。
我们的方法有三个主要组成部分(图2):
- 观察编码器(Observation Encoder),将代理在每个步骤接收到的以自我为中心的视觉和声学观察映射到嵌入空间;
- 目标描述符网络(Goal Descriptor Network),其基于所述编码的观测值产生目标描述符;
- 策略网络(Policy Network),其给定编码的观测值和预测的目标描述符,提取描述符条件状态表示并输出动作分布。
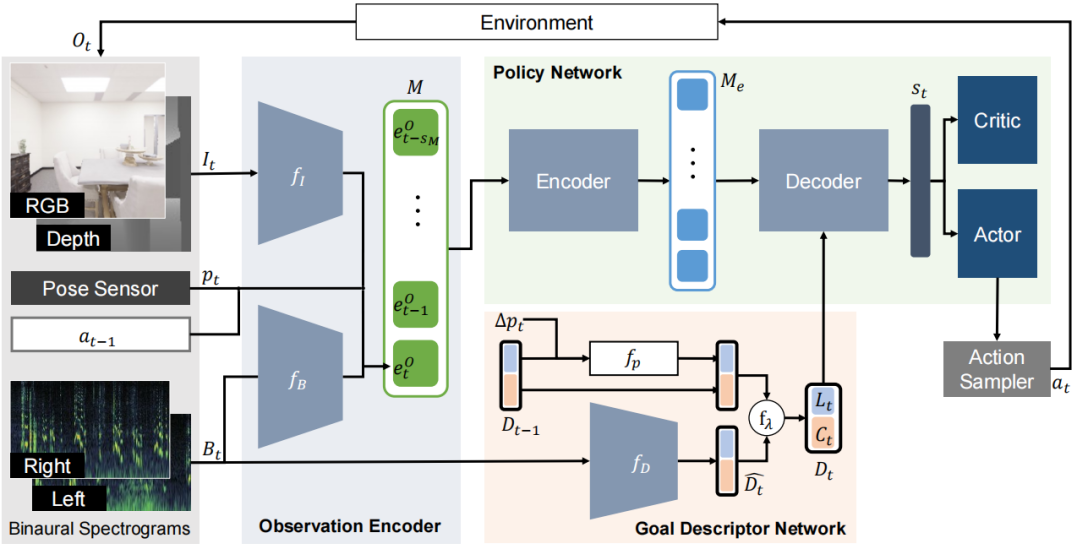
Figure 2: In our model, the agent first encodes input observations and stores their features in memory M. Then our goal descriptor network leverages the acoustic cues to dynamically infer and update a goal descriptor Dt of the target object, which contains both location Lt and object category Ct information about the goal. By conditioning the agent’s scene memory on the goal descriptor, the learned state representation st preserves information most relevant to the goal. Our transformer-based policy network attends to the encoded observations in M with self-attention to reason about the 3D environment seen so far, and it attends to Me with Dt to capture possible associations between the hypothesized goal and the visual and acoustic observations to predict the state st. Then, st is fed to an actor-critic network, which predicts the next action at. The agent receives its reward from the environment based on how close to the goal it moves and whether it succeeds in reaching it.
图2:在我们的模型中,代理首先对输入观测值进行编码,并将其特征存储在内存M中。
然后,我们的目标描述符网络利用声学线索动态推断和更新目标对象的目标描述符Dt ,其中包含目标的位置Lt 和对象类别Ct 信息。通过在目标描述符上调节代理的场景记忆,学习状态表示st 保留与目标最相关的信息。
我们基于transformer的策略网络(policy network)关注M中的编码观察(observations),有self-attention的M去推理到目前为止所看到的3D环境,它关注Me和Dt ,以捕捉假设的目标与视觉和声学观察之间的可能的联系,以预测状态st。
然后,st 被馈送到actor-critic network,该网络预测当前的下一个动作(action) at。代理根据其移动距离目标的距离以及是否成功达到目标,从环境中获得奖励。
观察编码器 Observation Encoder
 目标描述符网络 Goal Descriptor Network
目标描述符网络 Goal Descriptor Network

