






Deep Learning Approach for Aspect-Based Sentiment Classification: A Comparative Review
基于方面的情感分类的深度学习方法:对比综述
1 ABSTRACT (摘要)
各种电子商务网站的出现,导致了对各种服务和产品的评论网站的激增。如今,人们很容易通过评论获得将要使用的产品和服务的有关信息。在这里,情感分析在产品评论的极性分类中起着重要作用。
然而,在大量的评论中,仅给出整体极性的情感分析是不够的。这将使我们很难找到对产品的某些方面的评论。基于方面的情感分析作为细粒度的情感分析,能够为句子中包含的每个方面提供特定的极性。
各种开发方法用于提供(基于方面的情感分析上的)精确结果。本文将讨论已经开展的各种深度学习方法,并提供可以从基于方面的情感分析中进行研究的可能性。
2 Introduction (介绍)
随着互联网工具使用次数的迅速增加,亚马逊、沃尔玛和阿里巴巴等电子商务的使用次数最近也有所增加。作为一种新的购物和营销渠道,电子商务的发展正在导致各种服务和产品的评论网站的激增(Pontiki、Galanis和Papageorgiou 2015)。顾客在网上购买产品,并自由地表达自己的意见和想法。由于这种增长,产生了大量的数据。在商业领域,这些海量的评论数据有助于了解客户对公司产品和服务的情感和意见,这些情感和意见通常是以自由文本形式表达的。客户评论是非结构化的文本形式,这使得计算机很难对其进行总结。此外,手动分析如此庞大的数据几乎是不可能的。在这里,自动情感分析就是来解决这些问题。图1图2表1
Figure 1. Level of sentiment analysis. 情感分析的层面
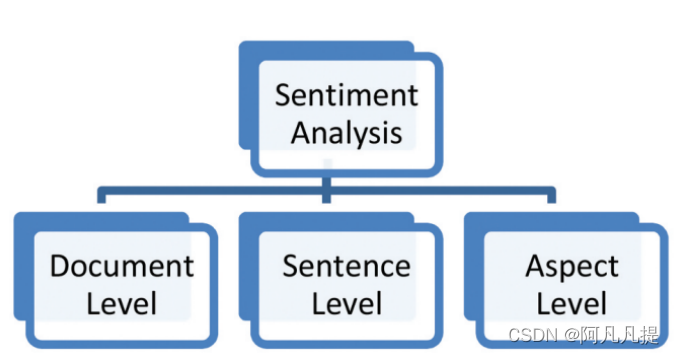
Figure 2. Journal sources distribution. 期刊来源分布
情感分析也称为意见挖掘(Pang and Lee,2008),根据输入的整体极性进行经典分类。然而,目前的大多数方法都试图检测句子、段落或文本垃圾邮件的整体极性,并基于这样的假设:句子中所表达的情感是统一和一致的,而这在现实中并不成立。情感分析的目的是根据文本的情感状态和主观信息,将文本分为正面(积极)或负面(消极),有时甚至是中性。在这种情况下,情感分析被称为情感分类,因为它将极性分为两类或更多类。理论上,情感分析分为三个层面,即文档层面、句子层面和方面/特征层面,有时也称为目标层面。在文档级别,情感分类是通过查看评论中的观点并确定其极性来确定的。该系统将决定整体评论是否包含正面或负面的评论(Toqir和Cheah2016)。在句子层面,对句子逐一进行分析。情感分析的最后一个层面是方面层面的情感分析。方面级情感分析旨在对特定实体或实体类别(也称为目标)进行细粒度的意见挖掘(Ren et al.2020)。
基于方面的情感分析的目标是识别评论者在评论或评论中表达的特定意见目标/方面的情感极性。传统的方法主要侧重于设计一组特征,如词袋、情感词典,以训练分类(例如,SVM),用于基于方面的情感分析(Jiang等人,2011)。为了使系统准确,上述策略需要很多特征(功能),并提出了后来的机器学习技术(Manek和Shenoy 2016;Syahrul和Dwi 2017)。然而,随着自然语言处理(NLP)中深度学习的普及,研究人员使用这种方法来解决基于方面的情感分析问题(Poria、Cambria和Gelbukh 2016;Tang、Qin和Liu 2014)。
本调查将讨论解决基于方面的情感分析问题所使用的方法。通过这项调查,将有可能看到解决这些问题的方法模式。
3 Method for Collect and Review Papers (论文的收集和评审的方法)
在对基于方面的情感分析进行综述时,第一步是找到我们将综述的相关期刊。我们审查期刊的搜索过程是通过谷歌学术来搜索它们,使用一些相关的关键词,如ABSA、方面提取和方面提取中的深度学习。从谷歌学术中,我们选择与基于方面的情感分析的深度学习相关的论文,然后还查看了IEE、Springer、《Science direct》等期刊的声誉。
在这里,我们将展示期刊来源的分布。
找到相关论文后,下一步是评审。我们要做的审查过程是,首先,我们整理出与我们要审查的主题相匹配的标题。第二,我们开始看论文的摘要,如果我们认为它们是相关的,我们将在下一阶段使用它们进行检阅。第三,我们看看所提出的方法,以及该方法是否是深度学习,如果使用的方法是深度学习,那么我们将使用它。第四,我们看一下数据集。我们将在这里比较的数据集只使用ABSA任务中使用最广泛的数据集,即SemEval数据集和Twitter数据集。最后一个阶段是我们查看每篇论文的结果,即准确率和F1值,然后与几项研究进行比较。
4 Aspect-Based Sentiment Analysis (基于方面的情感分析)
电子商务上的在线销售产品经常要求客户检查他们购买的产品和相关服务。随着电子商务越来越受欢迎,产品收到的客户评论数量迅速增长。对于一个受欢迎的产品,评论的数量可以说是数百条甚至上千条。这使得潜在客户很难阅读他们做出正确购买产品的决定。这也使产品制造商很难跟踪和管理客户的意见。这些问题可以通过情感分类或情感分析来解决。
在客户评论的情况下,可以观察到客户总是在一个句子中同时评论多个方面。这类问题无法用传统的情感分类来解决。ABSA来克服这个问题。与传统的情感分析相比,细粒度的ABSA可以更好地理解评论,而不是预测整体的情感极性。假设一位restaurant顾客对他参观过的restaurant发表评论:“虽然服务很差,但价格很合理。”在这句话中提到了两个目标“价格”和“服务”,它们分别表示积极和消极。该实例可以表明,当考虑到不同的方面时,极性可能是相反的。
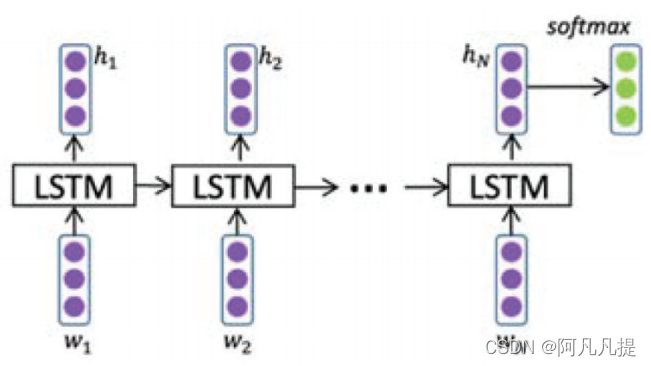
Figure 4. Architecture of standard LSTM (Wang et al. 2016).(标准LSTM体系结构)
