







无论在知乎还是各类数据库技术博客/公众号上,相信大家看到的绝大多数关于MySQL的技术分享,都和Innodb存储引擎相关,事务、锁、btree、MVCC等等,但关于MySQL的计算层的介绍则少之又少。。。
这并不奇怪,和Innodb相比,MySQL的优化、执行代码实在是让人不敢恭维,从事过相关研发的同学一定深有体会,代码是多么不好理解,二次开发是多么的艰难。。。就连8.0的主coder Steinar Gunderson,在离开Oracle时也疯狂吐槽并引起了不小风波。在国内由于历史原因,MySQL的流行度如此之高(e.g 互联网相关行业),以致产生了不少基于MySQL做深度优化和改造的需求。随着数据量的爆发和workload模式多样化,MySQL在优化器上的短板越来越凸显,相信有一定研发实力的团队都考虑过如何从根本上解决MySQL的优化器问题(阿里也是一样。。方案也不止一种)
从头重写优化器的工程复杂度很高周期也长,一个更吸引人的思路自然是外挂optimizer,将优化工作托管给更为强大的外部组件,最终计划传回MySQL执行来保证兼容性。这篇文章是读了华为在2022年EDBT上的paper 《Integrating the Orca Optimizer into MySQL》,介绍了他们探索把GPOrca集成到MySQL的一些工作,这也是我所知道的第一个"成功"把第三方优化器和MySQL原始codebase融合的案例,之所以打了引号,后面会详细解释。
另:关于MySQL计算层的发展历史,可以看下Norvald Ryeng这个cmu talk。
动机
各个云厂商都在提供基于计算存储分离的云原生OLTP数据库 (Aurora/PolarDB/Taurus…),随着底层存储容量的扩展,用户的业务中也越来越多的混杂了对于大数据量的复杂分析查询,这对optimizer提出了更高的要求。MySQL的优化器并不是为分析型查询而设计的,如果是简单的OLTP workload那效果相当不错,但AP查询则经常容易计划偏差,可能会产生几个数量级的性能差异。
大体来说,MySQL的优化器存在如下一些问题:
- 优化是局部的,只能一个query block一个query block的完成,虽然有subquery -> semi-join/derived table这种跨block的变换策略,但也是完全固化的并只针对了最简单情况(SPJ subquery),此外每个block内,也一定是join -> group by -> order by这样的优化顺序
- join ordering只支持left-deep tree,不支持bushy join,且使用的是greedy的搜索算法,无法保证得到最优plan
- 对谓词的处理不完善,某些情况下无法支持common expr的提取,例如 (A AND B)OR (A AND C) => A AND (B OR C),可能导致执行效率差