策略网络 Policy Network

训练 Training

数据集
我们介绍了语义视听导航的新任务。在这个任务中,代理需要在复杂的、未映射的环境中导航,以找到一个语义对象语义目标。与AudioGoal[11,19]不同,目标声音不需要是周期性的,持续时间可变,并且与有意义的语义对象相关(例如,门吱吱声与公寓的门相关)。这一设置代表了常见的现实世界事件,如上所述,为体验式学习带来了新的挑战。仅仅依靠音频感知来产生分步动作是不够的,因为音频事件相对较短。相反,代理需要对发声对象的类别进行推理,并使用视觉和听觉感知来预测其位置。
3D环境和模拟器。
与计算机视觉在模拟中对具体人工智能所做的工作的活跃主体一致,为了促进我们工作的再现性,我们依靠视觉和听觉逼真的模拟平台来模拟在复杂3D环境中移动的代理。我们使用SoundSpaces[11],它可以在副本[40]和Matterport3D[6]中为真实环境扫描实现任意声音的真实音频渲染。我们使用Matterport环境是因为其更大的规模和复杂性。SoundSpaces与Habitat兼容[38],允许在间距为1m的统一节点网格上的任何源和接收器(代理)位置对渲染任意声音。
语义声音数据收集。
我们在Matterport3D环境中使用ObjectGoal导航挑战[4]中定义的21个对象类别:椅子、桌子、图片、橱柜、坐垫、沙发、床、衣柜、植物、水槽、马桶、凳子、毛巾、电视监视器、淋浴、浴缸、柜台、壁炉、健身房设备、座椅和衣服。所有这些类别都具有在Matterport环境中直观显示的对象。
通过在Matterport对象的位置呈现特定于对象的声音,我们可以获得语义上有意义的和上下文相关的声音。例如,冲水声将与浴室中的厕所相关联,而噼啪声则与客厅或卧室中的壁炉相关联。
我们过滤掉导航图无法访问的对象实例。对于每个对象类别,train/val/test的对象实例数平均为303/46/80。
我们考虑两种类型的声音事件:物体发射和物体相关。物体发出的声音是由物体产生的,例如冲厕声,而与物体相关的声音则是由人与物体的互动引起的,例如食物在柜台上被切碎。
为了提供各种声音,我们搜索了一个公共数据库freesound. org。通过21个对象名称获得每个对象的长的无版权音频剪辑。我们将原始剪辑(平均长度81s)均匀地分割为train/val/测试剪辑。这些分割允许未听到声音的特征(即,训练期间未听到的波形)与训练集中的特征相关,同时仍保留自然变化。2从平均值为15s、偏差为9s的高斯分布中随机采样每集的声相位持续时间,并进行最小5s和最大500s的削波。如果采样的持续时间长于音频片段的长度,我们将重放该片段。有关示例,请参见补充视频。
实验
我们评估以下导航指标:
1)success rate:成功的episodes的比例;
2)通过反向路径长度加权的成功(SPL):通过遵守最短路径来衡量成功的标准度量[2];
3)通过动作的相反次数加权成功(SNA)[12]:这通过计算动作数而不是路径长度来惩罚碰撞和原地旋转;
4)平均距目标距离(DTG):episodes 结束时代理距目标的距离;
5)静默成功(SWS):当代理在声学事件结束后达到目标时,成功事件的分数。
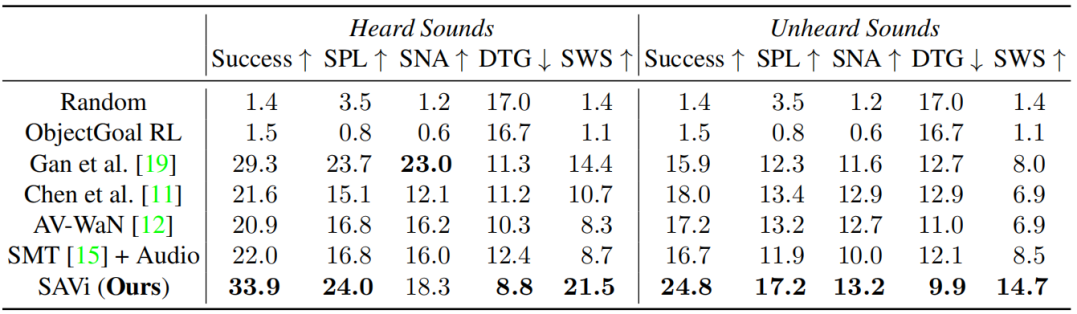
Table 1: Navigation performance on the SoundSpaces Matterport3D dataset [11]. Our SAVi model has higher success rates and follows a shorter trajectory (SPL) to the goal compared to the state-of-the-art. Equipped with its explicit goal descriptor and having learned semantically grounded object sounds from training environments, our model is able to reach the goal more efficiently—even after it stops sounding—at a significantly higher rate than the closest competitor (see the SWS metric).