在本调查中,我们将基于方面的情感分析(ABSA)分为三个子任务:方面术语提取、方面术语聚类和方面术语情感分类。图3显示了ABSA中的子任务。
Figure 3. The sub-tasks of ABSA.(ABSA的子任务。)
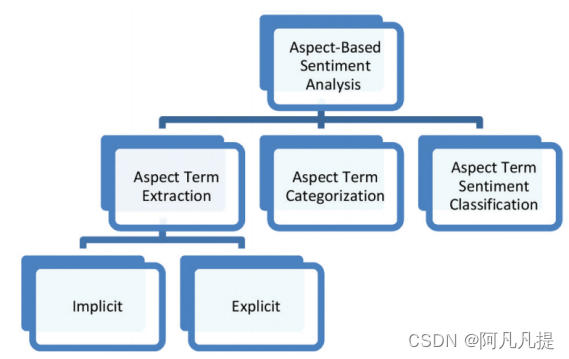
4.1 Aspect Term Extraction (ATE) (方面术语提取(ATE))
方面术语提取(或方面识别或意见目标提取)是ABSA的一个子任务,用于识别给定句子中提到的不同方面。ABSA的主要任务是从评论文本中提取方面(Da'u和Salim 2019)。传统的方面术语提取方法通常依赖于使用手工制作的特征、线性和集成的网络架构。虽然这些方法可以取得良好的性能 ,但它们很耗时且往往非常复杂。在现实系统中,一个具有对比结果的简单模型通常比复杂模型更有效、更可取。
意见挖掘的方面术语提取(ATE)首先由Hu、Liu和Street(2004)进行了研究。它们引入了显式方面和隐式方面之间的区别。显式方面是在固定的句子中明确表示目标的概念。例如,在这个例子中,“我喜欢我的手机的触摸屏,但电池寿命很短。”触摸屏和电池续航时间是句子中明确提到的显式方面。另一方面,一个方面也可以通过一个隐式方面间接表达(Chen和Chen 2016),例如句子“这款相机时尚,非常实惠”,它隐含了对实体相机的“外观”和“价格”的积极看法。如第一个示例所述,它包含两个方面,即“触摸屏”和“电池寿命”。在这种情况下,由于用户表达的两种观点相反,因此应用句子级极性检测技术,会错误地导致极性值接近中性。因此,必须首先将句子解构为产品特征,然后为这些特征分配一个单独的极性值。再举一个例子,“我的手机屏幕非常漂亮,分辨率非常好”,因为手机评论包含正极性,也就是说,作者喜欢手机。然而,更具体地说,正面的观点是关于它的屏幕和分辨率。因此,这些概念被称为这些意见的意见目标(或方面)。在给定的固定文本中识别方面的任务被称为方面提取(茯苓、坎布里亚和Gelbukh2016)。
基于规则的方法已成为早期研究中的一种流行方法。Poria等人(2014)提出了ATE,他们的目标是(通过提出一种新的基于规则的方法来)解决产品评论中的ATE问题,(新的基于规则的方法)利用常识知识和句子依赖树来检测显性和隐性方面(Liu等人,2016年),提出以双传播为基础,并通过方面推荐、基于语义相似度和基于方面关联显著改进了其结果。由于基于规则的方法越来越流行,一些研究改进了自动化系统如何(为ATE)识别合适的规则(Liu和Gao 2016;Rana和Cheah 2017)。基于规则的方法通常不会将提取的方面术语分组。
在有监督方法中,机器学习系统在人工标注的数据上进行训练,以提取评论中的目标。有监督方法中最常用的技术是决策树、支持向量机(SVM)(Manek和谢诺伊,2016)、K近邻(Shah等人,2020)、朴素贝叶斯分类器(Kaur,2021)和一些神经网络(凯斯勒,2009;Pontiki等人,2016年)。
然而,为了避免依赖监督学习所需的标记数据,采用了无监督方法(He等人,2017),使用句法和上下文模式自动提取产品特征,而无需注释数据(Liu等人,2015;Liu和Gao等人,2016)。
条件随机场(CRF)是一种基于监督的方法之一,是用于命名实体识别(NER)问题的一种很有前途的方法。由于这个原因,大多数研究人员在体提取任务中使用CRF,因为NER和方面提取有类似的问题。Shu等人(2017b)使用终身学习方法与CRF(L-CRF)相结合,利用从以前(未标记数据)领域的提取结果中获得的知识,来改进其提取能力。
上述的方法都有它们自己的局限性。CRF是一个线性模型,所以它需要大量的特征才能很好地工作,语言模式需要手工制作,它们(CRF)在很大程度上取决于句子的语法准确性。近年来,基于深度学习模型的方法在任何情感分析任务(包括方面提取)中都取得了很好的效果。为了克服上述限制,Poria、Cambria和Gelbukh(2016)提出了一种深度卷积神经网络(CNN),这是一种更容易拟合数据的非线性监督分类器。他们还引入了特定的语言模式,并将语言模式方法与(用于ATE任务的)深度学习方法相结合。
CNN广泛应用于图像处理领域的研究。由于CNN不需要复杂的计算,Kim 2014建议CNN进行句子分类,以获得一个有希望的结果。由于这个结果,CNN在文本分类任务中变得更加流行,尤其是ATE任务。在ATE任务中,根据句子的上下文,每个方面都有不同的领域。通过修改嵌入层,Xu et al.(2018)使用了双嵌入层,为CNN层(DE-CNN)提供了更好的性能。他们使用通用嵌入和特定于域的嵌入来提高性能。
Shu等人(207年)使用相同的双重嵌入方法修改了标准CNN(徐等人,2018年)。他们称之为受控CNN(Ctrl),其思想是通过异步更新控制模块和CNN层,它可以提高单个任务的性能。Da'u和Salim(2019)利用不同的嵌入层使用了多通道卷积神经网络(MCNN)。与DE-CNN类似,它们也使用双词嵌入、通用嵌入和域嵌入,但不同之处在于,在这种方法中,它们使用额外的嵌入层,即词性(POS)标记和卷积层,用于从嵌入层提取局部特征。Jabreel、Hassan和Moreno(2018)使用双向门控循环神经网络来提取推文的目标。
4.2 Aspect Term Categorization (ATC) (方面术语分类)
ABSA的第二个子任务是聚集同义方面术语到类别,其中,每个类别都代表一个单一的方面,我们称之为方面聚类(Mukherjee和Liu 2012)。对于给定的例子,在句子“我必须说他们的交货时间是这个城市中最快的之一”中,方面术语是“交货时间”。例如,我们可以聚集具有类似含义的方面术语为类别,其中每个类别代表一个单方面(例如,将“送货时间”、 “服务员”和“员工”聚类到一个方面服务)。Ganu、Elhadad和Marian(2009)在餐馆评论中采用了特定类别的情感分类。他们首先确定了restaurant的六个基本类别。然后确定,评论的文本实体是是一个比其他元信息(如星级评级)更好的指标。
