



使用软计算的无线传感器网络故障预测
摘要
随着来自各种来源的数据激增,传感器由于资源受限、计算能力弱、内存小以及电池电量有限,容易遭受多种攻击和发生故障。基于单一信息源的故障或容错机制存在不准确性。应通过一段时间内从不同来源收集的多特征数据来识别和描述故障。通常,容错是通过监控每个设备的健康状况实现的,而这本身会消耗大量电池电量。此外,我们需要确定进行预测分析时合适的时间间隔或频率。在无线传感器网络中预测故障是一项具有挑战性的任务,需要对可用的历史数据进行深入研究。特别是机器学习和数据分析的进步已经改变了组织处理此问题的方式,使其能够监控系统健康状况并采取预防措施。本文提出了一种基于时间序列数据的软计算传感器节点故障预测方法。利用ARIMA模型,我们将时间序列数据分解为趋势、季节性和残差成分,并拟合模型。我们构建了一个具有80%和95%置信区间的稳健预测估计模型,可用于在无线传感器网络中实现智能物联网基础设施。对于长期预测,由于模型需基于先前记录的预测值回归未来值,因此存在更大的不确定性。
索引术语 —ARIMA, 预测, 物联网, 软计算, 预测性分析
I. 引言
物联网实现了设备在任何时间、任何地点的无缝连接。这需要一种包含三个不同组成部分的新技术:低功耗计算设备、连接这些设备的网络,以及用于实现小型应用的轻量级软件,从而使这些设备能够交换实时数据。随着越来越多的智能设备接入互联网,生成的数据日益增多。如今,即使在森林中散步时,我们也能在指尖获取比任何计算机系统都更广泛的信息。物联网的核心理念是将所有事物连接在一起,交换数据或信息,并自主做出决策。如今,数十亿设备正相互连接,它们负责产生海量数据,这些数据可以被安全地管理、存储、分析和分发。而人类要理解这些数据则面临巨大挑战。生成的数据形式多样,可分为结构化、半结构化和非结构化数据。
各种类型和成千上万的传感器在多个领域协同工作,包括工业、医疗保健、教育、农业、智慧城市和智能家居。在每个领域中,大量关键决策完全依赖物联网设备收集的数据。设备和数据本身都面临诸多挑战。这些设备属于资源受限型,计算能力有限、内存小、电池寿命短,容易受到各种故障和威胁的影响。如果这些设备自身出现故障或受到威胁,所做出的决策可能会对系统或组织造成损害。
基于单一信息源的故障预测存在不准确性。因此,应通过从不同来源收集的多特征数据来识别和描述故障。通常,设备中的故障是通过监控每个设备的健康状况来诊断的;而这一过程本身会消耗设备大量的电池电量。因此,物联网需要具备预测性诊断的智能能力,这就促使我们依赖机器学习。如果采用一种能够自动且实时地分析历史数据、做出预测并作出响应的机制,我们将解决使物联网、工业物联网(IIoT)成为智能物联网(Intelligent IoT)的一个非常关键的问题。将物联网传感器采集的大量数据输入到多种可用的机器学习模型之一,并训练这些模型以预测或预报故障,有助于改进业务流程、产品和服务。本文提出了一种利用设备生成的数据诊断传感器节点故障的软计算方法。这种方法对于构建预测性维护系统(PdM)至关重要,可帮助我们应对任何意外情况,如图1所示,这在工业4.0类环境中尤为重要。
本篇文稿的其余部分组织如下。第二节讨论了在同一领域开展的相关工作。第三节讨论了与所用技术相关的预备知识。第四节描述了实现的模型。第五节讨论了取得的结果以及提高准确性的方法。第六节给出了简要结论。

