




最近在做一个分布式任务时,遇到一个需求:
一个用户member,可以有多个登陆ip,并把这些ip加入到可信ip集合中。可信集合上限100,当超过100时,对已经存在的100个进行LRU(last recent unused)替换。
方案设计思路:
使用spark streaming 来接收用户登陆事件流,并把每个登陆ip写入到HBase的表(limit_control)中。该表以member作为key,ip作为column family,然后具体的ip值作为column,用户登陆时间作为timestamp.这样可以完美去重。
但是怎样进行100的上限控制呢?
初步的想法是,先把用户member 通过groupByKey shuffle到不同的executor上,然后再对应的executor上使用对应部分key的cache进行ip数目统计和limit控制。
实现的核心代码如下:
Streaming中处理代码
stream.foreachRDD(rdd -> { try { // extract all activity events rdd.flatMap(record -> { String topic = record.topic(); TopicHandler handler = HandlerFactory.getHandler(topic); return handler.handle(record.value()); }).groupBy(act -> act.getMemberSrl()) // process all activities .foreachPartition(itr -> { while (itr.hasNext()) { Iterable<Activity> acts = itr.next()._2; Processor.process(acts); } }); } catch (Exception e) { log.error("consumer rdd error", e); } });
processor中核心代码:
String cacheKey = null; try { Iterator<String> itr = trustMap.keySet().iterator(); while (itr.hasNext()) { cacheKey = itr.next(); // map entry => (trust value (uuid/pcid/ip value), last active time) Map<String, Long> trustSet = getCache().getTrustSet(cacheKey); // new trust set in current partition Map<String, Long> partiTrust = trustMap.get(cacheKey); String trustType = getCache().getTrustType(cacheKey); Integer limit = DurationLimit.getLimit(trustType); // up to limit, remove LRU item in trust set if (partiTrust.size() + trustSet.size() > limit) { List<Activity> partDelList = getDeleteList(partiTrust, cacheKey, limit); delList.addAll(partDelList); } else { // combine trust set, UPDATE CACHE TRUST SET trustSet.putAll(partiTrust); } } } catch (Exception e) { log.error("get trust set from cache error, cacheKey: {}", cacheKey, e); }
