







 本文详细介绍了NumPy的基础与高级应用。基础部分涵盖创建数组、打印数组、基本运算、索引切片等功能,还介绍了数组的属性。高级应用则涉及NumPy数据类型体系。同时,文中还列举了线性代数、随机数生成等相关操作及对应函数。
本文详细介绍了NumPy的基础与高级应用。基础部分涵盖创建数组、打印数组、基本运算、索引切片等功能,还介绍了数组的属性。高级应用则涉及NumPy数据类型体系。同时,文中还列举了线性代数、随机数生成等相关操作及对应函数。
NumPy 基础
NumPy 主要就是通过引入 ndarray 实现了一种高效的数据存取和处理,配套了基础的数据处理函数和广播能力,并具有多种元素索引能力(包括逻辑索引)。其基本功能与 matlab 的数据结构基本一致,主要区别是 matlab 对于元素的操作通过加 ‘.’ 实现,而 NumPy 自动对元素进行操作,对应矩阵乘法则需要使用额外的函数实现。
ndarray 与 Python 列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上。如果想要得到的是 ndarray 切片的一份副本而非视图,就需要显式地进行复制操作,例如 a.copy()。
import numpy as np
更多重要ndarray对象属性有:
-
ndarray.ndim: 数组轴的个数,在python的世界中,轴的个数被称作秩
-
ndarray.shape:数组的维度。这是一个指示数组在每个维度上大小的整数元组。例如一个n排m列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性
-
ndarray.size 数组元素的总个数,等于shape属性中元组元素的乘积。
-
ndarray.dtype 一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。另外NumPy提供它自己的数据类型。
-
ndarray.itemsize 数组中每个元素的字节大小。例如,一个元素类型为float64的数组itemsiz属性值为8(=64/8),又如,一个元素类型为complex32的数组item属性为4(=32/8).
-
ndarray.data 包含实际数组元素的缓冲区,通常我们不需要使用这个属性,因为我们总是通过索引来使用数组中的元素。
创建数组
可以使用 array 函数从常规的Python列表和元组创造数组。所创建的数组类型由原序列中的元素类型推导而来。
a = array( [2,3,4] )
b = array( [ (1.5,2,3), (4,5,6) ] )
c = array( [ [1,2], [3,4] ], dtype=complex )
通常,数组的元素开始都是未知的,但是它的大小已知。因此,NumPy提供了一些使用占位符创建数组的函数。这最小化了扩展数组的需要和高昂的运算代价。
a = np.zeros( (3,4) )
b = np.ones( (2,3,4), dtype=int16 )
c = np.empty( (2,3) )
d = np.eye(4)
e = np.arange(15).reshape(3, 5)
f = np.linspace(0,pi,3)
当 arange使用浮点数参数时,由于有限的浮点数精度,通常无法预测获得的元素个数。因此,最好使用函数 linspace去接收我们想要的元素个数来代替用range来指定步长。
打印数组
当你打印一个数组,NumPy以类似嵌套列表的形式显示它,但是呈以下布局:
- 最后的轴从左到右打印
- 次后的轴从顶向下打印
- 剩下的轴从顶向下打印,每个切片通过一个空行与下一个隔开
>>> c = arange(24).reshape(2,3,4) # 3d array
>>> print c
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
基本运算
数组的算术运算是按元素的。新的数组被创建并且被结果填充。不像许多矩阵语言,NumPy中的乘法运算符*指示按元素计算,矩阵乘法可以使用dot函数或创建矩阵对象实现
这些运算默认应用到数组好像它就是一个数字组成的列表,无关数组的形状。然而,指定 axis参数你可以把运算应用到数组指定的轴上。
索引、切片和迭代
data = np.array(['1.24','-2.7','3.','2.1','3','3.4','123'], dtype=np.string_)(声明元素类型为 String)
data.astype(np.float32)(将元素类型强制转换为 float)
data[3:6] (取位置 3 -5 的元素,修改即修改原始数组)
temp_copy = data[3:7].copy() (取位置 3-6 的元素,并复制得到新的数组)
data = np.array([[1,2,3],[2,3,4],[3,4,5]]) (生成二维数组)
data[1] (取二维数组位置为 1 的行)
data[1,2](取二维数组位置为 1,2 的元素)
data[1][2](取二维数组位置为 1,2 的元素)
data[:2](取二维数组位置为 2 的列)
data[:2, 1:] (取二维数组行 小于 2,列大于等于 1 的子数组)
data == 1 (得到元素是否等于 1 的逻辑数组)
data[data == 1](取元素等于 1 的对应元素)
data[data != 1](取元素不等于 1 的对应元素)
data[(data == 1) | (data == 2)](取元素等于 1 或 等于 2 的对应元素)
data[data < 3] = 0(将元素小于 3 的元素置 0)
data[[2,0,1,1]](按行 2 0 1 1 的对应数组)
data[[2,0,1,1],[1,2,1,0]](取位置 [2,1] [0,2] [1,1] [1,0] 的元素)
data[[2,0,1,1]][:,1,2,1,0]](按行 2 0 1 1 和列 1 2 1 0 取出对应数组)
点(…)代表许多产生一个完整的索引元组必要的分号。
- x[1,2,…] 等同于 x[1,2,:,:,:],
- x[…,3] 等同于 x[:,:,:,:,3]
- x[4,…,5,:] 等同 x[4,:,:,5,:].
