







 本文探讨了python_speech_features、torchaudio和kaldi在提取Fbank特征时的异同。主要区别包括默认参数、分帧处理、功率谱计算、Mel滤波器组的计算方式以及对最后一帧的处理。实验结果显示,虽然存在细微差异,但整体上三者提取的特征相近。
本文探讨了python_speech_features、torchaudio和kaldi在提取Fbank特征时的异同。主要区别包括默认参数、分帧处理、功率谱计算、Mel滤波器组的计算方式以及对最后一帧的处理。实验结果显示,虽然存在细微差异,但整体上三者提取的特征相近。
首先,提取fbank特征的大致步骤为:预加重、分帧、加窗、FFT、Mel滤波器组、对数运算。(加上DCT离散余弦变换就得到MFCC特征)。
一、python_speech_features提特征源码:
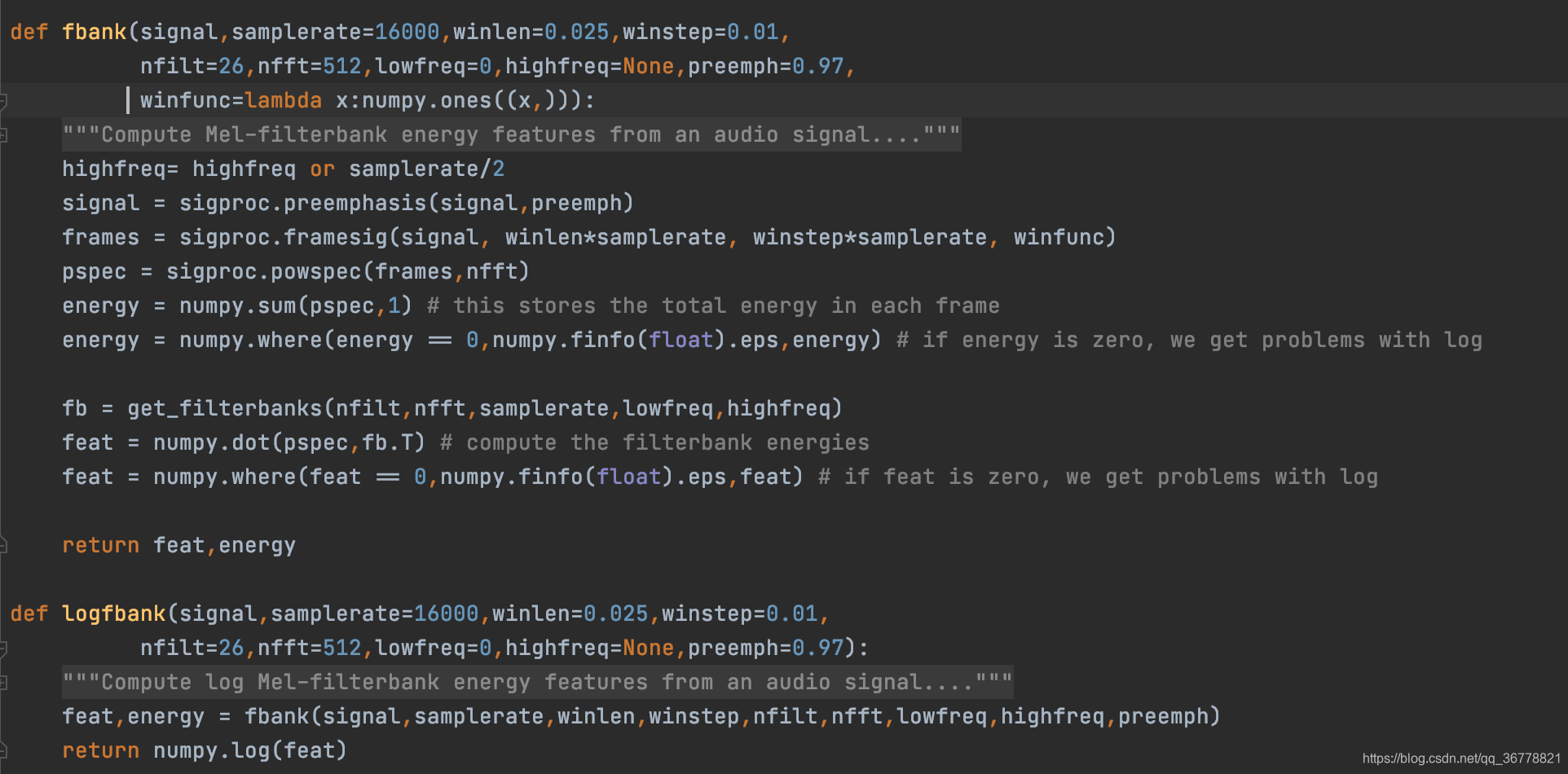
从源码研究,python提fbank特征的接口python_speech_features的工作流程为:
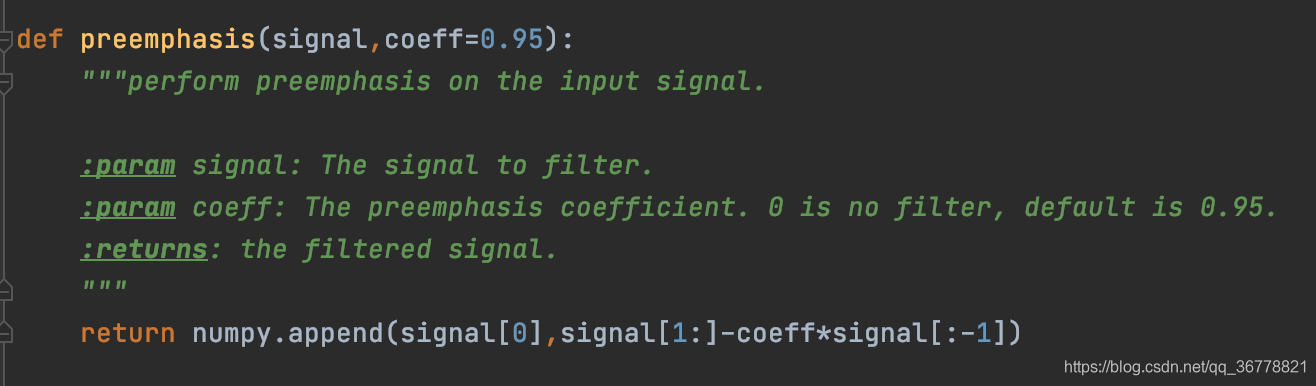
