




 研究介绍了一种端到端训练的音视语音识别模型,通过融合waveform和唇部图像特征,采用Conformer+Transformer结构。实验表明,该模型在低信噪环境下,waveform表现优于传统FBank特征。关键贡献包括视觉特征提取的改进网络和Transformer语言模型的应用。
研究介绍了一种端到端训练的音视语音识别模型,通过融合waveform和唇部图像特征,采用Conformer+Transformer结构。实验表明,该模型在低信噪环境下,waveform表现优于传统FBank特征。关键贡献包括视觉特征提取的改进网络和Transformer语言模型的应用。
简介
提出了可端到端训练的音视语音识别模型,输入waveform和唇部的每一帧,音视各通过一个conformer encoder后concat并FC得到融合特征,最后是transformer decoder。端到端训练比分开训练好;当信噪比较低时,waveform比fbank效果好
论文的任务/贡献
提出了端到端的音视语音识别模型,从waveform和图像接受收入进行训练。
所提方法
网络结构
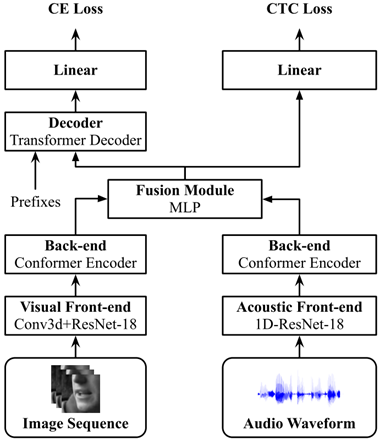
包含front-end、back-end和fusion modules。
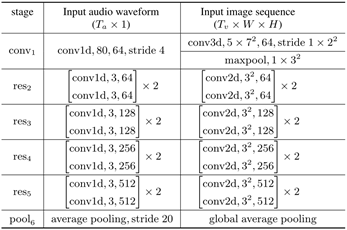
Front-end:视觉使用了将第一卷积层替换为核大小为5×7×7的3D卷积的ResNet18网络,最后使用了GAP;音频使用了基于1D卷积的ResNet18的网络,第一层滤波器尺寸为80(5ms),第一个block下采样4倍,随后每个block下采样2倍。最后声学特征下采样至每秒25帧以匹配视觉特征。
Back-end:将resnet特征投影到dk维空间,使用相对位置信息(Transformer-XL: Attentive language models beyond a fixed-length context)编码后送入conformer encoder
融合层:串接back-end输出的声学和视觉特征通过MLP投影到dkd_kdk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2590
2590




 到【灌水乐园】发言
到【灌水乐园】发言