- 不支持aggregation <-> join的placement,group by无法推到join下方
- Filter无法推到group by下方(derived table可以,subquery不可以),即如下形态:
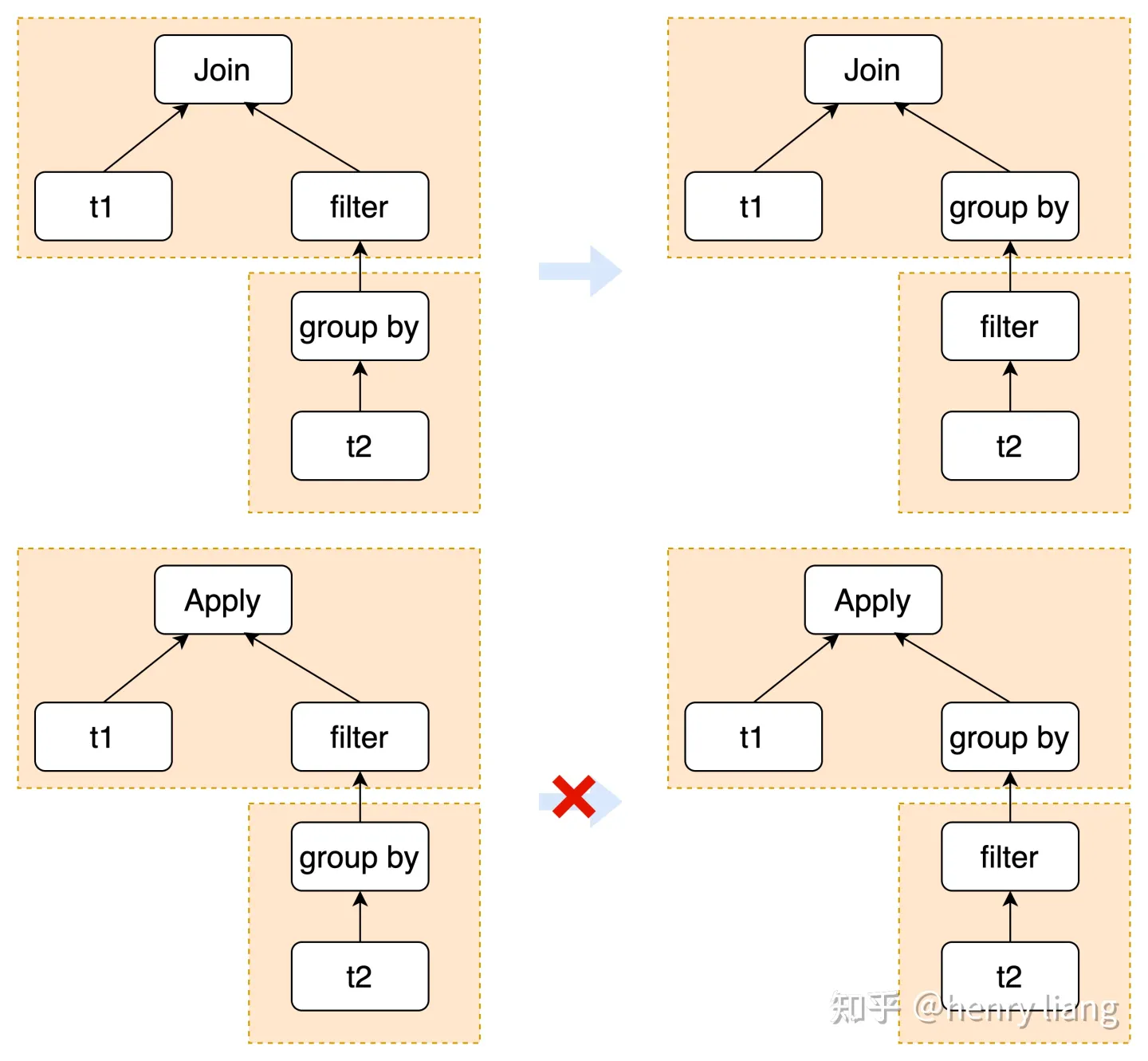
对原有的optimizer做补强是非常痛苦的,其框架本身没有什么扩展性,没有类似rule-based transformation这样的统一流程,实现类似eager aggregation/subquery unnesting等变换只能case by case的完成,且transformation之间缺乏统一的联动,无法灵活的选择组合方式等。此外整个优化流程中,各个步骤之间并没有清晰的边界,如逻辑变换和语义解析有交错,各算子的优化有交错,Non-SPJ的算子优化流程完全基于规则,且与执行结构的生成耦合。
但Orca则完全没有这个问题,基于Cascades最大的优势就是扩展性和一致的优化流程。同时Orca本身的设计就是插件式的,提供了3个接入点,使其可以集成到任意DBMS当中(理论上)。因此主要工作也集中在这3个点上:
- MySQL的AST -> Orca logical operator tree的翻译
- Metadata provider的实现
- Orca physical plan -> MySQL skeleton plan的翻译
后续再基于这个skeleton plan继续走MySQL的处理逻辑,生成实际的executable plan。
关于Orca的介绍可以看这篇文章:
henry liang:Orca: A Modular Query Optimizer Architecture for Big Data62 赞同 · 2 评论文章正在上传…重新上传取消
项目背景
这个项目是基于TaurusDB实现,codebase是MySQL8.0,关于Taurus不太重要,这里就只给个框图:
MySQL优化器的流程图,和对应的关键函数入口大致如下:
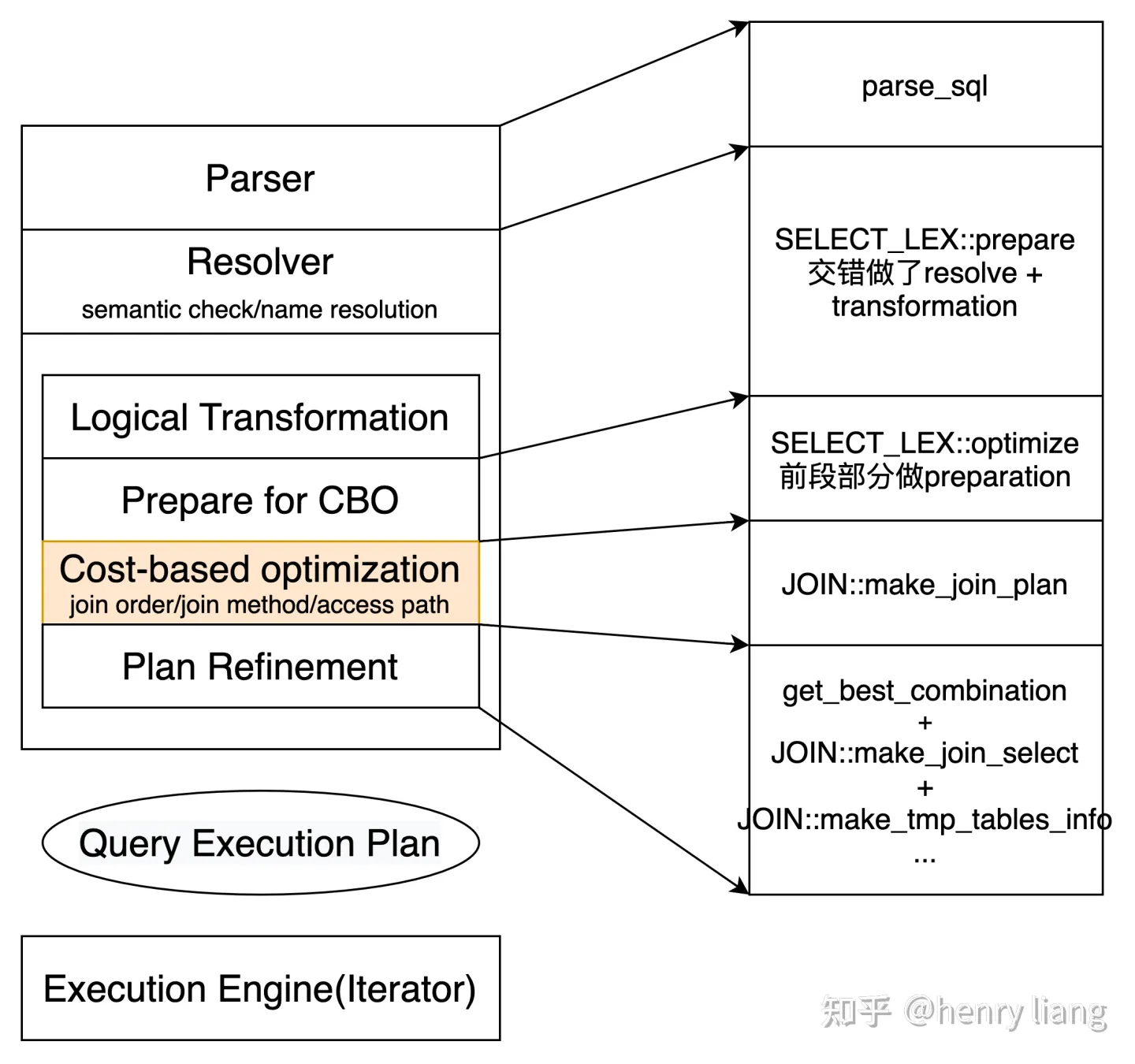
- resolve阶段要做语法/语义检查,name解析,访问控制,表达式溯源等,同时还会完成一些logical transformation比如condition的化简,derived table展开,谓词下推derived table,subquery -> derived table/semi join/anti semi-join,nested join的消除等
- CBO的主要工作就是完成join ordering,确定join method,每个table的access path,这个过程在每个query block内部独立完成。paper中的工作主要就是将这部分交给Orca完成!