ukherjee和Liu(2012)在不同的环境(setting)下解决了这个问题,其中,用户提供了多个标题词,用于多方面类别和该模型提取(方面术语)同时将方面术语分类成类别, 其中,该模型是通过提出两个新的统计模型:种子方面情感模型(SAS)和最大熵种子方面情感模型(ME-SAS)实现的。方面类别分类(ACC)和方面术语提取(ATE)通常是独立处理的,尽管它们紧密相关。直观地说,一项任务进行学习知识应该通知另一项学习任务。薛等人(2017)提出了一种基于神经网络(MTNA)的多任务学习模型来解决这两个任务。ACC是一项监督分类任务,其中句子应该根据预定义方面的子集标签来进行标记,ATE是一项顺序标记任务,其中单词‘tokens’(与给定方面相关) 应该根据预定义的标记方案进行标记,如IOB(内部、外部、开始)。他们将(用于ATE的)BiLSTM和(用于ACC的)CNN结合在一个多任务框架中。Senarath、Jihan和Ranathunga(2019年)提出了用于方面提取的混合分类器,将(提出的改进)CNN和(使用最先进人工设计的特征)SVM相结合。
Akhtar、Garg和Ekbal(2020)提出了(用于这两个任务的联合学习的)两种策略(方面术语提取和方面情感分类)。第一种方法基于端到端框架,这两个任务按顺序解决。此任务使用了BiLSTM-CNN,BiLSTM负责学习一个句子中的tokens的顺序模式。此外,自我注意模块旨在帮助系统学习句子中其他tokens的重要性,用于标记当前token作为方面术语的内部(或外部),并且使用softmax函数进行BIO分类。CNN层用于捕获每个token的本地上下文。相比之下,第二种方法将这两个任务合并为一个任务,并将它们作为架构中的一个任务来解决。他们将每个token分为九类中的一个,即 B-Positive, I-Positive, B- Negative, I-Negative, B-Neutral, I-Neutral, B-Conflict, I-Conflict, 和 O.
4.3 Aspect Term Sentiment Classification (方面术语情感分类)
ABSA中的最后一个子任务是方面术语情感分类。在评论句中提取方面词并对其进行分类之后,ABSA的提出被归类为情感极性。Tang等人(2016年)提出了一种使用长-短期记忆的依赖目标的情感分类。这里的“目标”一词与我们在本次调查中使用的“方面”一词含义相同。基于目标的情感分类在文献中通常被认为是一种文本分类问题。因此,可以自然地使用标准的文本分类方法,例如基于特征的支持向量机(Jiang et al.2011;Pang et al.2002)来构建情感分类器。例如,Jiang等人(2011年)利用专家知识、语法分析器和外部资源手动设计了与目标无关的特征和与目标相关的特征。尽管特征工程很有效,但它是劳动密集型的,无法发现数据的区别性或解释性因素。为了解决这个问题,Tan等人(2014)提出了一种方法,将句子的依赖树转换为特定于目标的递归结构,并使用自适应循环神经网络学习更高级的表示。另外,Vo和Zhang(2015)使用了丰富的功能(特征),包括情感特定词嵌入和情感词汇。
ABSA中的情感极性不仅取决于句子评论的方面,还取决于内容。在Wang等人(2016)的研究中,他们发现句子的情感极性高度依赖于内容和方面。例如,“员工不是很友好,但口味涵盖了所有方面,非常完美。”如果方面词是食物,则为正,但考虑方面词服务时为负。当考虑到不同的方面时,极性可能是相反的。
5 Method for Aspect-Based Sentiment Classification (ABSA) (基于方面的情感分类方法(ABSA))
解决ABSA问题的传统方法是手动设计一组特征。这些传统方法主要侧重于设计一组特征,如单词袋、用于训练分类的情感词典(如SVM)(Jiang等人2011年)、基于规则的方法(Ding等人2008年)和基于统计的方法(Jiang等人2011年;Zhao等人2010年)。然而,特征工程是劳动密集型的,几乎研究它的都遇到了性能瓶颈(Ma et al.2017),因为它需要大量标记数据。随着深度学习技术的发展,一些研究人员设计了有效的神经网络,从目标及其上下文中自动生成有用的低维表示,并在ABSA任务中获得了有希望的结果。在这一部分中,我们将讨论ABSA中使用的方法。
6 Method Based on Recurrent Neural Network (RNN) (基于循环神经网络(RNN)的计算方法)
循环神经网络(RNN)是一种神经网络,其中前一步的输出作为当前步骤的输入。在传统的神经网络中,所有的输入和输出都是相互独立的,但是当需要预测句子的下一个单词时,就需要前面的单词,因此需要记住前面的单词。因此,RNN应运而生,它借助一个隐藏层解决了这个问题。这里我们将描述研究人员在ABSA任务中使用的基于RNN的方法。
6.1 Long Short-Term Memory (LSTM) (长短期时记忆(LSTM))
标准RNN存在梯度消失或爆炸问题,梯度可能在长序列中呈指数增长或衰减。为了克服这些问题,人们开发了长短时记忆网络(LSTM),并取得了优异的性能(Hochreiter和Schmidhuber 1997)。与传统的前馈神经网络相比,LSTM具有反馈连接。它不仅可以处理单个数据点(如图像),还可以处理整个数据序列(如文本、语音和视频)。在LSTM体系结构中,有三个门(输入门、忘记门和输出门)和一个单元存储器状态。输入门负责向单元状态添加信息。遗忘门负责从单元状态中删除信息。LSTM不再需要的信息或不太重要的信息通过过滤器的乘法被删除。这是优化LSTM网络性能所必需的。输出门的任务是从当前单元状态中选择有用的信息,并在通过输出门输出时显示出来。图4说明了标准LSTM的体系结构。图5图6图7
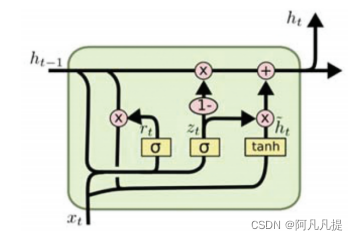
Figure 5. Gated Recurrent Unit (GUR) Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs.
