




最近在开发spark streaming 程序时对这些概念有了深刻的理解,在此总结下。
我最近的 spark streaming 核心代码如下:
stream.foreachRDD(rdd -> { try { // extract all activity events rdd.flatMap(record -> { String topic = record.topic(); TopicHandler handler = HandlerFactory.getHandler(topic); return handler.handle(record.value()); }).groupBy(act -> act.getMemberSrl()) // process all activities .foreachPartition(itr -> { while (itr.hasNext()) { Iterable<Activity> acts = itr.next()._2; Processor.process(acts); } }); } catch (Exception e) { log.error("consumer rdd error", e); } });
1 Job
就是spark batch/streaming 里的一系列的数据转换 + 一个结果算子(比如collect, count,foreachPartition )。
2 Stage
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点


参考:https://blog.youkuaiyun.com/u013013024/article/details/72876427
在我的spark 程序中,groupBy 和 foreachPartition 因为涉及到shuffle操作,他们是宽依赖的边界,所以分配在两个不同的stage里。
stage 1: groupBy("")
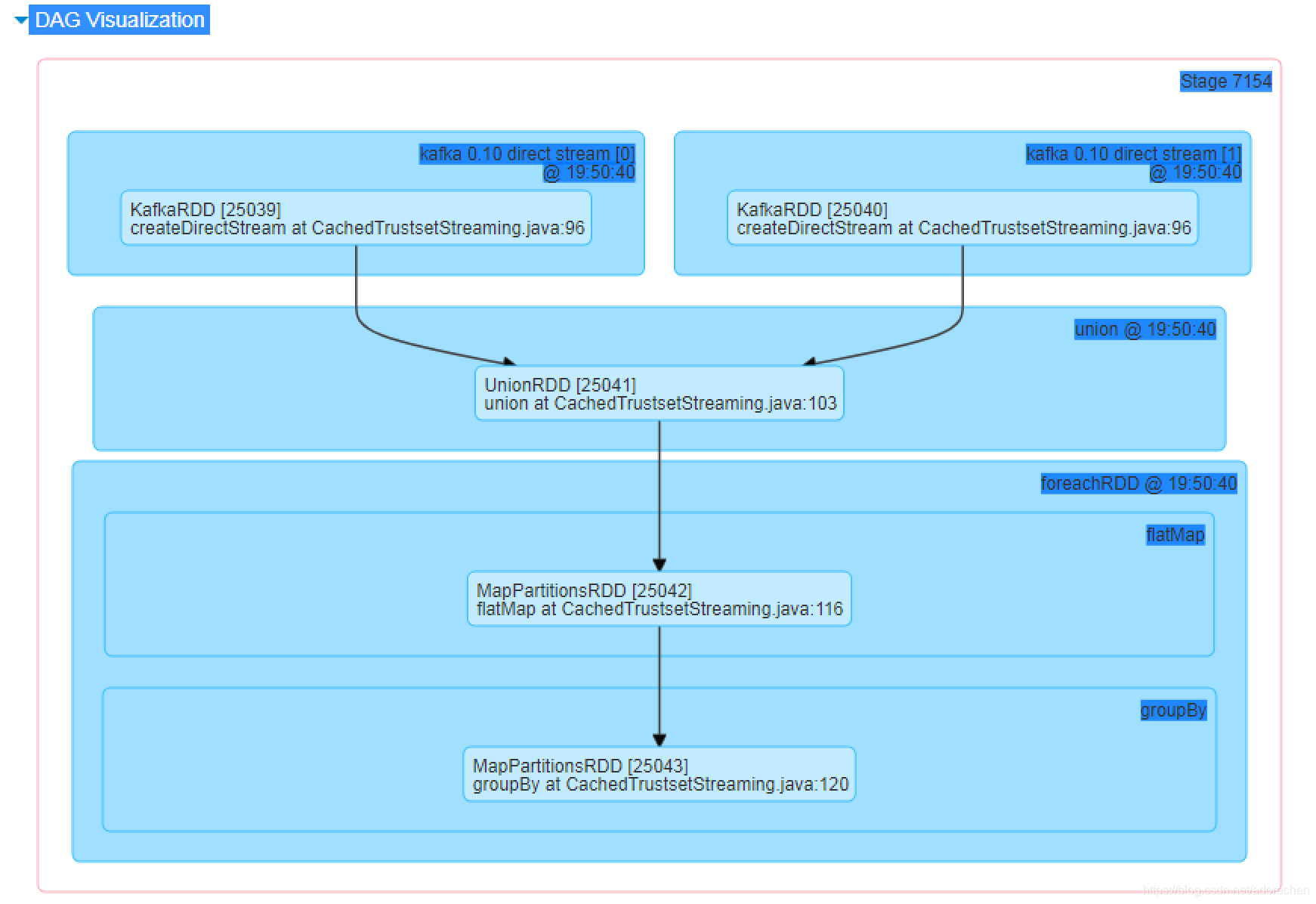
stage 2: foreachPartition
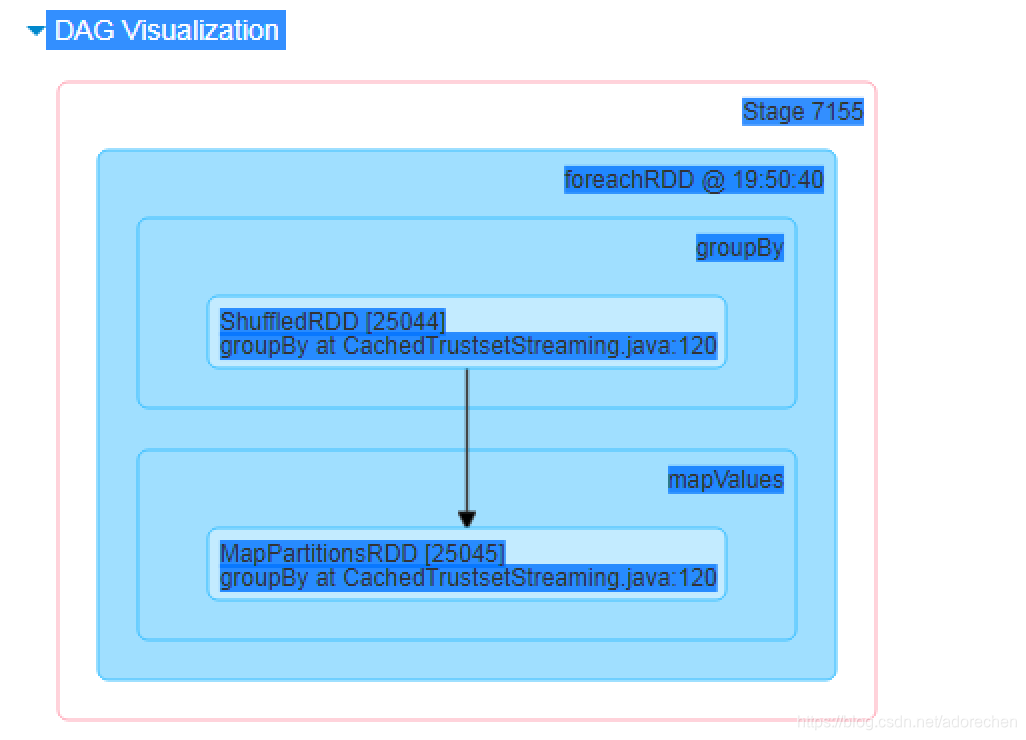
3 Partition
RDD划分成逻辑分区,每个分区中包含rdd的部分数据。初始化的时候,分区数目由getPartitions确定,数据有compute确定。运算过程中由Partitioner确定分区数目和数据。
详情参看:https://blog.youkuaiyun.com/adorechen/article/details/106202860
4 Task
Task是spark的任务运行单元,通常一个partition对应一个task。有失败时另行恢复。
5 Executor
这里的executor不是指的yarn中的node,而是指spark 总真正执行task任务的core。
曾经碰到的一个问题:
task上基本对应一个partition,每个partition有自己的index id,某特定index的partition是否可以在固定的executor上执行?