表1:SoundSpaces Matterport3D数据集的导航性能[11]。与最新技术相比,我们的SAVi模型具有更高的成功率和更短的目标轨迹(SPL)。配备了明确的目标描述符,并从训练环境中学习了语义上固定的对象声音,我们的模型能够更有效地达到目标,即使它停止发声的速度明显高于最接近的竞争对手(参见SWS指标)。
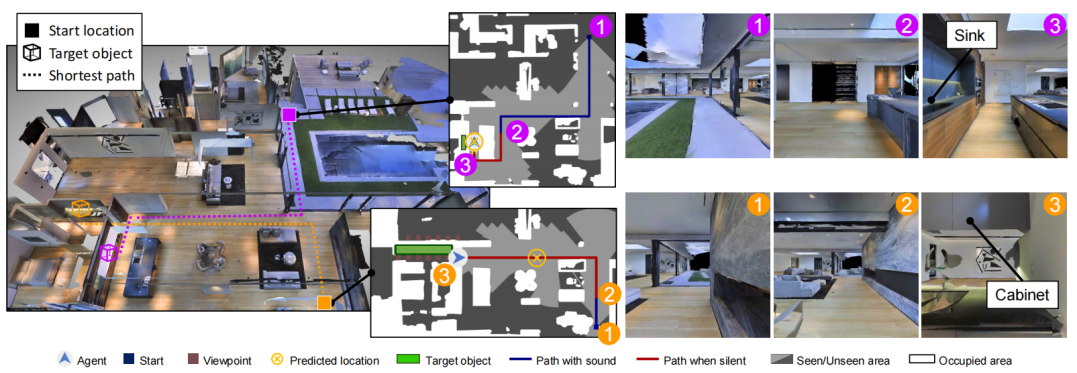
Figure 3: Example SAVi navigation trajectories. In the first episode (top/magenta) the agent hears a water dripping sound and in the second episode (bottom/orange) a sound of opening and closing a door. For each episode, we show three egocentric visual views (right) sampled from the agent’s trajectory at the start location 1, when the sound stops 2, and at the end location 3. In the top episode, the acoustic event lasts for two thirds of the trajectory and when the sound stops the agent has an accurate estimate of the object location that helps it fifind the sounding object (the sink). The second episode (bottom) has a much shorter acoustic event. The agent’s estimate of the object location is inaccurate when the sound stops but still helps the agent as a general directional cue. The agent leverages this spatial cue and the semantic cue from its estimate of the object category, a cabinet, to attend to its multimodal memory to find the object in the kitchen and end the episode successfully.
图3:SAVi导航轨迹示例。在第一episode(顶部/品红色)中,代理听到滴水声,在第二episode(底部/橙色)中听到开门和关门声。对于每一episode,我们展示了从开始位置①、声音停止位置②和结束位置③处的代理轨迹中采样的三个以自我为中心的视觉视图(右)。
在上一episode中,声学事件持续三分之二的轨迹,当声音停止时,代理对对象位置有准确的估计,这有助于它找到发声对象(水槽)。第二episode(底部)的声音事件要短得多。当声音停止时,代理对对象位置的估计是不准确的,但作为一般的方向提示,仍然有助于代理。代理利用这一空间线索和来自其对对象类别(橱柜)的估计的语义线索,关注其多模态记忆,以在厨房中找到对象并成功结束本集。
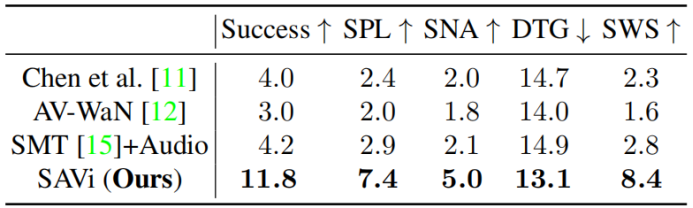
Table 2: Navigation performance on unheard sounds in the presence of unheard distractor sounds.
表2:在存在未听见干扰音的情况下,未听见声音的导航性能。

Table 3: Ablation experiment results.
表3:消融实验结果。

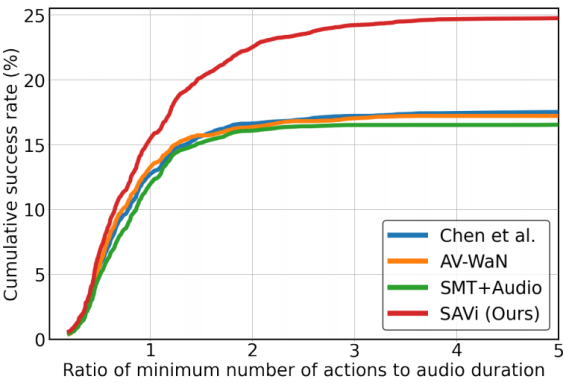
Figure 4: Cumulative success rate vs. silence percentage.
图4:累积成功率与沉默百分比。

















 4149
4149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









