




“嵌入式大模型”,就是将原本需要在云端高性能服务器(如多块 GPU 集群)上运行的大模型,通过技术优化(如模型压缩、量化、裁剪),“嵌入” 到上述资源有限的嵌入式设备中运行 —— 比如让大模型直接在智能音箱、机器人、工业传感器、可穿戴设备里跑,而不是每次都把数据传到云端处理。
嵌入式大模型的 “3 个核心特征”:为何它是 “嵌入式”,而非 “云端模型”
判断一个大模型是否是 “嵌入式”,关键看它是否满足以下 3 个与 “嵌入环境” 匹配的特征,这也是它与对话大模型(多为云端)的核心区别:
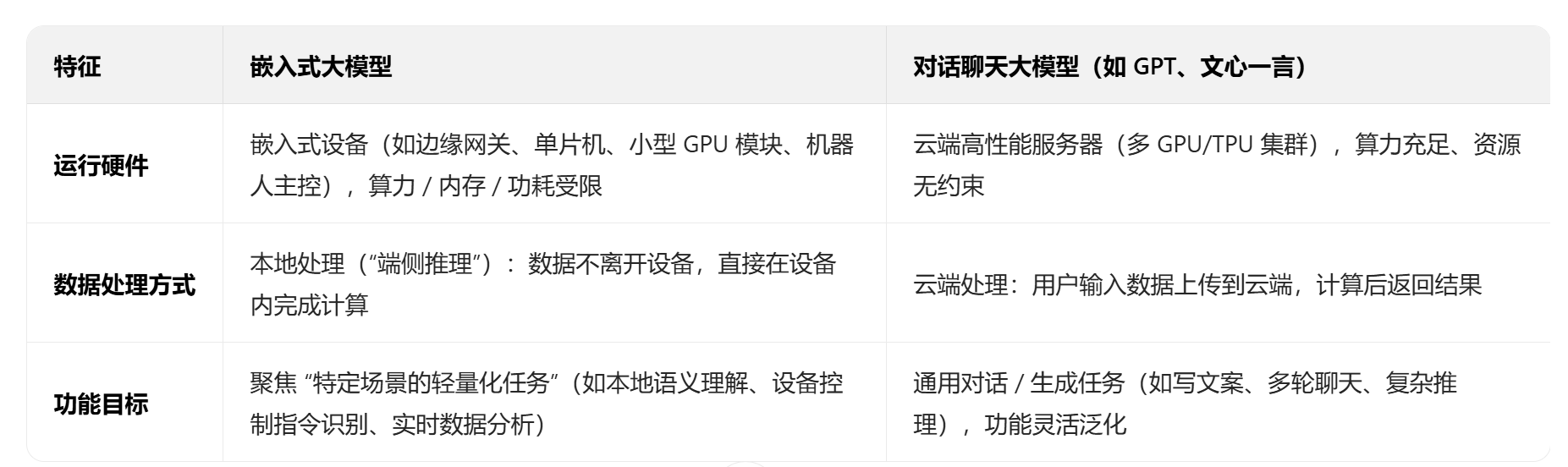
举个具体例子:
- 你对着家里的智能音箱说 “打开客厅灯”:音箱里的嵌入式大模型会直接在音箱本地(端侧)处理你的语音文本,识别出 “控制指令”,然后直接发送信号给灯 —— 这个过程数据不传到云端,响应快、隐私性好,这就是嵌入式大模型的典型场景。
- 你用手机问 ChatGPT “写一篇旅行攻略”:你的输入会先传到 OpenAI 的云端服务器,在集群上完成复杂推理后,再把攻略返回给你 —— 这是云端对话模型的逻辑。
误区澄清:“嵌入式” 不是 “功能阉割”,而是 “适配场景”
很多人会误以为 “嵌入式大模型” 是 “阉割版大模型”,但其实它的核心是 “适配嵌入式环境”,而非 “功能缩水”:
- 它的 “模型优化”(如压缩、量化)是为了适应嵌入式设备的算力限制,而非减少核心能力 —— 比如一个嵌入式大模型可能被裁剪掉 “写小说” 的功能,但会强化 “识别设备控制指令” 的能力,反而在特定场景下比通用对话模型更高效。
- 它的价值在于 “实时性” 和 “隐私性”:比如工业场景中,传感器需要实时分析数据(如检测设备故障),如果传到云端会有延迟,嵌入式大模型能本地秒级响应;再比如医疗设备的语音交互,数据本地处理能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7042
7042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