- Orca优化的结果需要转换为MySQL可以识别的skeleton plan(JOIN::best_positions数组),后续交给MySQL来完成物理计划的生成
- 从join ordering出来应该是对接到了get_best_combination的位置,根据best_positions生成对应的join_tab -> qep_tab数组,同时把谓词下推到对应的table上(单表cond/join cond)
- 再后续的处理会优化group by/distinct/order by等,并生成对应的执行结构
大体流程如上,而paper中介绍的替代工作主要发生在make_join_plan()这个函数中,也就是完成join ordering + join method + access path选择的工作。
此外还有额外一些限制,如:
- 只支持对SELECT的优化 (DML不支持),且如果包含system table的query不走Orca
- 有recursive CTE不支持
- 有GROUPING行数且参数不止一列时,不支持
- 如果orca在做join ordering过程中,改变了query blocks的整体结构(猜测是消除/产生新的qb),则不允许,会fallback回MySQL优化
- 使用join table数量作为复杂度的衡量标准,目前超过3个就认为是complex query
由此可以看到,这里集成的工作只做了join ordering这一部分,当然join ordering对于查询的性能可以说是最为重要的,但从工程的角度,却也是相对最容易的部分。
集成工作
总体的集成架构如下:
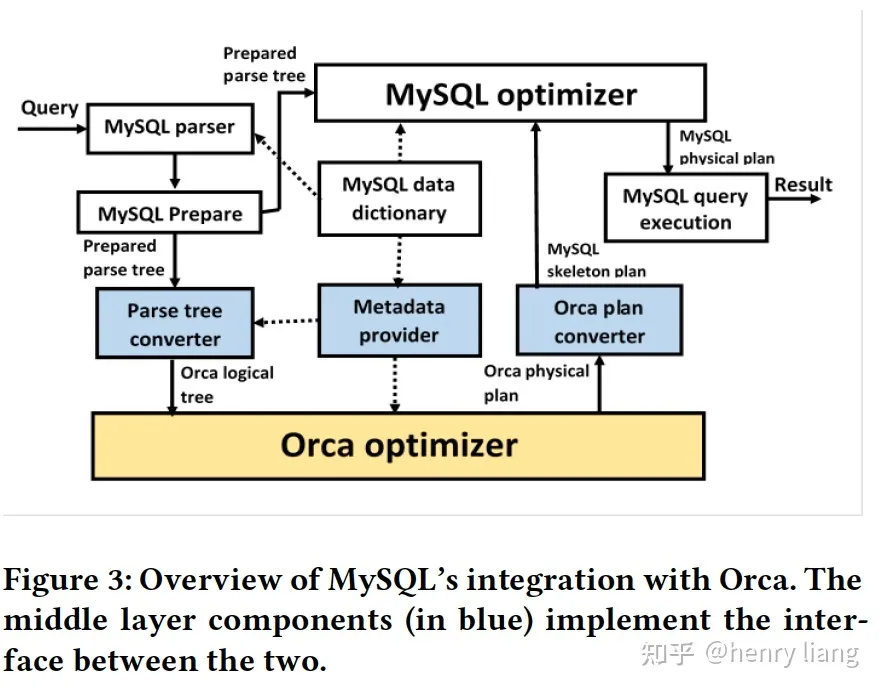
其中蓝色的3个部分就是三个接入点
- parse tree converter将经过prepare和transform之后的AST (SELECT_LEX)作为输入,直接转换为Orca可以识别的Logical Operator tree,这里没有使用DXL中间结构,此外这个过程中,converter会调用MD provider获取查询中table/column等的元数据OID,绑定到Logical tree上
- metadata provider在Orca优化中,按需提供更多细节的信息,包括统计信息,expression信息,类型信息等,这部分仍使用DXL描述
- Orca优化完成后,将生成的physical plan转换为MySQL内部的结构描述,叫做skeleton plan,主要是把join order/join method/access path/cost/row count等信息填充到best_positions数组中,但谓词/group by/order by/投影列等信息,并不由Orca提供,MySQL自己处理,这里转换过程也不用DXL
- MySQL基于skeleton plan进入后续处理流程,主要包括谓词放置(make_join_select) ,aggregation, sorting,windows(在make_tmp_tables_info)等,仍然遵循MySQL原有的 join -> aggregation -> order by+limit的流程
带来的收益举了TPC-DS Q72的例子:
select i_item_desc
,w_warehouse_name
,d1.d_week_seq
,sum(case when p_promo_sk is null then 1 else 0 end) no_promo
,sum(case when p_promo_sk is not null then 1 else 0 end) promo
,count(*) total_cnt
from catalog_sales
join inventory on (cs_item_sk = inv_item_sk)
join warehouse on (w_warehouse_sk=inv_warehouse_sk)
join item on (i_item_sk = cs_item_sk)