如果想对每个数组中元素进行运算,我们可以使用flat属性,该属性是数组元素的一个迭代器:
>>> for element in b.flat:
... print element,
...
0 1 2 3 10 11 12 13 20 21 22 23 30 31 32 33 40 41 42 43
形状操作
由 ravel() 展平的数组元素的顺序通常是“C风格”的,就是说,最右边的索引变化得最快,所以元素a[0,0]之后是a[0,1]。如果数组被改变形状(reshape)成其它形状,数组仍然是“C风格”的。NumPy通常创建一个以这个顺序保存数据的数组,所以 ravel() 将总是不需要复制它的参数3。但是如果数组是通过切片其它数组或有不同寻常的选项时,它可能需要被复制。函数 reshape() 和 ravel() 还可以被同过一些可选参数构建成FORTRAN风格的数组,即最左边的索引变化最快。reshape 函数改变参数形状并返回它,而resize函数改变数组自身。
a = np.floor(10*random.random((3,4)))
a.ravel() # flatten the array
a.shape = (6, 2)
a.transpose()
a.resize((2,6))
如果在改变形状操作中一个维度被给做-1,其维度将自动被计算
组合(stack)不同的数组
- vstack:沿着第一个轴组合数组
- hstack:沿着第二个轴组合数组
- column_stack:以列将一维数组合成二维数组
- row_stack:将一维数组以行组合成二维数组
在复杂情况下, r_[]和 c_[]对创建沿着一个方向组合的数很有用,它们允许范围符号(“:”):
>>> r_[1:4,0,4]
array([1, 2, 3, 0, 4])
将一个数组分割(split)成几个小数组
-
hsplit:将数组沿着它的水平轴分割,或者指定返回相同形状数组的个数,或者指定在哪些列后发生分割
-
vsplit:沿着纵向的轴分割
-
array_split:允许指定沿哪个轴分割
矩阵类
注意NumPy中数组和矩阵有些重要的区别。NumPy 提供了两个基本的对象:一个N维数组对象和一个通用函数对象。其它对象都是建构在它们之上 的。特别的,矩阵是继承自 NumPy 数组对象的二维数组对象。对数组和矩阵,索引都必须包含合适的一个或多个这些组合:整数标量、省略号 (ellipses)、整数列表;布尔值,整数或布尔值构成的元组,和一个一维整数或布尔值数组。矩阵可以被用作矩阵的索引,但是通常需要数组、列表或者 其它形式来完成这个任务。
像平常在Python中一样,索引是从0开始的。传统上我们用矩形的行和列表示一个二维数组或矩阵,其中沿着0轴的方向被穿过的称作行,沿着1轴的方向被穿过的是列。
a = np.matrix([[1,2],[3,4]])
通用函数
- abs, fabs (计算绝对值,fabs 为非复数的更快版本)
- sqrt (开方)
- square (平方)
- exp (指数)
- log, log10, log2, log1p (对数, log1p 为 log(1+x))
- sign (取元素符号)
- ceil (向上取整,保持原有的数据类型)
- floor(向下取整,保持原有的数据类型)
- rint (四舍五入,保留 dtype)
- modf (以小数和整数部分独立返回)