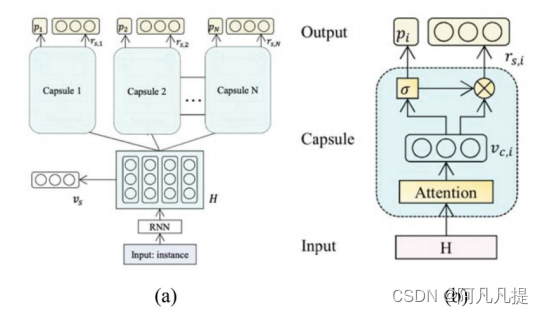
Figure 6. a. Capsule structure on sentiment analysis; b. architecture of a single capsule (Wang, Sun, and Han 2018).
a.情感分析中的胶囊结构;b.单个胶囊的结构
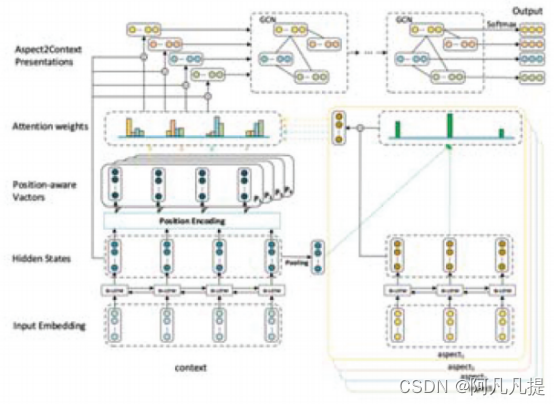
Figure 7. An example to illustrate the usefulness of the sentiment dependencies between multiple aspects (Zhao, Hou, and Wu 2019). 举一个例子来说明多个方面之间的情感依赖关系的有用性
更正式地说,LSTM中的每个单元可以计算如下:
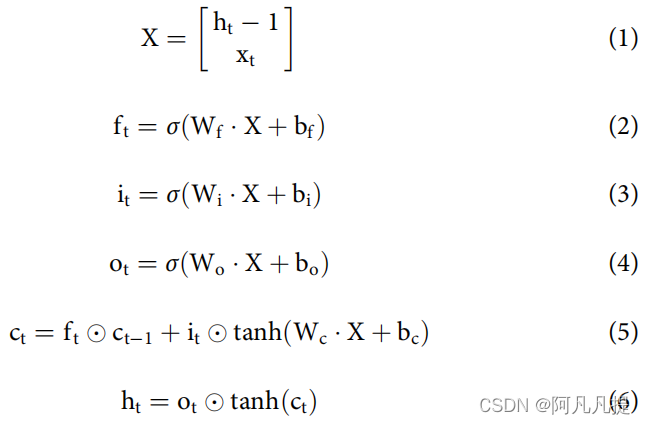
由于LSTM可以捕获序列模型,大多数研究人员在文本分类和情感分类任务中使用LSTM方法,尤其是在ABSA中。依赖目标的情感分类(TD-LSTM)最早由Tang等人(2016)提出。该方法是LSTM模型的一个扩展,标准LSTM模型不能捕捉任何目标信息,因此它可以预测句子中不同目标的相同结果。一般提出的模型是使用两个LSTM神经网络,左和右LSTM,分别建模前面和下面的上下文,分别在目标被放置在句子的中间。
Wang等人(2016)提出了在LSTM中添加方面词嵌入的新想法(ATAE-LSTM)。除了添加方面嵌入,他们还使用注意力机制。这是首次提出在ABSA任务中嵌入方面词。通过在ATAE-LSTM中使用注意力机制,马等人(2017)考虑到目标的单独(分别)建模,特别是借助于上下文,他们提出了交互式注意网络(IANs),该网络基于LSTM模型和注意力机制,在上下文和目标中交互学习注意,并分别生成目标和上下文的表示。
以前基于LSTM的方法主要侧重于单独(分别)建模文本,而它们使用LSTM同时建模方面和文本。此外,LSTM生成的目标表示和文本表示通过一个 attention-over-attention(AOA)模块相互作用,而不是受问答系统中AOA的使用进行启发(Cui等人,2017)。同时,He等人(2018)提出了一种基于LSTM的注意力建模改进方案。
联合注意LSTM网络(Joint attention LSTM network)(JAT-LSTM)旨在将方面注意和情感注意结合起来,构建一个联合注意LSTM网络(蔡和李2018)。该模型将方面词嵌入和情感词嵌入与句子嵌入相结合,作为LSTM网络的输入,使LSTM网络的输入信息更加丰富。
在表2中,我们给出了几个以LSTM为基础模型的ABSA模型的精确性和F1研究结果。我们可以看到,在SemEval 2014数据集中具有LSTM基础的其他模型中,JAT-LSTM的精确性最高。但对于SemEval 2015、2016和Twitter数据集,我们可以结合使用,因为只有一种方法使用这些数据集。稍后我们将结合另一种方法。Laptop和Rest代表SemEval 2014域,Twitter代表Twitter域,Rest 15代表SemEval 2015 Restaurant领域,Rest 16代表SemEval 2016 Restaurant领域。粗体值表示得分最高的模型。

6.2 Gated Recurrent Unit (GRU)
门控循环单元(GRU)是LSTM的一种变体,于2014年引入(Cho等人)。GRU被设计为具有更持久的记忆,这使得它们在捕获序列元素之间的长期依赖关系时非常有用。它将忘记门和输入门组合成一个更新门。它还合并了单元格状态和隐藏状态,以及其他更改。由此产生的模型比标准的LSTM模型简单,并且在许多任务中已成为一种流行的模型。GRU有复位(rt)和更新(zt)门。如果前者认为过去的隐藏状态ht1与新状态的计算无关,则前者有能力完全减少该隐藏状态,而后者负责确定有多少ht1应结转到下一个状态ht。GRU的输出ht取决于输入xt和之前的状态ht1,其计算如下:
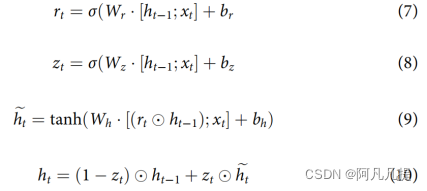
由于GRU的模型比LSTM简单,许多研究人员已经开始使用GRU模型开发ABSA任务。大多数ABSA任务都假设在确定情感极性之前,目标或方面词是已知的。
与此同时,Jabreel、Hassan和Moreno(2017)提出了一个推文(tweet )的依赖目标的情感分析模型,该模型能够识别和提取Twitters的目标,表示目标与其上下文之间的相关性,并识别对目标的Twitters(tweet)的极性。他们使用bi-GRU模型(TD-BiGRU)提取目标并确定情感极性。
顾等人(2018)在他们的工作中证明,当一个方面词出现在一个句子中时,其相邻词应该比其他长距离词给予更多的关注。他们提出了一种基于双向GRU的位置感知双向注意网络(PBAN)。它不仅关注方面词的位置信息,还利用双向注意机制对方面词与句子之间的关系进行相互建模。ABSA之前的工作已经证明了各方面和上下文之间的相互作用是重要的。除此之外,大多数这些作品在编码句子时都忽略了该方面的位置信息。HAPN (Hierarchy Attention based Position aware Network)(基于分层注意的位置感知网络)(Li、Liu和Zhou 2018)就是为了解决这个问题而提出的。它们在句子建模时引入位置嵌入,并进一步生成位置感知表示。此外,他们还提出了一种基于层次注意的融合机制来融合方面词和上下文的线索。结果表明,该方法对方面级情感分类是有效的,并且优于现有的方法,具有显著的优势。