join customer_demographics on (cs_bill_cdemo_sk = cd_demo_sk)
join household_demographics on (cs_bill_hdemo_sk = hd_demo_sk)
join date_dim d1 on (cs_sold_date_sk = d1.d_date_sk)
join date_dim d2 on (inv_date_sk = d2.d_date_sk)
join date_dim d3 on (cs_ship_date_sk = d3.d_date_sk)
left outer join promotion on (cs_promo_sk=p_promo_sk)
left outer join catalog_returns on (cr_item_sk = cs_item_sk and cr_order_number = cs_order_number)
where d1.d_week_seq = d2.d_week_seq
and inv_quantity_on_hand < cs_quantity
and cast(d3.d_date as timestamp) > cast(d1.d_date as timestamp) + interval 5 days
and hd_buy_potential = '>10000'
and d1.d_year = 2001
and cd_marital_status = 'D'
group by i_item_desc,w_warehouse_name,d1.d_week_seq
order by total_cnt desc, i_item_desc, w_warehouse_name, d_week_seq
limit 100;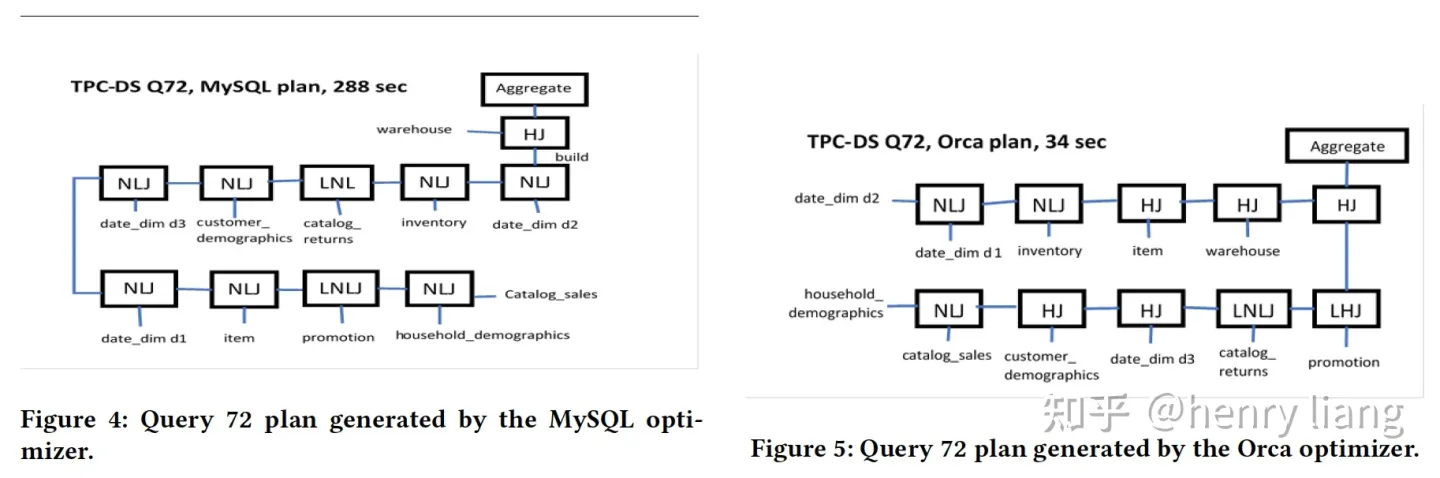
执行计划从左侧变为了更优的右侧,可以看到join顺序不同,从left-deep -> bushy并更多使用了hash join,速度从288sec -> 34sec。
SELECT_LEX -> Orca logical operator tree
和Orca paper中依赖DXL不同,这里直接在内存中做结构转换,完成prepared AST(SELECT_LEX) + OID => logical operator tree,这里paper提到一个细节,就是在完成SPJ subquery -> semi/anti-semi join的转换时,由于转换后的谓词(内层的+相关的)都放到where条件中,而其他inner join的谓词都在ON/where中,这里需要专门做下谓词下推的处理,推到对应的table上,因为在进入Orca后,Orca并不再做predicate pushdown的优化,只做join ordering,所以要针对新生成的semi-join结构,在MySQL侧提前做掉。
在SELECT_LEX -> operator tree的转换时,遵循如下结构:
- FROM , 用来描述TABLES
- WHERE(1) 描述单表cond + join cond
- window function(1) 如果没有group by只有windows,这里生效
- WHERE(2) 没有group by只有windows时,还有having,这里描述having
- SELECT(1) 在group by之前生效的投影列
- GROUP BY group by算子
- SELECT(2) group by之后生效的投影列,如聚集列
- HAVING group by之后的having
- Window functions(2) group by之后的windows
- ORDER BY order by
- SELECT(3) 剩余的常量投影列
- LIMIT limit
例如TPC-H Q4:
select
o_orderpriority,
count(*) as order_count
from
orders
where
o_orderdate >= '1994-04-01'
and o_orderdate < date_add('1994-04-01', interval '3' month)
