




基本过程
具体问题需要具体分析 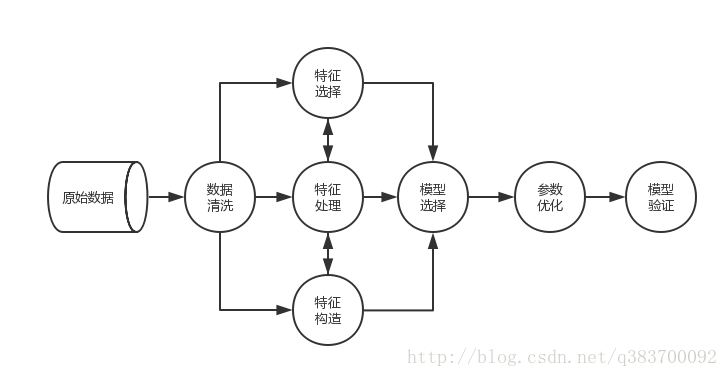
数据清洗/处理
数据清洗直接影响后期特征和模型的效果,必须重视!
一些常用python预处理方法参考:
http://blog.youkuaiyun.com/q383700092/article/details/54571887
1. 缺失值处理(删除、补全、标记为缺失特征等)
2. 异常数据处理(删除、平滑等)
3. 不规范数据规范化
4. 构建合适样本(解决样本倾斜等)
5. 划分数据集(train validation test) 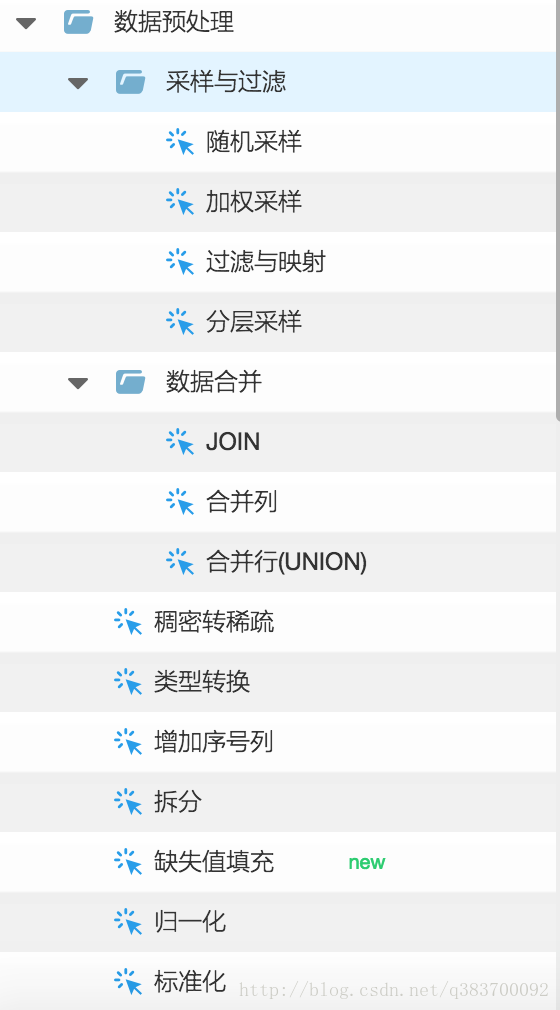
特征工程
特征工作是重中之重,特征提不好,模型很难提升上去,特征好了,效果提升很模型。
https://www.zhihu.com/question/28641663/answer/41653367
特征构造
- 根据业务场景来构建特征(特征不要时间穿越,不要用到标签)
- 交叉特征(多项式组合,GBDT与LR构造组合特征)
- 时间窗口特征
- 变换特征(log、归一化等)
- 连续特征离散化
- 离散特征连续化(独热编码、向量化等)
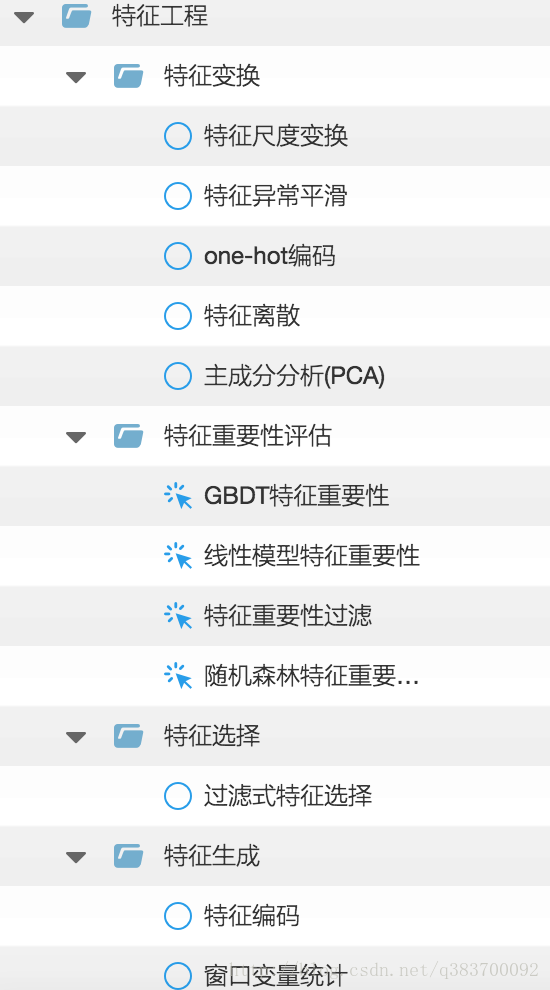
特征选择