1). HashPartitioner --> Partition
由相同的HasnPartitioner shuffle 数据都会到相同partition index (partitionId)的partition中。
2)由Partition生成的Task 到 Executor路由分配
partition 生成的task 是否会路由到相同的executor上执行,取决于partition中数据是否位于该executor上。一般是不会固定该executor上。所以表现结果就是task(partition) --> executor 随机分配。
举个栗子:
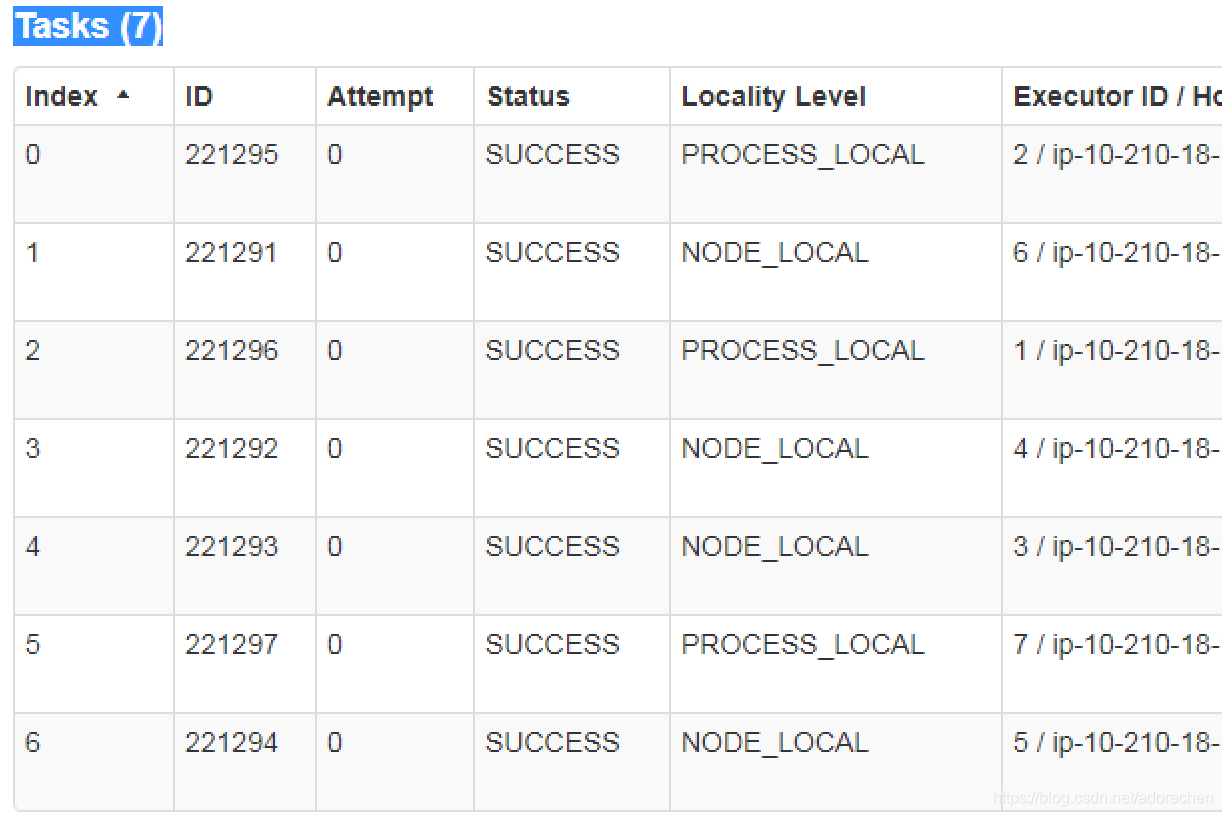