and exists (
select
*
from
lineitem
where
l_orderkey = o_orderkey
and l_commitdate < l_receiptdate
)
group by
o_orderpriority
order by
o_orderpriority;转换为Orca的operator tree后形式是:
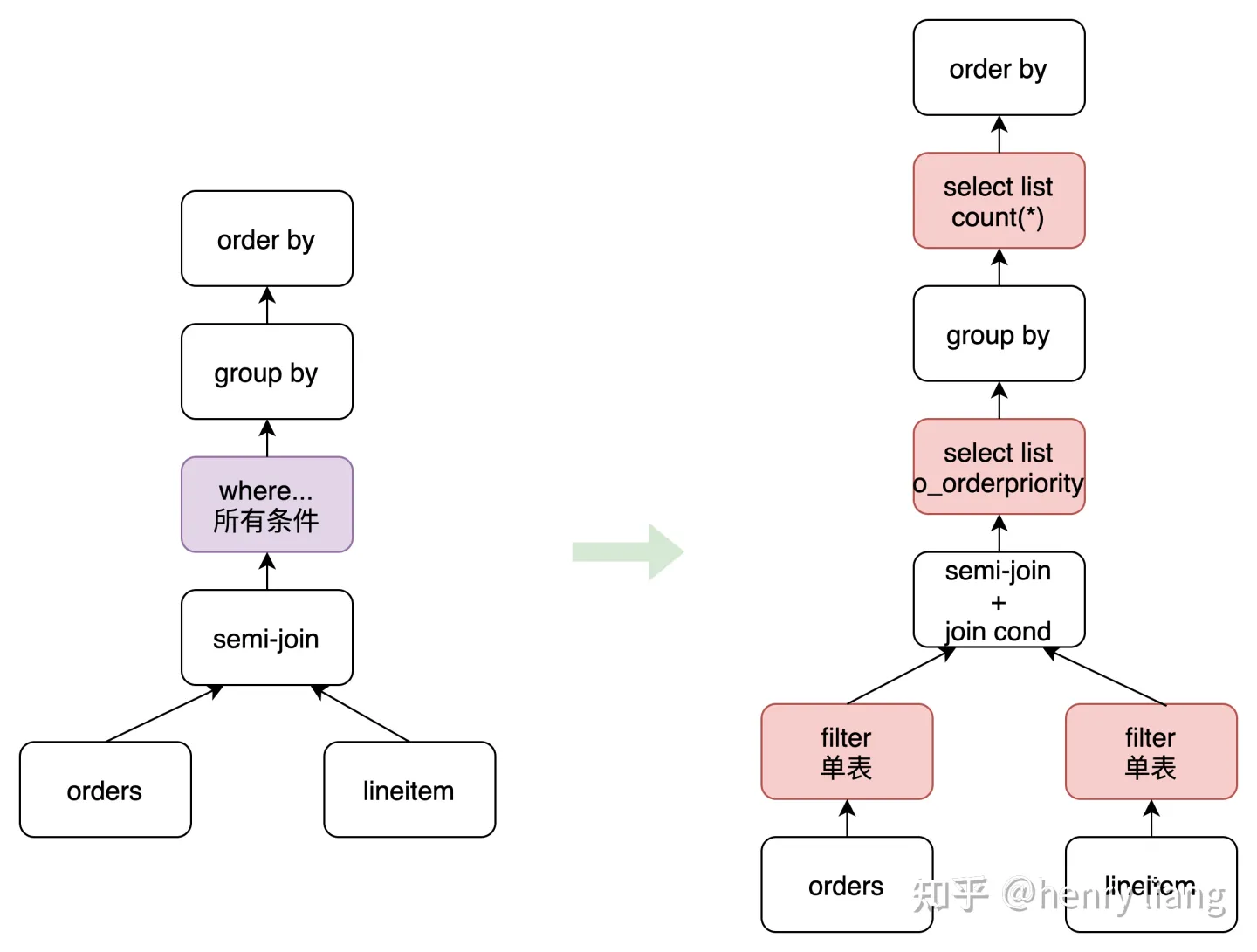
在converter中,就把转换出的semi-join对应的条件下推到了各个表上,并且根据group by前后把投影列做了拆分,在生成logic plan tree时,对其中每个table descriptor,会增加一个指针指向对应的MySQL TABLE_LIST对象,这个descriptor会一直存在直到最终优化生成Orca physical plan,这样在转换回MySQL plan时就可以更方便的找到映射关系。在转换中也会请求Metadata provider获取相关的OID(table/column/type...),例如传递给MD provider table name,得到其OID。后续在优化中需要获取更加详细的元信息/统计信息,Orca要基于OID来获取。
Orca -> MySQL plan converter
在Orca优化完成后会生成其对应的physical plan tree(MEMO中),真正变成MySQL executable plan需要两步:
- Orca physical plan tree -> MySQL skeleton plan (converter完成)
paper中介绍skeleton plan 主要就是join order/join method/access path/cost/rowcount等信息,保存在JOIN::best_positions数组中,描述最优join plan
例如TPC-H Q17
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#12'
and p_container = 'WRAP CAN'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);在Orca优化后的physical plan简化版:
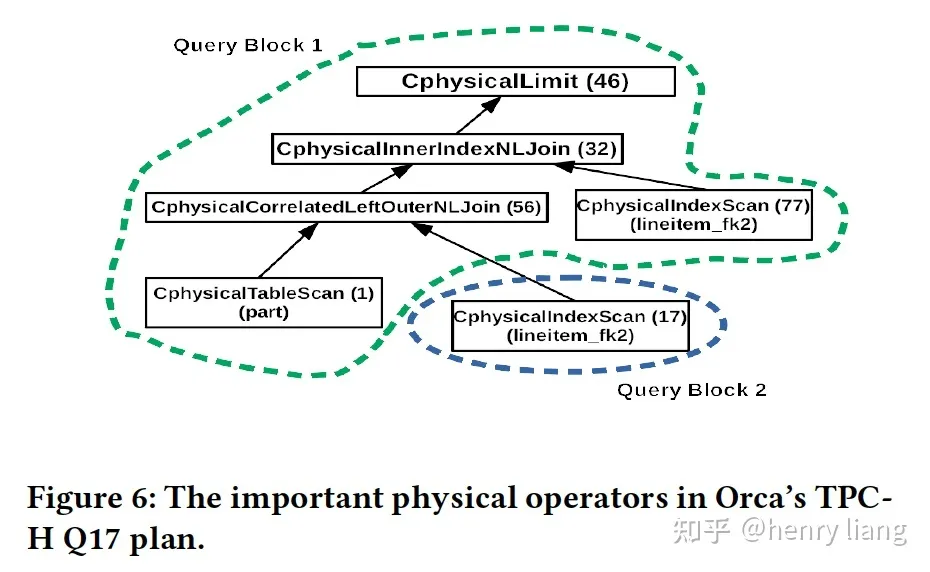
基于orca plan生成skeleton plan的过程是2-pass的
- Pass 1
- 先前序遍历整个orca plan tree,如图中,通过 46 -> 32 -> 56 -> 1到达第一个leaf node 1(table part),过程中的node要放入query block 1
- 处理leaf node 17 ( lineitem表),其对应的TABLE_LIST记录了所属的SELECT_LEX,这里会发现不属于当前的query block,因此是一个子查询,创建新的query block 2并包含1
- 对应这种谓词中subquery的情况,倾向于仍使用subquery来描述,但这里subquery的相关条件是l_quantity < <subquery>.xxxx ,而在遍历到17时,外层的l_quantity所属的lineitem表还没遍历到(77),这表示join处理顺序上17之后才能看到77,因此17只能转换为derived table,其由于是correlated的,需要转换为对derived table的lateral join
- 注:如果Orca优化后17在77之后出现,则17仍然可以子查询的形式出现,不用转为derived table
- Pass 2
- 第2次前序遍历是要填充JOIN::best_positions数组,由于前面已经拆分了query block以及算子的不同归属,每个query block都有其对应的best_positions,各自按照前序遍历的顺序填充,包括table_name/access method/cost/row_count..