- isnan (判断是否为NaN)
- isfinite, isinf (判断是否有限和无穷)
- cos, cosh, sin, sinh, tan, tanh
- arccos, arccosh, arcsin, arcsinh, arctan, arctanh
- logical_not
- add (+)
- subtract (-)
- multiply (*)
- divide, floor_divide (/, //)
- power
- maximum, fmax (元素级最大值计算,)
- minimum, fmin
- mod(取模)
- copysign(将第二个数组值的符号复制给第一个数组)
- greater, greater_equal
- less, less_equal
- equal, not_equal
- logical_and, logical_or, logical_xor
利用数组进行数组处理
- where (根据第一个参数的 T or F,来确定是选第二个参数,还是第三个)
- sum
- mean
- std, var
- min, max
- argmin, argmax
- cumsum (所有元素的累积和)
- cumprod (所有元素的累积积)
- any
- all
- sort
- unique
- intersect1d (交集)
- union1d (并集)
- in1d (第一个数组中的元素是否包含在第二数组中)
- setdiff1d (集合之差)
- setxor1d (存在在某一个数组,但不同时存在于两个数组中)
数组文件的输入输出
- save(path, values):以 npy 结尾
- load(path)
- savez(path, key1=values, key2=values):读取时通过 data[key] 读取相应的数据
- savetxt
- loadtxt:np.loadtxt('array.txt', delimiter=',')
线性代数
- import numpy.linalg
- diag:对角矩阵和向量的转换
- dot:矩阵乘法
- trace:对角元素的和
- det:矩阵行列式
- eig:方阵的特征值和特征向量
- inv:方阵的逆
- pinv:矩阵的广义逆
- qr:QR分解
- svd:奇异值分解
- solve:Ax = b 线性方程求解,A 为方阵
- lstsq:计算 Ax = b 的最小二乘解
随机数生成
- import numpy.random
- seed
- permutation:返回一个序列的随机排列
- shuffle:就是随机排列
- rand:均匀分布
- randint:给定范围内随机选择整数
- randn:(0,1)正态分布
- binormal:二项分布
- normal:正态分布
- beta:Beta分布
- chisquare:卡方分布
- gamma:Gamma分布
- uniform:(0,1)均匀分布
NumPy 高级应用
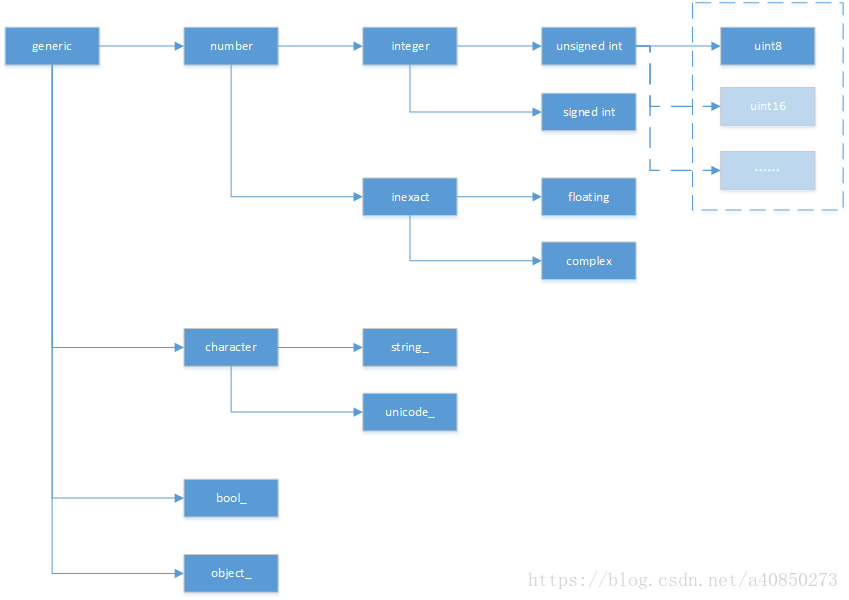
NumPy 数据类型体系

















 4260
4260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