https://www.zhihu.com/question/28641663/answer/41653367
参考
http://www.cnblogs.com/payton/p/5260239.html
http://blog.youkuaiyun.com/q383700092/article/details/53889907 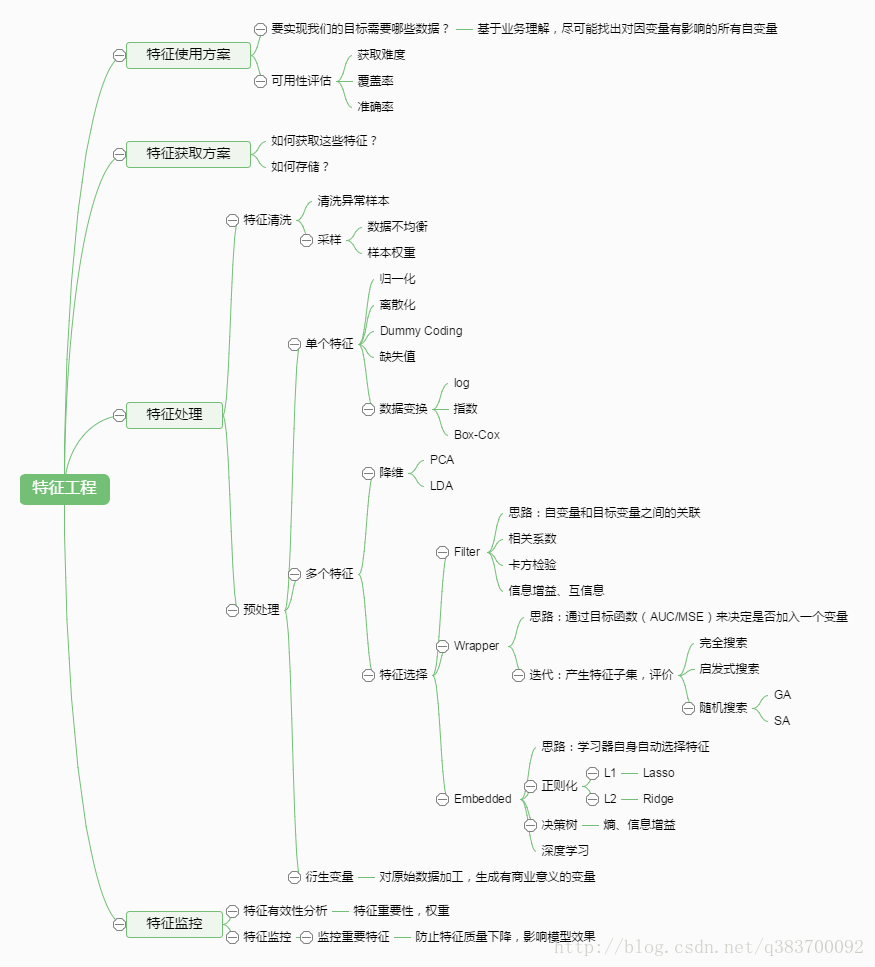
模型选择
regression (回归),classification (分类),clustering (聚类)
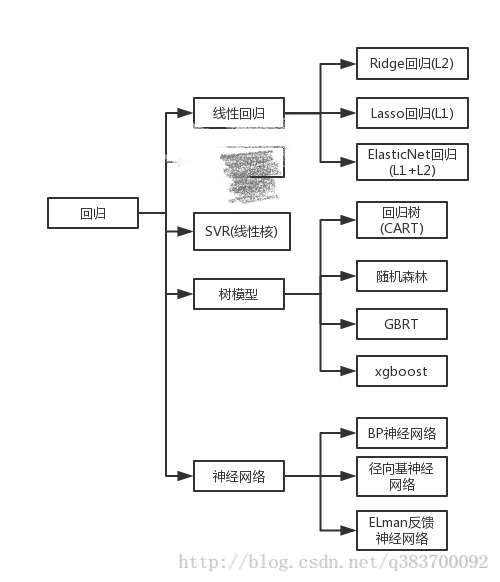
常见的回归算法
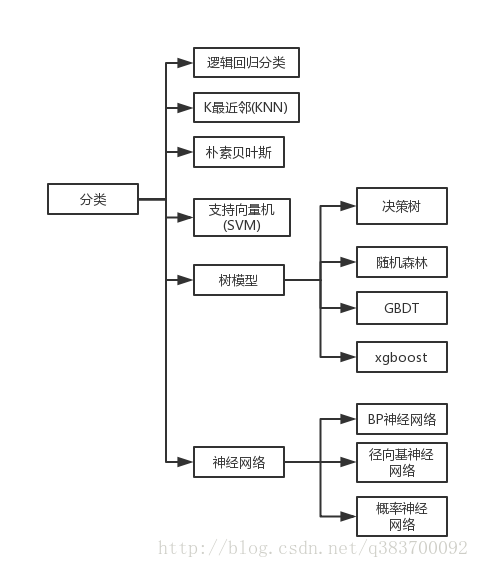
常见的分类算法
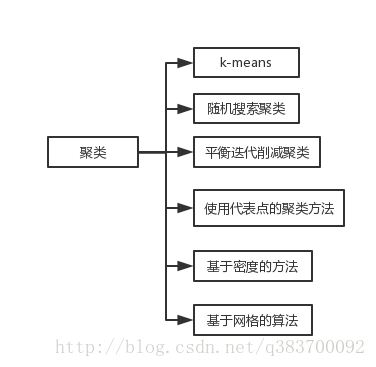
常见的聚类方法
规则
结合实际业务背景,简单有效的规则,可用于模型融合。
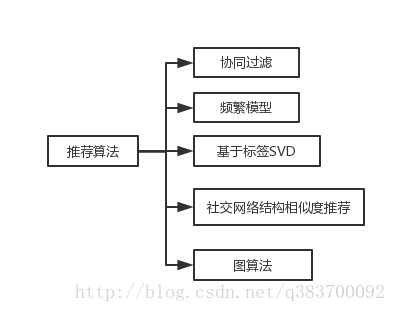
推荐算法
参数优化
交叉验证避免过拟合,针对评测函数优化,重构模型损失函数。
网格搜索遍历优化等,与模型本身数学推导和数据情况有关,具体略。
资源分配
- 预处理10%
- 特征过程60%
- 模型调整/融合30%
文本处理
不平滑数据处理
暂略
- 过采样/欠采样
- 代价敏感
集成学习
参考:http://blog.youkuaiyun.com/q383700092/article/details/53557410
迁移学习
暂略
参考数加平台
统计分析
网络分析
大规模机器学习
推荐入门书籍
- 李航《统计学习方法》
- 周志华《机器学习》
参考资料
http://www.cnblogs.com/payton/p/5260239.html
http://blog.youkuaiyun.com/matrix_space/article/details/50541217
https://github.com/jobbole/awesome-machine-learning-cn
http://blog.youkuaiyun.com/bryan__/article/details/51745563
http://blog.youkuaiyun.com/xxinliu/article/details/7408742
http://www.hankcs.com/ml/
https://github.com/Flowerowl/Big_Data_Resources
http://blog.youkuaiyun.com/q383700092/article/details/53889907

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