对Q17来说,如下:
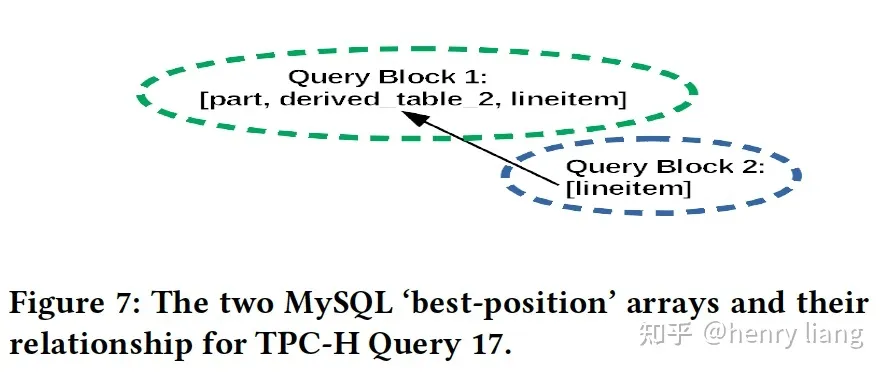
SELECT_LEX 1包含 [part, derived_1_2, lineitem],且derived_1_2是一个lateral derived table
SELECT_LEX 2包含 [lineitem]
2. MySQL skeleton plan -> MySQL physical plan
这里主要follow MySQL从make_join_plan之后,沿着get_best_combination的逻辑向下走就可以了,基本没有大的变动,做如下一些事情:
- 生成join_tabs数组,为后续的qep_tabs做准备
- 根据优化的join顺序处理where_cond/join_cond
- make_join_select()将condtition重新下推到所属的table上,包括单表cond/join cond
- optimize_distinct_group_order() 对group by/order by做优化或消除
- make_tmp_tables_info() 确定所有Non-SPJ算子(group by/distinct/window/order by)的执行方式并生成对应的执行结构
有个细节,如果Plan是Orca生成的,则原来MySQL可能有将hash join -> NLJ的情况,这里将不再遵循,强制用hash join。
由此产生的Q17 plan如下:

其中蓝色标注的地方,将Orca中的CorrelatedLeftOuterNLJoin转换为了Lateral inner join因为where condition “l_quantity < <subquery>.xxxx” 是null-rejecting的,此外红色的Invalidate表明是lateral join。
Metadata provider
对于和Orca集成紧密的Postgres来说,metadata provider对于很多函数提供了callback function pointer,用来做表达式计算(常量折叠?)和type casting,但对于MySQL这些操作会在join ordering之前/之后自己完成,所以省掉了这个callback的情况。
但仍然要提供关于table/column/data type/expression/functions/statistics的OID,因此需要一种OID的生成机制,并把OID信息集成到DXL里提供给Orca。
- types and type categories
MySQL8.0本身有31个类型,而在描述表达式类型时,可能会是这31个类型和操作符的任意组合,这会导致表达式OID的爆炸,为此这里做了优化,将type粗粒度的划分为12个catogories,例如datetime相关的/blob相关的…这样可以大量减少表达式类型的数量。对于每种data type,MySQL要提供的细节信息包括:
name/length/是否是传值的/是否是文本/type modifier(DDL中指定) ...
- expressions
- 算术表达式,算术运算符有 + - * / % 5种,因此一共是12 * 12 * 5 = 720个类型,对应720个OID,生成方法是基于一个arith_base值,从0 -> 719累加enumerate ID,这样就建立了(i,j,k)三元组与enumerate ID的对应关系
- 比较表达式
- 聚集表达式,都是类似的处理,但聚集中,参数有可能是 * / column/expression这样的,两者语义稍微不同(null值处理),单独用STAR/ANY两种category来描述,这样有14 * 6种类型
- 表达式的交换/取反,Orca在优化中可能对表达式做些rewrite来处理不同join可能和索引选择可能,重写后的expression也要获取对应的OID来表示 (注:部分运算符合交换律,只有比较运算可以取反)
生成rewrite之后的OID也很容易:
- 根据当前表达式类型和OID获取其 enumerate ID = OID - base
- 根据 enumerate ID 映射回对应的(i,j,k)三元组,交换后变为(j,i,k)三元组
- (j,i,k)映射新的enumerate ID , OID = new enumerate ID + base
- 对于无法做rewrite的expression,返回无效OID即可