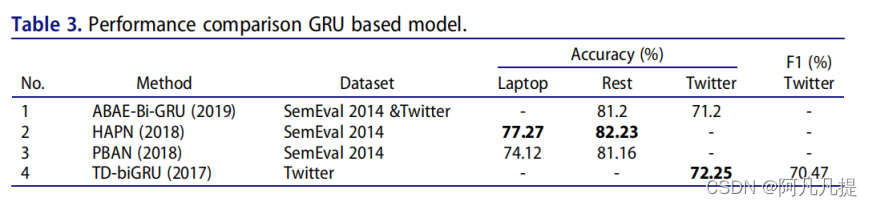
Table 3中,我们给出了几个使用GRU作为基础模型的ABSA模型的精确性和F1研究结果。我们可以看到,在SemEval 2014数据集中,使用GRU基的其他模型中,HAPN的精确性最高,但如果与LSTM基模型相比,JAT-LSTM中的LSTM仍然具有最高的性能。对于Twitter数据集,TD biGRU获得了最高的精确性性能。
7 Method Based on Convolutional Neural Network (CNN) (基于卷积神经网络(CNN)的方法)
卷积神经网络(ConvNets或CNN)是一类在图像识别和分类等领域被证明非常有效的神经网络。CNN除了为机器人和自动驾驶汽车的视觉提供动力外,还成功地识别人脸、物体和交通标志。过去几年,CNN在一些NLP任务中取得了突破性成果,其中一项特殊任务是句子分类(Kim 2014),即将短短语分类为一组预定义的类别。
大多数卷积神经网络(CNN)方法用于文本分类任务,可以在许多标准情感分类数据集上实现最先进的性能。CNN模型由嵌入层、一维卷积层和最大池层组成。嵌入层通常使用预训练来进行初始化,如Glove(彭宁顿、Socher和曼宁2014)。
由于ABSA是文本分类的一部分,一些研究人员使用了基于CNN的方法。CNN不能单独解决ABSA问题,一些研究将CNN与序列模型(如LSTM)相结合。在ABSA中使用的LSTM存在一些缺陷,如缺乏位置不变性和对局部关键模式缺乏敏感性等缺点。LSTM与ABSA任务中广泛使用的注意机制相结合,但由于它们以循环的方式处理给定的序列,需要更多的训练时间,因此时间效率低下。同时,CNN模型可以解决这些限制,因为卷积层可以在训练期间轻松执行并行操作,而无需等待前一步的结果,但它在捕获长距离依赖关系和建模序列信息方面较弱。
许多研究人员试图解决这一局限性,比如薛和李(2018),他们没有使用注意机制,而是提出了一种基于卷积神经网络和门控机制与方面嵌入(GCAE)的模型,该模型更准确、更有效。
基于稀疏注意的可分离扩展卷积神经网络(SASDCNN)(Gan等人,2019)是一种提出的方法,由多通道嵌入层、可分离扩展卷积模块、稀疏注意层和输出层组成。多通道嵌入使用三个不同的嵌入层,即word2vec、glove和SSWE进行情感嵌入。
Ren等人(2020年)提出了蒸馏网络(distillation network)(DNet),这是一种基于门控卷积神经网络的轻量级高效情感分析模型。该模型首先使用门控卷积网络对句子进行编码,以控制哪些信息对预测情感极性有用。他们使用GCAE(薛和李,2018)的门控单元来提取方面敏感信息。同时,一些研究人员认为方面词的位置及其上下文很重要,Wu等人(2020)提出了一种基于卷积神经网络的ABSA相对位置和方面注意编码模型(RPAEN)。该模型首先引入一个位置编码层,对文本中方面词的相对位置进行编码,从而将相应的相对位置信息融入到模型中,更有利于当前方面词的情感分析。然后,他们使用方面注意机制而不是一般注意机制来更好地捕捉文本中所有单词与方面词之间的依赖关系。
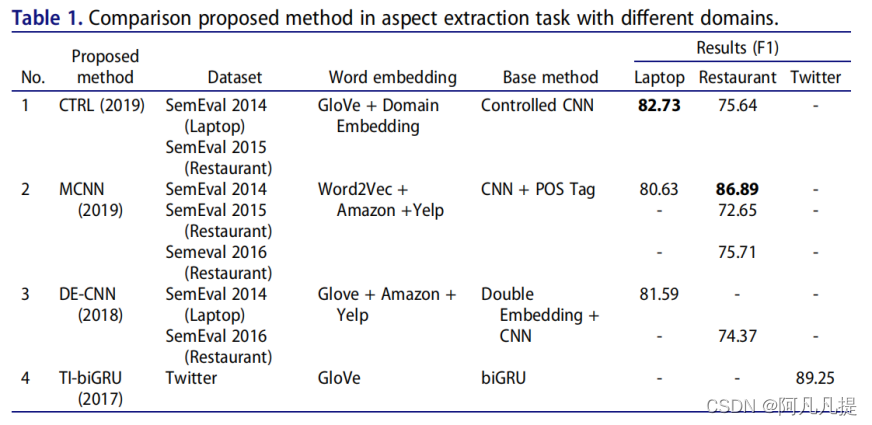
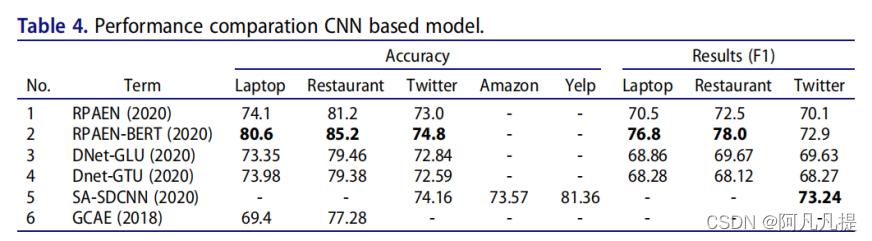
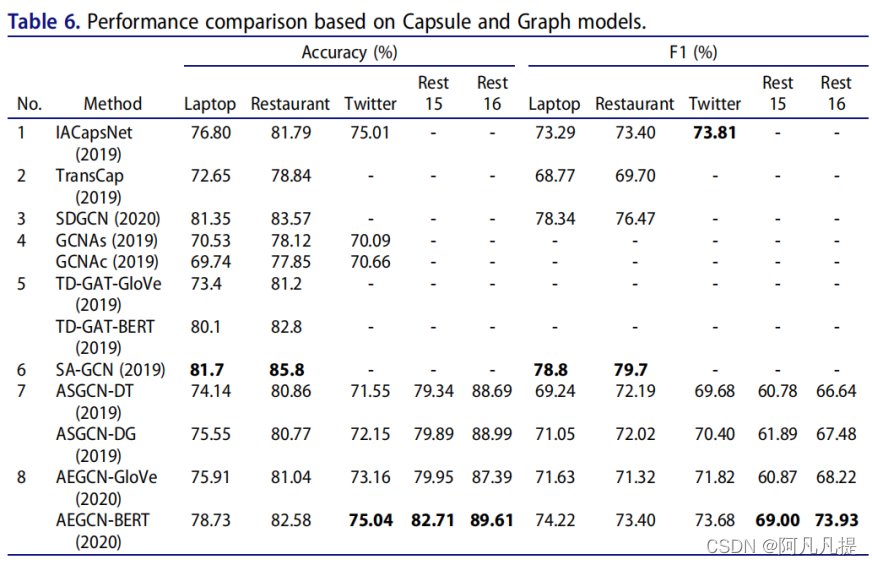
Table 4 shows the results of some popular ABSA methods based on the CNN model.Table 5Table 6
表4显示了基于CNN模型的一些流行ABSA方法的结果。表5表6

8 Method Based on Memory Network (基于记忆网络的方法)
记忆网络是Weston、Chopra和Bordes(2015)提出的一个通用机器学习框架,其结合多跳式的注意力试图明确地只关注信息量最大的上下文区域,以推断对目标词的情感极性。它的中心思想是带有长期记忆成分的推理,可以对其进行读、写和联合学习,目的是将其用于预测。形式上,一个记忆网络由一个记忆m和四个组件I、G、O和R组成,其中m是一个对象数组,比如向量数组。在这四个组件中,I将输入转换为内部特征表示,G用新输入更新旧记忆,O在给定新输入和当前记忆状态的情况下生成输出表示。R根据输出表示输出响应。基于记忆网络的方法通过记忆明确地保存上下文信息,并通过注意力机制获取目标与上下文之间的关系。
Tang、Qin和Liu(2014)提出了一种用于方面级情感分类的深度记忆网络(MemNet)。该方法在推断一个方面的情感极性时,可以捕捉每个上下文单词的重要性。该方法由多个具有共享参数的计算层组成。
9 Attention Mechanism (注意力机制)