1、**signal = sigproc.preemphasis(signal,preemph)**为预加重,系数 a=0.97;预加重其实就是将语音信号通过一个高通滤波器:y(t)=x(t)-ax(t-1);
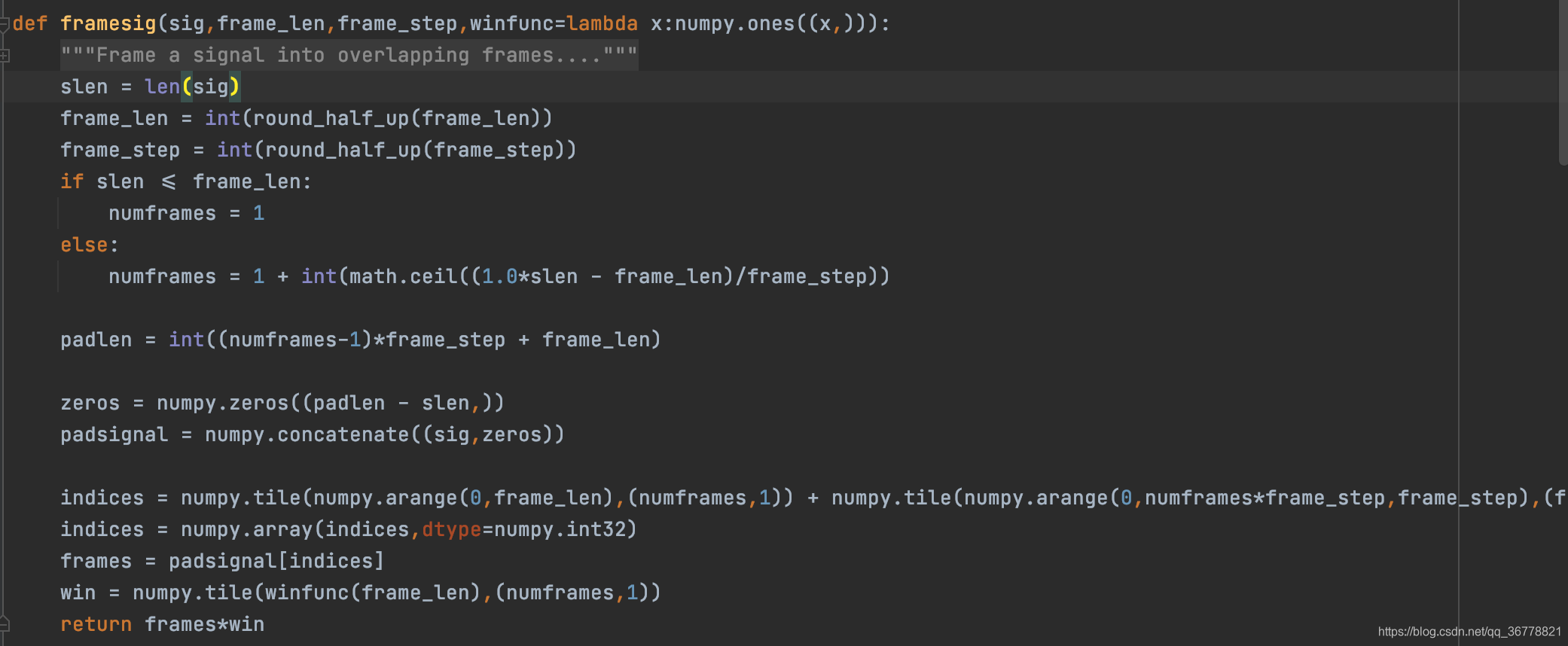
2、**frames = sigproc.framesig(signal, winlensamplerate, winstepsamplerate, winfunc)**为分帧加窗(这里默认窗是全1数组,相当于没有加窗功能,想要加窗必须传参,如:winfunc=numpy.hamming),也就是将采样点按照帧移20-30ms,帧长1/2或者1/3个帧长进行分帧,python_speech_features的帧长是25ms(400个采样点),帧移10ms(160个采样点)。再将每个帧和窗相乘,一般用hamming窗,但是这里默认没有加窗;
3、pspec = sigproc.powspec(f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