- Functions
Orca中的function分为2类:
- mapped functions,也就是expression
- regular functions,只在SQL指定的标准操作: EXTRACT,SUBSTRING,CAST,ROUND,UPPER,CONCAT,ABS….,也有对应的OID
- Relations/Statistics/Histograms
- 关于表,其细节的信息包括:table name,列,列类型,cardinality, 列的NDV,列null值数,列histogram,indexes …
- 关于histogram,Orca支持的singleton和equi-height两类,MySQL也都支持,信息也都类似,但MySQL有个限制,如果column是unique的,不允许建hist,这里打破了这个限制。另外对于string histogram,Orca只支持singleton形式,因为它是用hash func将string映射成value再构建的,因此只能做等/不等的比较,不适合range扫描,但MySQL没有做hash而是使用了原值,因此可以描述range,可以建等高hist。这里对Orca的string hist做了增强,使其可以支持等高hist,方法是对于MySQL等高hist端点上的string,转换为64bit的signed int,并在比较时使用一个compare function,这个function是保序的,可以反应原有string的大小关系,但目前的实现只能处理固定的长度,所以在common prefix都一样的string情况下,可能区分不出来。
- OID layout
前面已经介绍了OID的分配策略,如下:
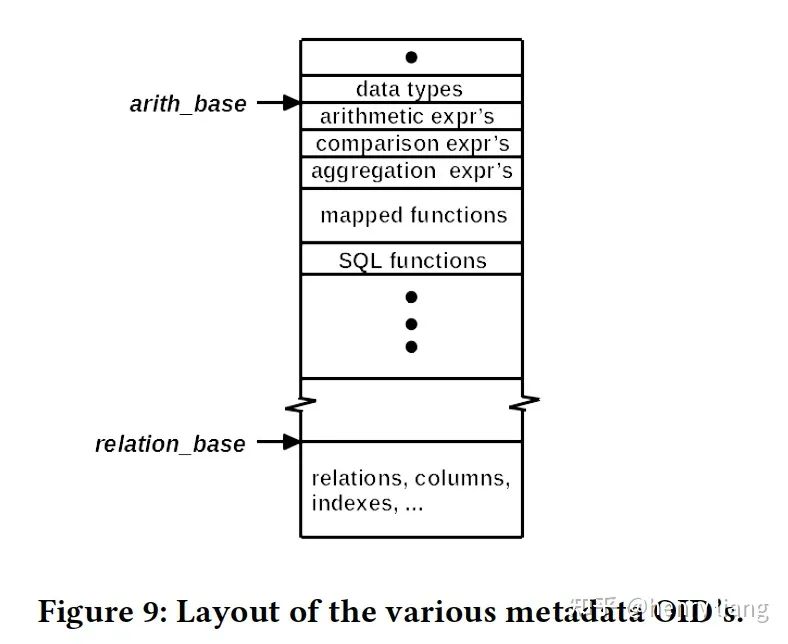
可以看到两个点:
- 对于data types/expression/function这些,每个OID代表一种类型,而不是一个具体的表达式实例,因此数量是固定的,OID分配区间可以紧邻
- 对于table/column/indexes这些,每个OID代表一个具体的对象,而不是类型,因此数量是不确定的,需要在各个base之间保留足够大的GAP,保证OID不会重叠
仍以TPC-H Q17示例整个优化流程:
- MySQL parse tree -> Orca logical operator tree时,会向MD provider请求例如 lineitem, part以及对应的indexes等的OID
- 在Orca优化中,会基于这些OID,获取更细节的元信息,如lineitem某些列的histogram,某些index上的统计值
- 也会请求expression OID,例如 p_container = “SM_PKG”的OID就是STR_EQ_STR,在优化中对其可能做交换、取反,也要获取对应OID。 (??如何使用表达式OID??)
工程经验
- 对data type的粗粒度分类,需要能让Orca区分出宽度从而选择不同索引
- 对MySQL string的等高histogram,到Orca转换的支持,前面已经介绍
- Orca原生与GP/PG,因此适用于多进程模型,每个进程同时只能执行一个优化,但MySQL是多线程,必须要适配
对MySQL的改造
- MySQL的执行层原生不支持bushy plan,因此需要对转换出来的skeleton plan(best_positions)做一些扩展,使其可以生成bushy join,iterator部分应该也有所扩展
- 对于CTE,如果出现在query的多处,且存在不同谓词 a=5 / a=6这样,那么可以组合为(a=5 or a=6)并下推到CTE当中,这是Orca在rewrite时的一个功能,补充到MySQL中
- 前面提到,Orca对于predicate的处理要更完善,例如(a = b AND c = d) OR (a = b AND e =f)可以转换为 (a = b) AND (c=d OR e=f),将DNF -> CNF并提取了common子表达式,这可以提升谓词计算的效率。MySQL只有当a=b这部分可以使用索引(keyuse)时,才能做这种变换,否则不行,但这个变换总是更优的,因此对MySQL做了增强。
- 前面也提到,对unique column允许建histogram