注意力模型最近在神经网络训练中得到了广泛应用,并被应用于各种自然语言处理任务,包括机器翻译、句子摘要、情感分类和问答系统。它是在机器翻译中提出,目的是在翻译前选择原语言的参考词。注意机制不是使用所有可用的信息,而是旨在关注与任务最相关的信息。自从在翻译任务中成功应用注意力网络(Bahdanaau、Cho和Bengio 2015;Luong、Pham和Manning 2015)以来,许多工作设计了注意力机制网络来解决基于方面的情感分析。在ABSA任务中,注意力机制能够通过建模每个上下文单词的语义关联来捕捉它们对目标的重要性,从而获得可比较的结果。
Yang等人(2018)提出了一种用于目标依赖情感分类(FANS)的特征增强型注意力网络。他们利用多视角共同注意网络(MCN)改进了注意力模型,通过对语境词、目标词和情感词的交互建模,学习更好的多视角情感感知和目标特定的句子表达。徐等人(2020)也提出了多注意力网络(MAN)。该模型采用了层内和层间的注意力机制。帧内编码采用transformer编码而不是序列模型,以减少训练时间。同时,跨层注意机制使用全局和局部注意模块来捕获方面和上下文之间不同粒度的交互信息。与Zhang和Lu(2019)类似,Zhang et al.(2020)也使用BERT作为预训练样本对数据进行建模。该模型被称为多重交互式注意力网络(MIN)。在预训练过程完成后,他们使用部分transformer 并行获得隐藏状态。
Park、Song和Shin(2020)为ABSA提出了一个深度学习模型,结合了位置注意力和内容(content)注意力。提出了两种模型:一种是在单向单层网络(HRT_one)的目标相关记忆上实现整体的重复内容注意力,另一种是双向双层网络(HRT_Bi)。这两个模型使用目标依赖的LSTM从输入句子中产生记忆,GRU单元用于整合从记忆的不同内容注意力权重中产生的句子表示。
10 Method Based on Capsule Network (基于胶囊网络的研究方法)
为了改善CNN和RNN模型的表示局限性,引入了胶囊网络,以向量形式提取特征。情感分析中的胶囊网络是由王、孙和韩(2018)提出的。他们引入了用于情感分析的RNN胶囊,即基于循环神经网络(RNN)的胶囊模型。每个胶囊不仅能够预测其指定情感的概率,还能够重建输入实例的表示。与大多数现有的用于情感分析的神经网络模型相比,RNN胶囊模型不严重依赖于输入实例表示的质量(quality特性)。该模型不需要任何语言知识。胶囊N的数量与要建模的情感类别的数量相同,每个类别对应一个情感类别。例如,三种胶囊用于模拟三个细粒度情感类别:“积极”、“中性”和“消极”。
由于情感分析任务中使用了胶囊模型,Wang等人(2019)修改了RNN胶囊以适应ABSA任务。他们提出了方面级情感胶囊模型(AS capsule),该模型能够以联合方式同时执行方面检测和情感分类。为了解决缺乏方面级标记数据的问题,Chen和Qian(2019)提出了一种传输(转移)胶囊网络(TransCap)模型(Transfer Capsule Network),用于将文档级知识传输到方面级情感分类。文档级标记的数据(如评论)很容易从在线网站访问。同时,ABSA的公开数据集通常包含有限的训练示例数据。
Du、Sun和Wang(2019)提出了对胶囊网络的另一项改进。该模型将胶囊网络与注意力机制相结合。该胶囊网络用于方面级情感分析,通过特征聚类处理重叠特征。他们使用EM路由算法对特征进行聚类,并构建基于向量的特征表示。此外,在胶囊路由过程中引入了交互注意机制,对方面术语和上下文之间的语义关系进行建模。
11 Method Based on Graph Neural Network (基于图神经网络的计算方法)
图神经网络(GNN)是在(Sperduti和Starita 1997)和(Gori、Monfardini和Scarselli 2005)中引入的,它是循环神经网络的推广,可以直接处理更一般的图类,例如循环图、有向图和无向图。GNN由一个迭代过程组成,该过程传播节点状态直至平衡;然后是一个神经网络,它根据每个节点的状态为每个节点产成一个输出。Jeon等人(2019)提出了基于图形的方面和等级分类,该分类利用多模态词共现网络来解决方面和情感分类问题。基于图形的方面评级分类框架从给定的语料库中构建单词共现网络,如果单词的源文档标记有不同的方面或情感类别,则将其定义为不同的模型。然后,该模型从网络中计算单词方面分散度得分和单词评级分散度得分,然后将其连接起来,并用作方面和评级分类的前馈神经网络的输入。
另一种基于赵、侯和吴(2019)提出的图方法的方法是一种用图卷积网络(SDGCN)建模情感依赖的方法。对于图中的每个节点,GCN将其邻域的相关信息编码为一个新的特征表示向量。一个方面被视为一个节点,一条边代表两个节点的情感依赖关系。该模型通过该图学习各个方面的情感依赖性。
图卷积网络(GCN)通常在两层中表现出最好的性能,更深的GCN由于过度平滑问题不会带来额外的增益。Hou、Huang和Wang(2019)设计了基于选择性注意力的GCN块(GCN block)(SA-GCN),以找到最重要的上下文词,并直接将这些信息聚合到方面术语表示中。
