








 该专栏为热销专栏榜 第32名
该专栏为热销专栏榜 第32名 超级会员免费看
超级会员免费看


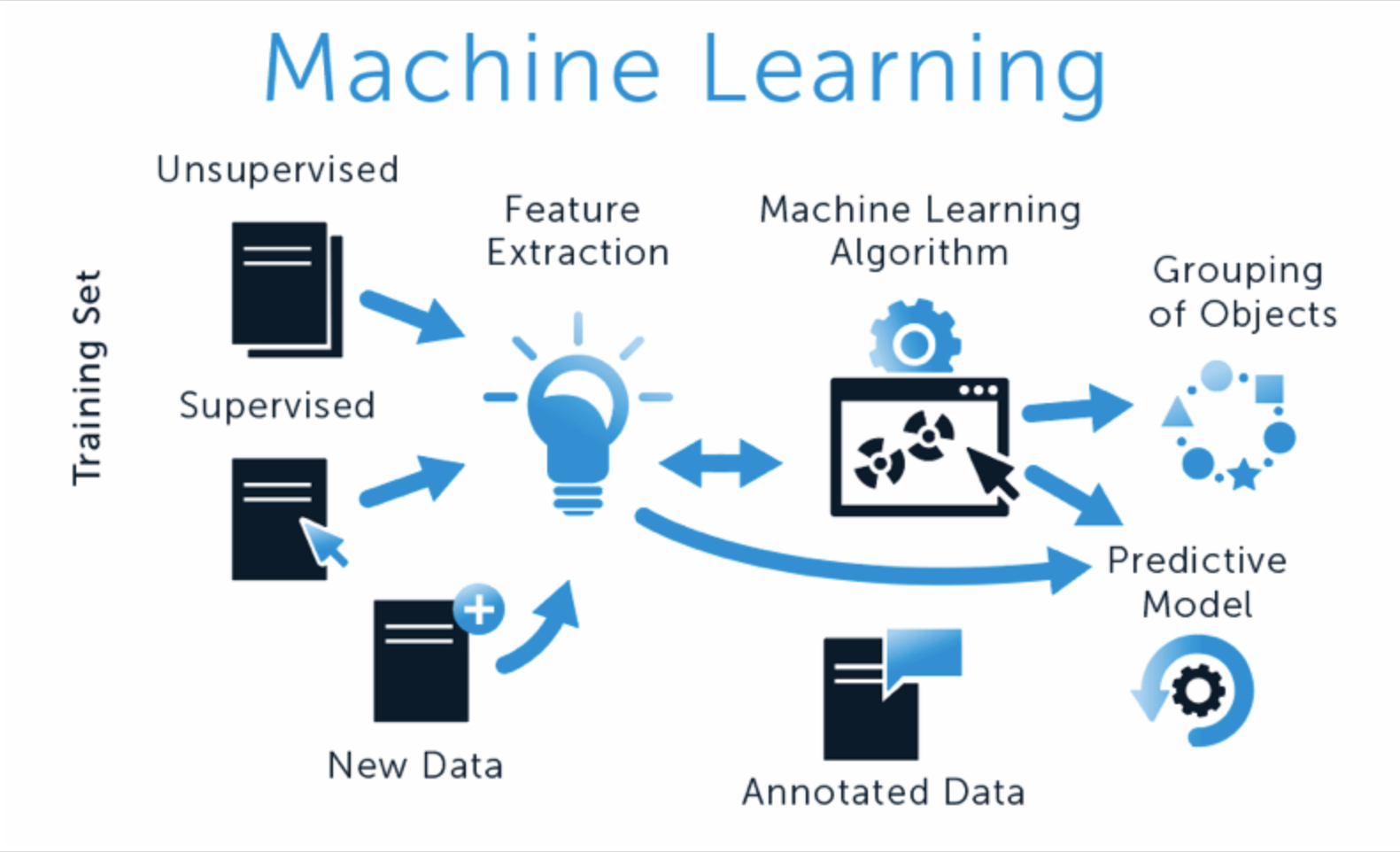
大语言模型应用指南:机器学习的过程
文章目录
1. 背景介绍
1.1 问题的由来
在过去的几年里,自然语言处理(NLP)领域取得了长足的进步,很大程度上要归功于大型语言模型(Large Language Models, LLMs)的出现和发展。LLMs是一种基于深度学习的技术,能够从大量文本数据中学习语言模式和语义关系,从而生成看似人类编写的自然语言输出。
随着计算能力的不断提高和海量数据的积累,训练大规模语言模型成为可能。这些模型在广泛的自然语言处理任务中表现出色,包括机器翻译、文本摘要、问答系统、内容生成等,展现出令人惊叹的语言理解和生成能力。
然而,尽管取得了巨大的进步,但训练和应用大型语言模型仍然面临着诸多挑战。这些挑战包括:
- 数据质量和隐私: 训练高质量的语言模型需要大量高质量的文本数据,但获取和处理这些数据并确保隐私和版权合规性是一个艰巨的任务。
- 计算资源: 训练大型语言模型需要大量的计算资源,包括GPU和TPU等专用硬件加速器,这对于许多组织来说是一个挑战。
- 模型可解释性: 尽管语言模型表现出色,但它们的内部工作原理往往是一个黑箱,缺乏可解

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