- Orca可以把having下推到group by下面(having的column是group by column的子集时),但MySQL只能在derived table的情况下做下推,对IN2EXIST的subquery不支持,这里也做了增强,如下:
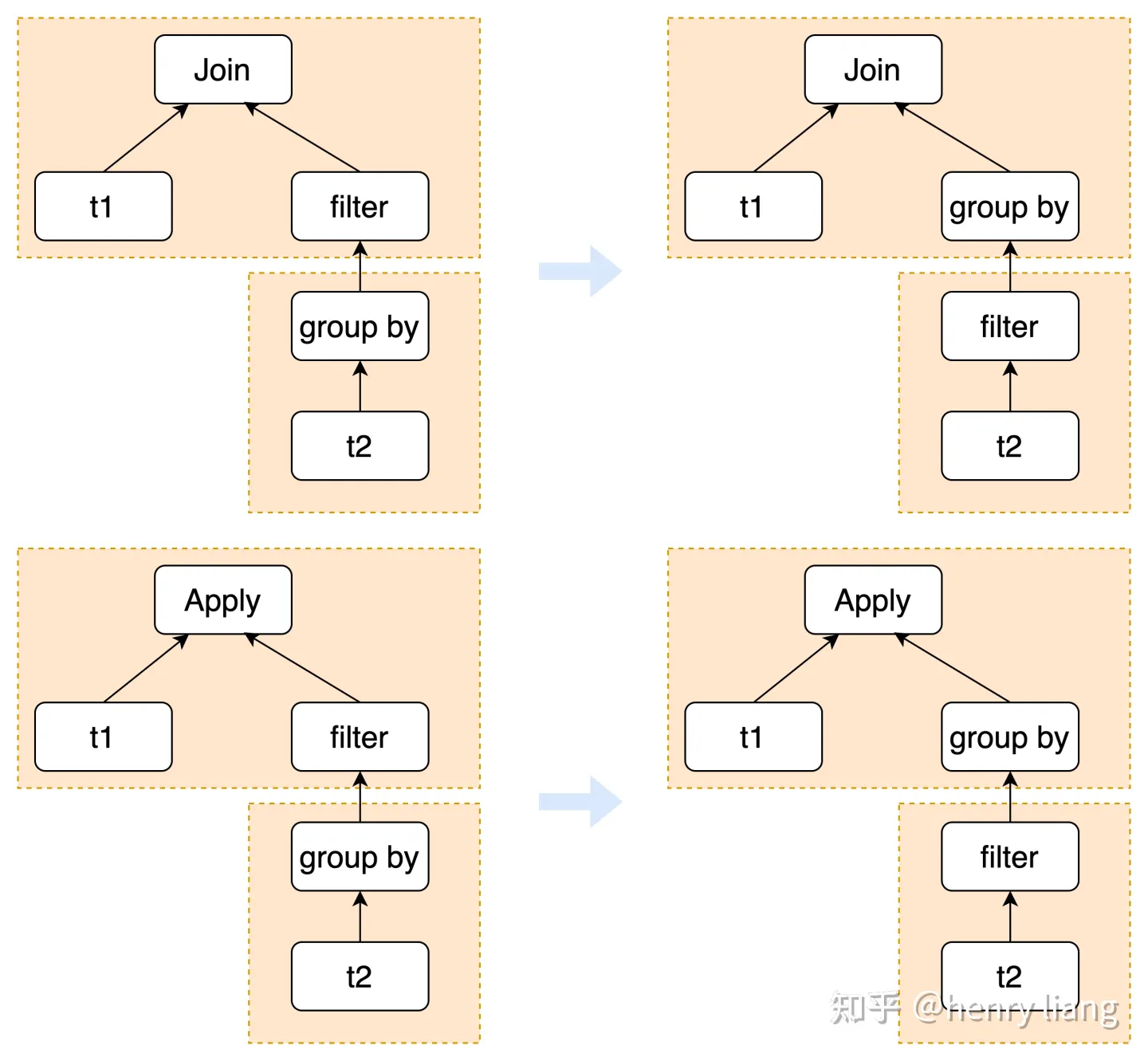
对Orca的改造
- MySQL对于inner hash join比较特殊,左侧是build表,右侧是probe表,但一般数据库都是右边是build左边是probe,因此在Orca优化完后,翻译回MySQL时,要把inner hash join的左右翻转
- Orca只有在某个索引上有predicates时,才考虑使用index scan,但如果是driving table的位置,可能index scan可以提供后续group by/order by要使用的顺序性,因此这时也要考虑index scan
- Orca在优化中有可能会把group by推到Join下面,或者将left semi join (aggregation subquery) 转换为 inner join -> aggregation,这两种都意味着破坏query block结构,因此rule被禁掉
- Orca的hash semi-join,其build表可以支持多表join,但MySQL executor不支持这种模式,因此禁掉
- 对于MPP相关的优化,要有一些调整,由于只应用于单机MySQL,因此所有分布方式都是replicated的,不需要做broadcast/shuffle,但这里MPP相关优化有必要做吗??
- 对于如下这种形式的join序列,增加了apply join <-> inner join的交换律,这样如果Inner join先做,并且是selective join,后面的correlated apply就可以更少的执行,TPC-H Q20/Q21都是基于这个优化实现了加速:
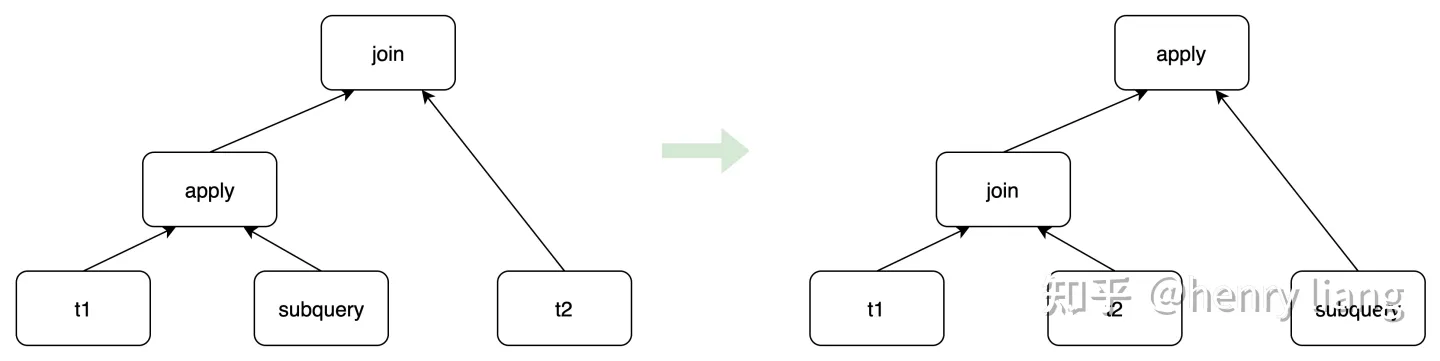
实验评估
paper中用了TPC-H/TPC-DS做了实验,还是取得了不错的效果,大体来说,对于较小查询,有时MySQL会更快,Orca的优化时间相对更长,而且对于简单查询一般MySQL优化效果也不错,对于大的复杂查询,几乎总是Orca效果更好,而且大的查询执行时间更长,Orca的优化时间overhead可以很好的消化掉。
总结
总的来说这是项很有意思的探索工作,虽然采用了保守的方案,没有打破query block之间的屏障但也一定程度上证明了可行性,后续可以做两个方向的尝试:
- 在当前基础上,使用更精确的阈值策略,比如走完MySQL的优化流程,基于串行代价的阈值,判断是否再走一遍Orca
- 代价模型要相应调整,包括cost unit / cost formula,都应该更接近MySQL的执行模式和Innodb storage layout的访问方式
- 更彻底的改造,在生成初步的AST后就进入Orca做全局优化,最后转为MySQL executable plan,这种是理想的终极方案,但复杂度也要高非常非常多
也许大家更期望是上面选项3中的理想形态,但从笔者做MySQL计算层研发的经验来看,这个工程难度实在太大了,paper中只做join ordering的适配相信已经相当复杂,整体替代则完全是另外一件事情,例如:
- 在一个query block内要突破join -> group by -> order by的优化顺序,目前group by/order by/windows的优化并不基于代价而完全是规则决定,而确定优化策略的同时也生成了执行结构(make_tmp_tables_info),突破优化顺序意味着这些NON-SPJ算子的执行层要重构来和优化层解耦
- 原来由prepare阶段完成的case by case的transformation后,整个query的结构就确定了,不同query block的嵌套关系,后续每个block各自的优化流程等。一旦用Orca替换这些都不再成立,执行层要做很大改造
本质上还是MySQL现有的执行器和优化器绑定太紧了,这种绑定历史悠久,替换优化器意味着执行层要大手术甚至重写。因此不确定华为这个项目是否能在选项2上进一步发展,还是截止于此,但如果只停步在join ordering的枚举上,接手官方Hypergraph后续的工作继续搞似乎效率更高?工程复杂度应该也更低些。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