RNN和CNN在ASBA任务中的成功也有缺点,即它们没有充分考虑整个文本结构和给定文档中单词之间的关系。为了克服这些缺点,Chen(2019)提出了一种新的神经网络方法(GCNSA):将文本视为一个图,并在图的特定区域中处理其方面。他们对文本图进行卷积运算以获得全文隐藏状态,并引入了由LSTM实现的扩展结构注意力模型来捕获特定信息。与之前的方法不同,2019 Huang等人(2019年)将句子表示为(依赖关系图)依存图,而不是单词序列。他们提出了一种新的目标依赖图注意网络(TD-GAT),它明确利用了单词之间的依赖关系。在他们的实验中,他们尝试使用两种不同的预训练数据;Glove和BERT。
Hou等人(2019)提出了在图卷积网络(GCN)中使用注意力机制的建议。他们设计了基于选择性注意力的GCN块(SA-GCN),以找到最重要的上下文词,并通过在依赖树上应用GCN,将这些信息直接聚合到方面词表示中。Zhang、Li和Song(2019)提出了一种使用依赖树的类似方法,称为特定于方面的图卷积网络(ASGCN)。它从bi LSTM层开始来捕获有关词序的上下文信息。然后,在LSTM输出上实现多层图卷积结构,以获得特定方面的特征。最近,肖等人(2020)提出了基于注意力编码和图卷积网络(AEGCN)的有针对性的情感分类。该模型采用BERT预训练模型,由建立在句子依赖树上的多头自注意改进图卷积网络组成。
12 Word Embeddings (词嵌入)
词嵌入是文档词汇表的表示。它允许具有相似含义的单词具有相似的表示形式。词嵌入使深度学习方法在具有挑战性的自然语言处理问题上表现出令人印象深刻的性能。词嵌入是一种将单个单词在预定义向量空间中被表示为实值向量的技术。每个单词被映射到一个向量,向量值以一种类似于神经网络的方式学习,因此该技术通常被归类到深度学习领域。在本文中,我们将简要讨论用于ABSA任务的几种词嵌入方法。
12.1 Word2vec
Word2vec是一种用于自然语言处理的统计方法,它使用神经网络模型从大量文本中学习单词关联。Word2vec用一个称为向量的特定数字列表表示每个不同的单词。引入两种不同的模型,即连续单词包(CBOW)和跳过语法,作为word2vec方法学习词嵌入的一部分。当我们回顾与ABSA相关的几篇论文时,我们发现了几个使用word2vec的模型。我们在表7中展示了几种使用word2vec作为词嵌入的模型。
12.2 Glove
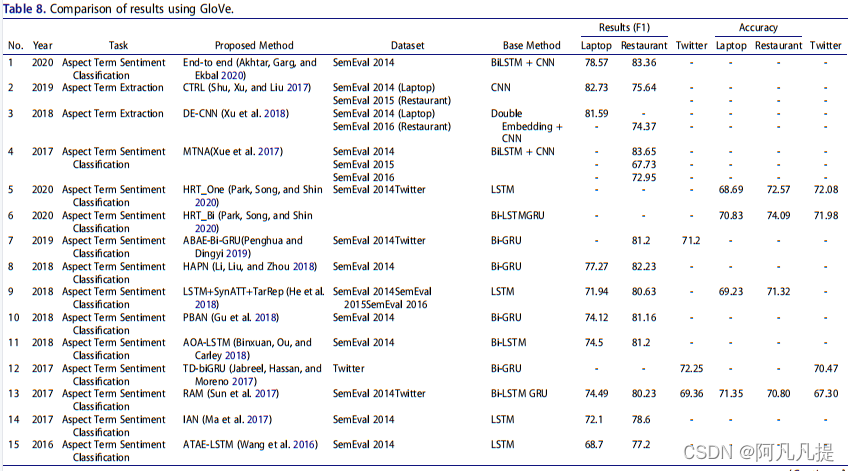
Glove,Global Vectors for Word Representation是word2vec方法的扩展,该方法用于有效学习单词向量,由(Pennington、Socher和Manning,2014)开发。它基于单词上下文矩阵的矩阵分解技术。Glove将单词映射到一个有意义的空间中,其中单词之间的距离与语义相似性有关。NLP领域的许多研究人员使用Glove作为词嵌入,尤其是在ABSA任务中。我们在表8中描述了几项使用Glove作为词嵌入的ABSA研究。
12.3 BERT
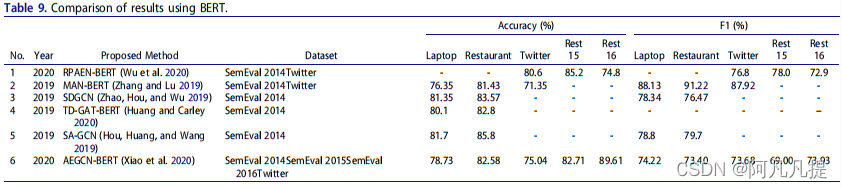
BERT,Transformers的双向编码器表示,是一种语言表示模型,旨在通过在所有层中对左右上下文进行联合调节,对未标记文本的深层双向表示进行预训练。只需增加一个输出层,就可以对BERT进行微调,为宽级别任务(wide rank task)创建最先进的模型(肯顿、克里斯蒂娜和德夫林2019)。由于这些优点,有几项研究试图将其用于ASBA任务。我们在表9中总结了其中一些研究。我们可以说,与使用Glove相比,在ABSA领域,使用BERT作为预训练的词嵌入还没有做多少工作。因此,在解决ABSA问题方面,BERT还有很大的发展空间。
13 Dataset for ABSA (ABSA数据集)
对于数据集部分,我们使用ABSA任务中使用最广泛的数据集,即SemEval 2014任务4和Twitter数据集。我们选择了SemEval 2014 task 4数据集,因为该数据集(在为ABSA制作模型时)被用于竞赛(competition),竞赛(competition)分为几个子任务,即方面术语提取、方面类别极性、方面类别检测和方面术语极性。该数据集由两个域组成,即restaurant 域和laptop 域,其内包含有关产品的评论,产品有即restaurants 和laptops。因此,该数据集是建模ABSA问题最广泛使用的数据集。
与此同时,除了SemEval 4014 task 4数据集之外,第二个最常用的数据集是Twitter数据集。与SemEval上的数据集不同,Twitter数据集使用用户在Twitter上撰写的评论。因此,Twitter数据集中没有使用特殊的域。
13.1 SemEval 2014 Dataset
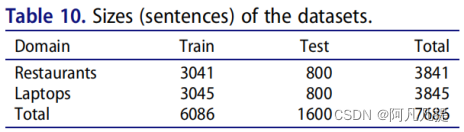
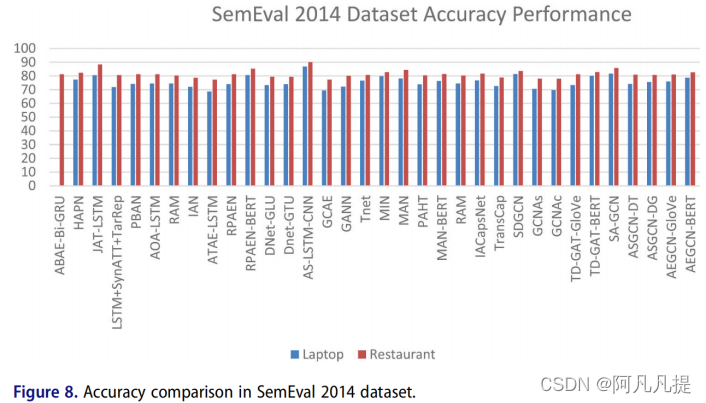
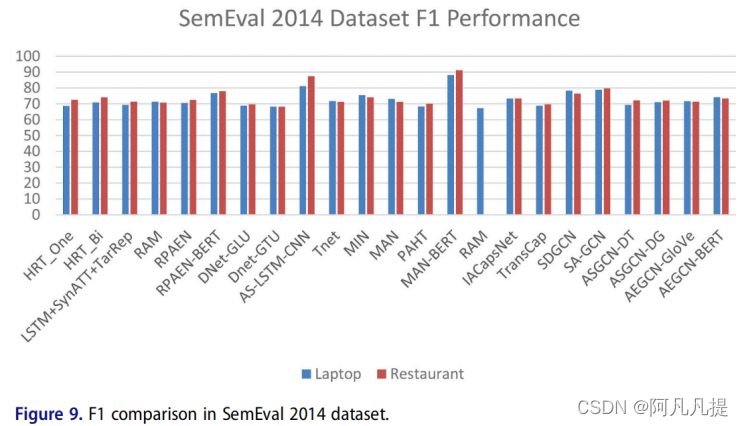