每个函数都单元测试完成,信心满满。但是现实很残酷, 依然有很多数据超过100的限制,这是为什么呢?
问题原因:
通过对具体task(partition)到executor的路由关系查询,发现index = 0 的partition 并不总是有executor = x 的节点来运行,这样的路由分配是基于数据local特性来确定的,也就是随机分配的。所以基于单点JVM 思路的cache方案最后的结果就是,有多个节点上存在cache导致cache不能有效控制limit。
举个栗子:
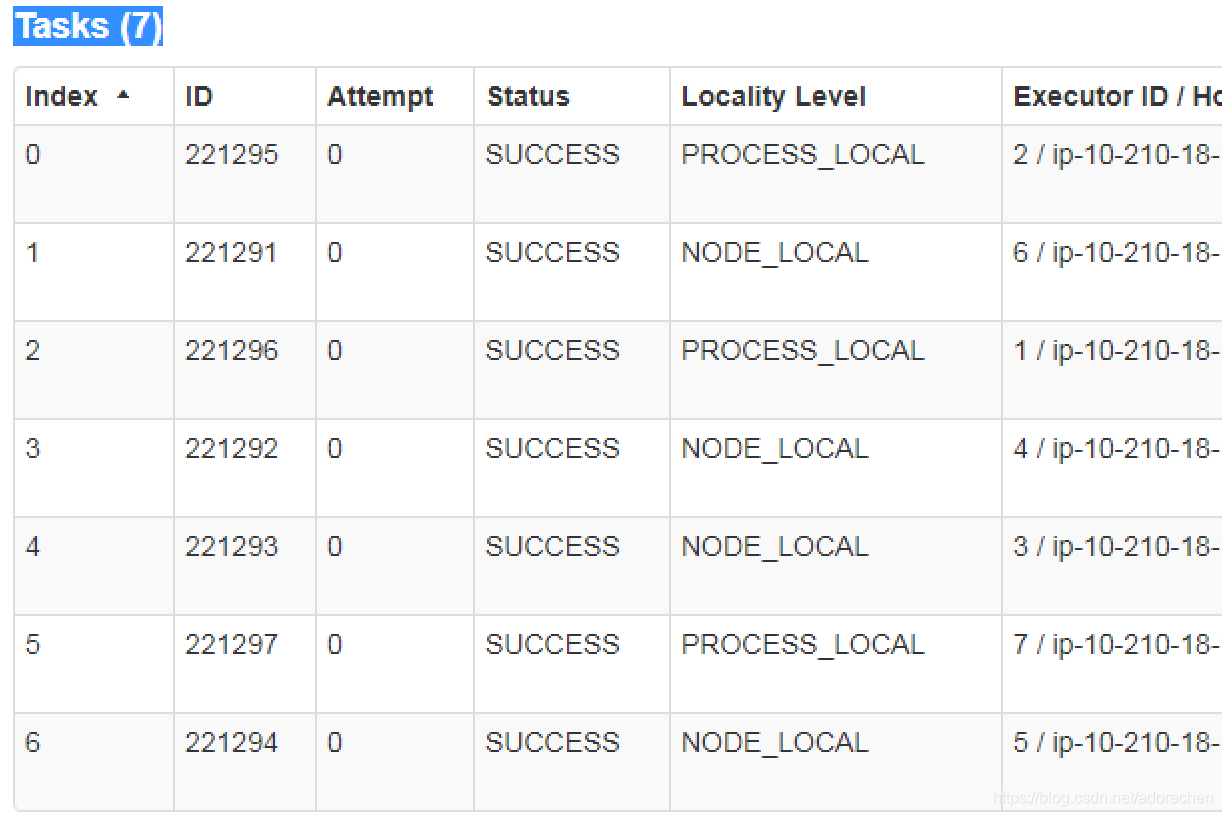
第一次7个partition对应的任务 0-6, 分配到executorId: 2,6,1,4,3,7,5来执行。
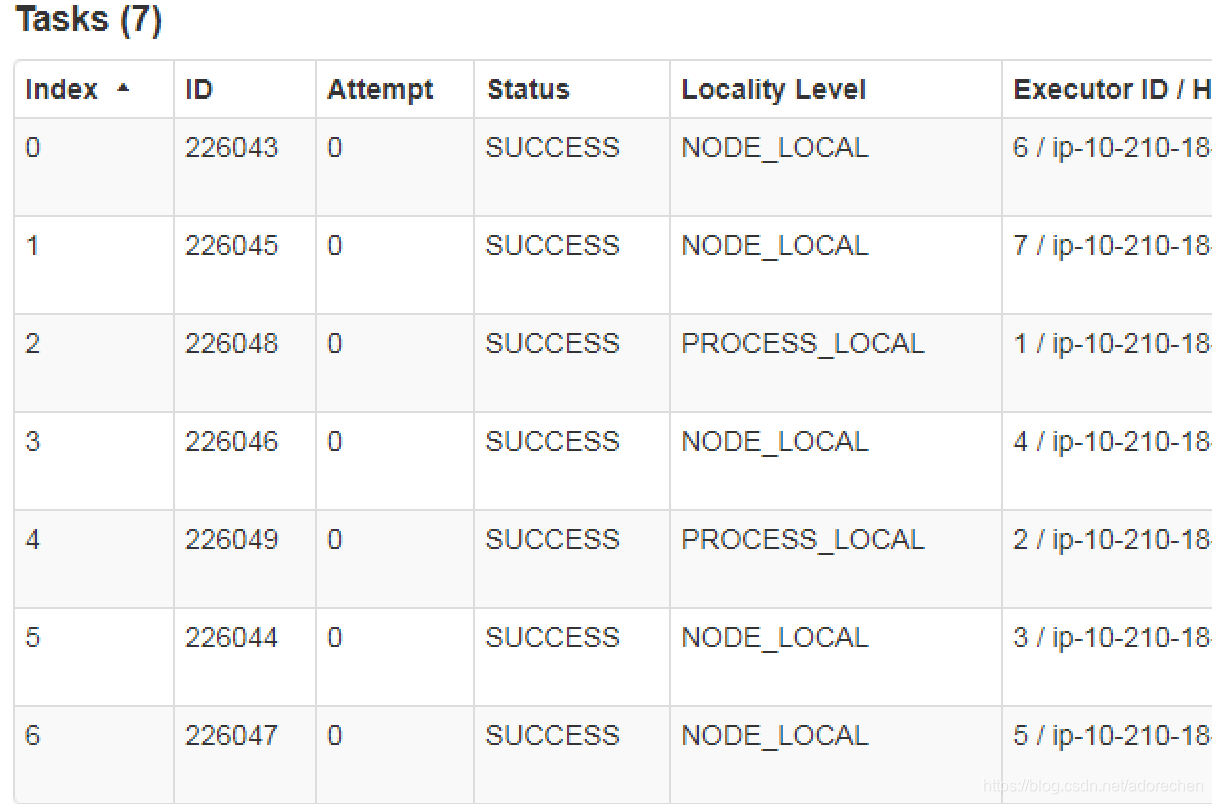
第二次7个partition对应的任务 0-6, 分配到executorId:6,7,1,4,2,3,5来执行;
可以看出相同index的parition(task)并没有被分配到相同的executor上来执行。
参考文章:
https://blog.youkuaiyun.com/adorechen/article/details/106317955
In Spark, custom
Partitioners can be supplied for RDD's. Normally, the produced partitions are randomly distributed to set of workers. For example if we have 20 partitions and 4 workers, each worker will (approximately) get 5 partitions. However the placement of partitions to workers (nodes) seems random like in the table below.trial 1 trial 2 worker 1: [10-14] [15-19] worker 2: [5-9] [5-9] worker 3: [0-4] [10-14] worker 4: [15-19] [0-4]This is fine for operations on a single RDD, but when you are using
join()orcogroup()operations that span multiple RDD's, the communication between those nodes becomes a bottleneck. I would use the same partitioner for multiple RDDs and want to be sure they will end up on the same node so the subsequent join() would not be costly. Is it possible to control the placement of partitions to workers (nodes)?desired worker 1: [0-4] worker 2: [5-9] worker 3: [10-14] worker 4: [15-19]
结论
HashPartitioner 可以shuffle数据到固定index的partition中,但是固定index的partition不会一直路由到相同id的executor上。所以单节点cache方案在spark program是行不通的。
最终的解决方案:
在每个executor上写数据,并把每个member对应的ip数目通过累加器返回到driver上,通过driver上的cache(只有一个节点,cache一定同步)来解决100的限制。

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









