




 该博客探讨了一种使用Transformer处理视频和音频的方法,特别是在唇读和音视语音识别任务上。通过将视频切分为tubelets并送入Transformer,以及结合FBank声学特征,模型在高噪声环境下表现出色。然而,在说话声重叠和弱噪声条件下,其性能下降,可能由于训练数据与测试数据之间的域转移问题。研究还指出,经过调整后的训练集可以改善模型在特定数据集上的表现。
该博客探讨了一种使用Transformer处理视频和音频的方法,特别是在唇读和音视语音识别任务上。通过将视频切分为tubelets并送入Transformer,以及结合FBank声学特征,模型在高噪声环境下表现出色。然而,在说话声重叠和弱噪声条件下,其性能下降,可能由于训练数据与测试数据之间的域转移问题。研究还指出,经过调整后的训练集可以改善模型在特定数据集上的表现。
简介
使用了类似于ViT的思想将视频沿T,H,W方向切割为若干小块并送入Transformer中。音频使用FBank,但将三个时间步的向量合并为一个(即一秒有33.3个声学特征),视频帧也采样到33.3Hz。最后的效果是ASR任务下Transformer在噪声强时效果较好,唇读任务下较好,但是弱噪声和说话声重叠时效果不好。
论文的任务/贡献
设计并使用纯transformer的方法在唇读、音视语音识别任务上提取视觉特征
所提方法
网络结构
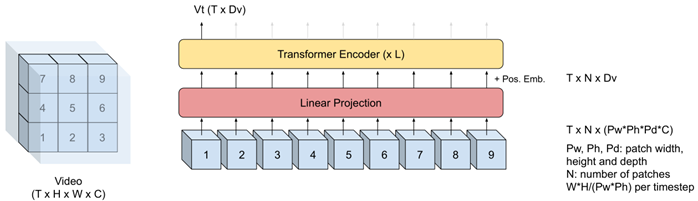
视觉前端:
1.baseline:在“Recurrent neural network transducer for Audio-Visual speech recognition”这篇论文的基础上,将[3,3,3]的3D卷积分解成[1,3,3]和[3,1,1]两种核,基于此构建了10层VGG (2+1)D的网络
2.视频transformer:在视频输入(图像块的3D版本)中,每个时间步提取了形状为32×32×8(H×W×T)的空间维度不相交的4维(H×W×T×C)“tubelets”,最终在每个时间步提取了16(4×4)个tubelets。将tubelets展平后送入仿射投影。每个tubelets的embedding与positional embedding相结合并送入6层512维8头注意力的transformer中。transformer最后一层输出送入lip reading AV-ASR网络
损失函数
RNN-T loss
实施
声学特征:FBank,采样率16KHz,25ms Hann窗口,步
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