第一次7个partition对应的任务 0-6, 分配到executorId: 2,6,1,4,3,7,5来执行。
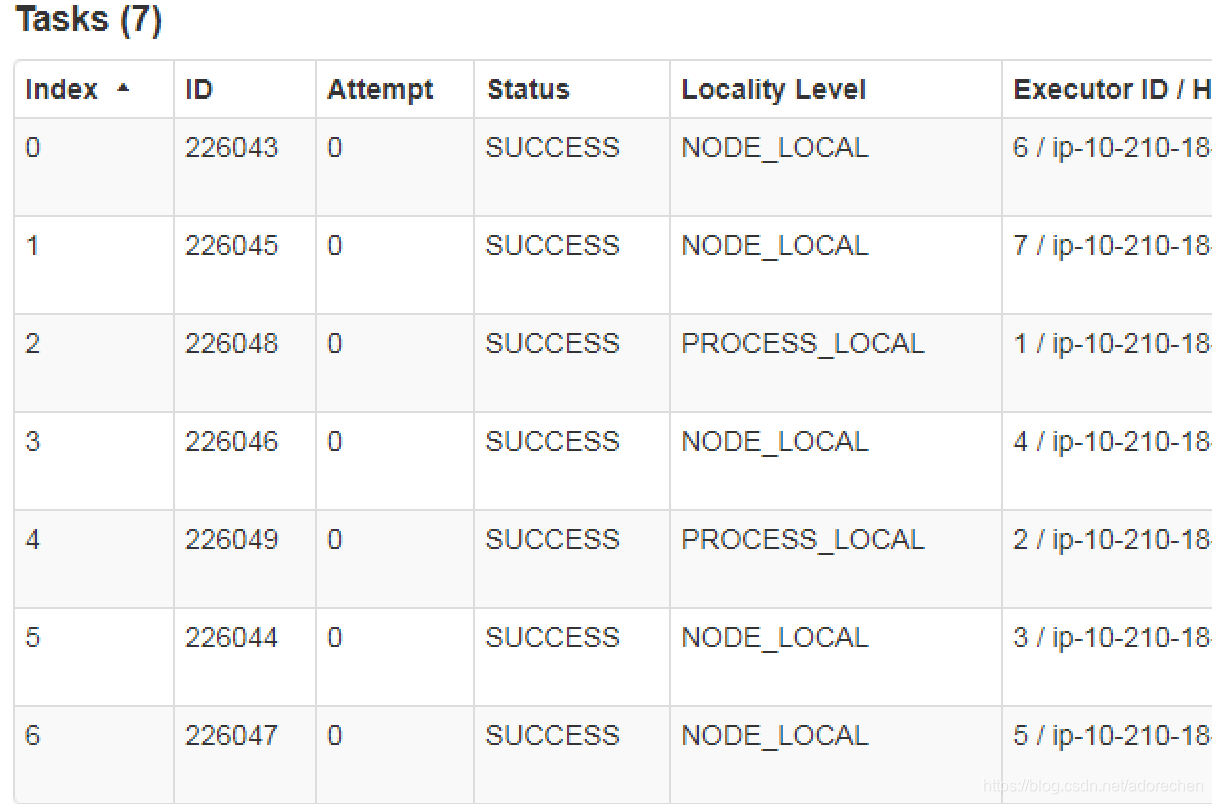 第二次同样的7个index的partition分配到executorId:6,7,1,4,2,3,5;
第二次同样的7个index的partition分配到executorId:6,7,1,4,2,3,5;
可以看出相同index的parition(task)并没有被分配到相同的executor上来执行。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