Pontiki和Pavlopoulos(2014)提出了SemEval 2014数据集,其中包含对restaurant和laptop的手动注释评论。这里我们将描述有关SemEval数据集的详细信息。表10描述了句子中数据集的大小,表11描述了方面术语及其每个域的极性。具有laptop和restaurant领域的SemEval 2014数据集已成为ABSA任务研究人员的热门数据集。我们将以上提出的方法结合起来,并将它们放在一个图表中。我们将图表分为两个评估性能。图8显示了精确性性能,图9显示了F1的性能。
从图中可以看出,在laptop和restaurant领域中,As-LSTM-CNN的精确度最高。我们可以说,最好的性能是卷积神经网络(CNN)和循环神经网络(RNN)的结合。同时,最高的F1性能(表现)来自于MAN-BERT,我们可以说,预先训练过的BERT可以提供比其他的更好的表现。根据这个结果,我们可以开发更多的组合方法和预先训练的模型,以获得更好的性能。

13.2 Twitter Dataset
不仅用于基于方面的情感分析的产品评论,而且Twitter数据集在解决ABSA任务方面也受到了广泛关注。Tan等人(2014),在Twitter上手动注释了一些帖子评论。他们使用关键词(如“比尔·盖茨”、“泰勒·斯威夫特”、“xbox”、“windows 7”、“谷歌”)来查询Twitter API。图10显示了Twitter数据集在准确性和F1性能方面的图表性能。从这些方法中,我们可以看出,门控循环单元的性能最好。
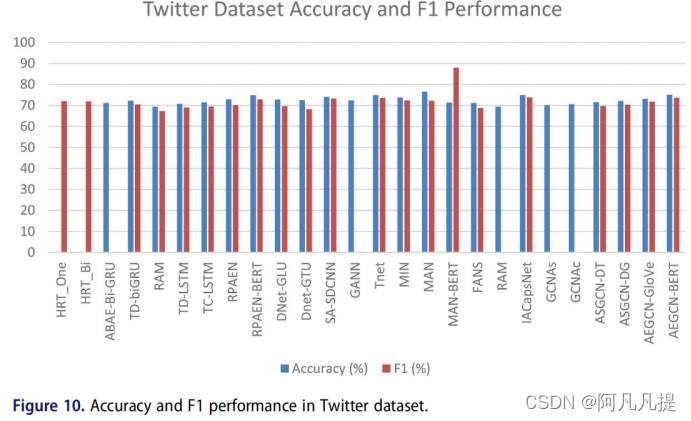
从上图中,我们可以看出,当我们使用Twitter数据集时,MAN获得了最佳的准确性性能。同时,如果我们谈论F1的得分表现,MAN-BERT的得分最高。尽管如此,我们仍可以说,使用预先训练好的BERT模型可以产生更大的影响。
14 Classification Performance Evaluation Metrics (分类绩效评估指标)
为了衡量分类方法的性能,大多数研究人员使用标准评估指标(Yang 1999)。在大多数ASBA任务中使用了四个标准指标。在本节中,我们将描述四个评估指标。
14.1 Precision (精确率)
精确性定义为true positives数除以true positives数加上false positives数。
False positive是指模型错误地标记为positive 而实际上为negative的情况。

Precision:被分类器挑选出来的正样本究竟有多少是真正的正样本!
true positives:TP 将正类预测为正类数
false positives:FP 将负类预测为正类数
false negatives:FN 将正类预测为负类数
true negatives:TN 将负类预测为负类数
14.2 Recall (召回率)
A recall is defined as the number of true positives divided by the number of true positives plus false negatives.
召回定义为 true positives数除以 true positives数加false negatives数。
Recall:在所有真正的正样本里面,分类器挑选了几个!
14.3 F1-Score (F1-得分)
F1分数(也称为F分数或F度量)是测试准确性的衡量标准。它同时考虑了精确性p和召回率r。它是p和r的加权平均值。

14.4 Accuracy (准确率 )
准确率只是衡量分类器进行正确预测的频率。它是正确预测数与预测总数(测试集中的数据点数)之间的比率
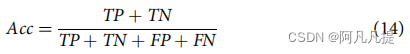
这里TP代表True Positive数,TN代表True Negative数,FP代表False Positive数,FN代表False Negative数。
15 Conclusion
在本调查中,我们描述了基于方面的情感分析(ABSA)。首先,我们描述了ABSA的任务,我们描述了三个子任务,即方面术语提取、方面术语分类和方面术语情感分析。我们为ABSA中的每个任务提供了几个模型。其次,我们描述了用于解决ABSA任务的深度学习方法。最后,我们描述了在ABSA任务中使用的两个流行的数据集。
从我们进行的调查中,我们可以看到ABSA问题仍然是一个有趣且非常广泛的问题,因为可以使用许多方法,并且仍然需要有效的方法来解决ABSA问题。许多深度学习模型已经被用于ABSA,然而,在ABSA任务中建立一个高效、高精确性的模型仍然是一个非常具有挑战性的问题。综上所述,我们可以说,图形模型和胶囊模型尚不多见,未来可以考虑在这两个模型的基础上建立模型。
我们可以看到,词嵌入的使用对准确性水平也有很大影响。例如,在一个模型中,使用不同的词嵌入将导致不同程度的准确性,例如在一个模型中使用 Glove 和BERT。因此,词嵌入的选择变得非常重要。BERT在这里可以被认为是一种经过预先训练的嵌入用法。从这两个数据集中,我们还发现每个数据集都有不同的方法来获得更好的性能。要找到可以在多个数据集中灵活使用的方法仍然具有挑战性。

















 9197
9197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









