







本文目录
背景介绍
本文作者来自香港大学,北航大学以及苏黎世联邦理工学院。近年来,预训练大模型在自然语言生成方面,展现出了非凡的能力,但是往往参数量非常庞大。模型权重二值化(binarizatio)是一种非常有效的,降低模型大小的方法,但现有的量化方法在二值化模型时,效果往往较差。
因此,本文作者提出了一种,大模型PTQ二值化量化方法。该方法可以将LLaMA2-70B量化至1.08-bit(部分权重2bit),Wikitext2 数据集上 ppl 可达8.42。同时,该方法所需的计算资源较少,只需0.5h,便可在1块A100上量化一个7B的模型。
- 论文:https://arxiv.org/pdf/2402.04291
- 代码:https://github.com/Aaronhuang-778/BiLLM
核心方法
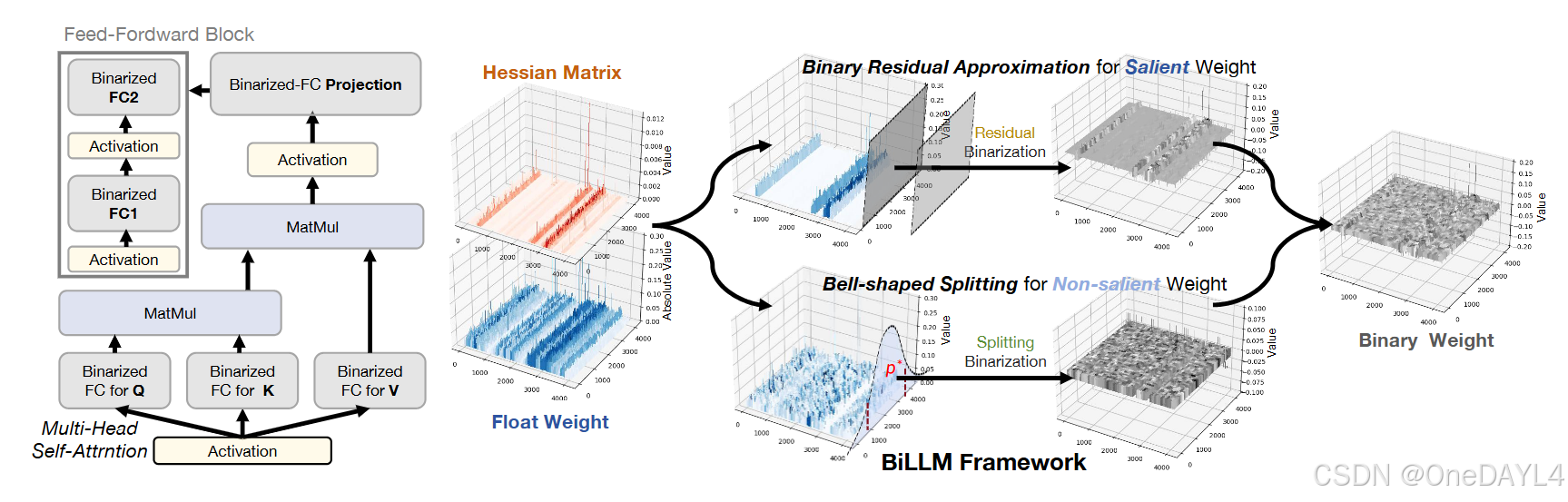
本文的核心方法包括三部分:基于Hessian矩阵的显著权重选择、基于二值化残差(Binary Reidual Approximation)的显著权重量化、基于钟型分布(Bell-shaped Distribution)的权重量化分组
- 基于Hessian矩阵的显著权重选择
- 基于二值化残差(Binary Reidual Approximation) 的显著权重量化
- 基于钟型分布(Bell-shaped Distribution) 的权重量化分组
基于Hessian矩阵的显著权重选择
为了最小化模型的量化损失,作者对显著性权重(salient weights)、非显著性权重(non-salient)采取了不同的二值化量化方式。显著性权重可以理解为:关键权重,对模型效果影响较大的权重,需要精心设计量化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