II. 相关工作
异常预测是传感器网络中一个研究较为充分的课题。在 [1, 2] 中的各项研究提出了大量应对异常检测的方法。这些研究以一种呈现所有相关场景和方法的方式总结了异常检测这一基本问题。Jing Gao 等人[21]专门针对时间序列数据中的异常检测研究进行了综述。所有这些工作都为推进特定研究提供了极大的激励和指导。然而,由于全球范围内的数据正在迅速增长,数据中的问题也随之增多,该领域仍需要更多持续的研究。无线传感器网络(WSN)和物联网(IOT)传感器产生大数据,并且需要对数据进行大量计算。此外,由于这类数据具有连续流式特性,从其中进行模式识别变得更加重要。Gionani 等人[18]采用过滤方法处理传感器数据。该方法涉及较高的计算成本,提示我们需要改进方法。类似地,[3‐5]中的研究致力于 WSN数据的处理,并提出了应如何观测WSN数据的观点。
在处理时间序列时,人们发现“窗口化”数据是用于[20‐22]中时间数据异常检测最常用的概念。然而,窗口化在单变量数据上表现良好。通过这种方法,可以绘制单一特征的值,并利用平均技术发现异常。窗口化还提倡使用“自回归积分移动平均(ARIMA)”进行预测,如[18]所述。
时间序列预测因研究的时间范围和所使用的市场数据而表现出不同的特征。就时间范围而言,预测可分为短期(提前一天、提前一周、提前一个月)、中期(季度、半年、日历年)或长期(十年以上)。ARIMA模型已被用于股票价格预测[3],[4]、电力负荷预测[7],[8]以及石油和天然气等自然资源的预测[5],[6]。其他深度学习方法,如自动编码器、LSTM、DBN,也可以通过对前一时间窗口的学习来预测下一时间窗口[19]。异常则通过实际值与预测值图表之间的差异来识别。此类绘图仅适用于单特征或多变量数据。这使得此类模型在使用多变量数据方面受到限制,并可推断出在这些数据中进行异常检测涉及查找点异常值[11‐12]。
III. 预备知识
我们使用流行的ARIMA模型进行故障预测,因为该模型在准确性和数学严谨性方面表现良好。ARIMA由三个参数表示:(p, d, q)。该模型拟合也称为“Box‐Jenkins”方法。自回归参数(AR(p))是指在方程中使用历史值的参数。其中p表示模型中考虑的滞后阶数。如果p=2,则表示为AR(2)或ARIMA(2,0,0),其方程为:
$$ Yt = c + \Phi_1 y_{t−1} + \varphi_2 y_{t−2} + e_t $$ (1)
其中 $\varphi_1$ 和 $\varphi_2$ 是模型参数。参数d表示序列差分的程度,即当前值与前一个值之间进行d次差分,主要用于使序列趋于平稳。参数(MA(q))是移动平均分量,表示模型相对于前期误差项$e_t$的误差。q定义了参与模型的项数。
$$ Yt = c + \theta_1 e_{t−1} + \theta_2 e_{t−2} + .... + \theta_q e_{t−q} + e_t $$ (2)
结合差分、自回归和移动平均这三个组成部分,ARIMA模型可以表示为:
$$ Yt = c + \Phi_1 y^d_{t−1} + \varphi_p y^d_{t−2} + \theta_1 e_{t−1} + \theta_q e_{t−q} + e_t $$ (3)
其中 $y^d$ 是 $Y$ 经过 $d$ 次差分后的结果,且具有常数项 $c$。
IV. ARIMA模型构建步骤
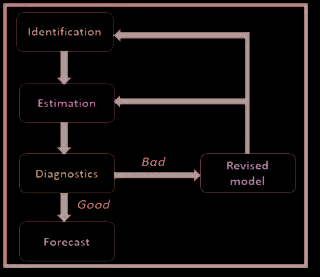
•
识别
:此步骤用于识别模式并实现稳定化。它使用图形、自相关函数、偏自相关函数等。
•
估计
:顾名思义,此步骤使用最小二乘法和最大似然方法来估计系数
•
诊断
:此步骤用于检查模型的真实性,并使用残差图、自相关函数和偏自相关函数等。如果无效,则重复上述步骤。
•
预测
:此步骤用于确定置信区间,以检查预测的有效性。
V. ARIMA过程
ARIMA过程有多种类型,即自回归过程:ARIMA (1,0,0)、移动平均过程:ARIMA(0,0,1)、单整过程:ARIMA (0,1,0),其中又包含两种过程——随机游走过程:ARIMA (0,1,0)和确定性趋势过程:ARIMA (0,1,0)等。在我们的研究中,采用了移动平均过程。
A. ARIMA模型识别工具
1)
自相关函数
$$ ACF(k) = \frac{\sum_{t=1+k}^{n}(Y_t - \bar{Y})(Y_{t-k} - \bar{Y})}{\sum_{t=1}^{n}(Y_t - \bar{Y})^2} = \frac{cov(Y_t,Y_{t-k})}{var(Y_t)} $$ (4)
2)
偏自相关函数 (PACF)
:一旦中间值 $Y_{t−1}…Y_{t−k+1}$ 被调整后,可以测量 $Y_t$ 和 $Y_{t−k}$ 之间的额外相关性。该函数与自相关函数密切相关,其值同样在 ‐1 和 +1 之间变化。
3)
图形绘制
:自相关和偏自相关通常以表格形式表示,也可以在相关图中绘制。
B. 诊断方法
1)
Ljung‐Box (1978) 统计量
:用于通过自相关性对时间序列的白噪声进行诊断度量。记为 $Q$。
$$ Q = n(n+2) \sum_{i=1}^{k} \frac{ACF(i)^2}{N - i} $$ (5)
2)
原假设 (Ho)
:自相关函数与白噪声自相关函数无显著差异(即 ACFs=0)。
3)
备择假设 (H1)
:自相关函数在统计上不同于白噪声自相关函数(即 ACFs ≠ 0)。
4)
判定规则
:如果 $Q ≤$ 卡方,则不能拒绝 $Ho$,且自相关函数模式被视为白噪声;如果 $Q >$ 卡方,则应拒绝 $Ho$,且自相关函数模式不被视为白噪声。
C. 模型选择的标准
“赤池信息准则 (AIC)”和“施瓦茨贝叶斯信息准则 (BIC, SC 或 SBC)”通常被用作模型拟合或选择的标准。一般来说,会选择具有最低 AIC 或 BIC 值的模型。
VI. 模型实现
我们使用了一个大型的UCI传感器数据集,该数据集包含多年汇总至日级别的家庭用电量数据,可在其机器学习仓库中找到,并执行了两个预处理步骤:使用属于R forecast包的tsclean()来填补任何缺失值
• 随机污染数据集以模拟无线传感器网络中的故障传感器节点场景。这是通过编写一个小脚本来实现的,使得污染随机分布。
我们的目标是尝试理解时间序列中是否存在某种模式,并预测这些故障的发生。为此,我们对时间序列数据进行分解,并使用ARIMA模型直接预测这些故障。为了构建季节性ARIMA模型,采用广为人知的博克斯‐詹金斯方法对时间序列数据进行处理,该方法包括上述三个步骤。
1) 加载R语言包 为了运行此模型,使用统计软件R语言及其必要的包(“Performance Analytics”、“tseries”和“forecast”),并读取分析数据集。
2) 检查数据 我们使用原始数据绘制序列图,以检查是否存在任何异常值。在所考虑的数据集中,我们观察到大量波动,但可以看到一些初步模式:故障在特定月份更为集中,而在其他月份较少,如下图3所示。

还观察到故障数量存在快速上升和下降的情况,这些可以被视为异常值,不应考虑在内,因为它们可能会使结果产生偏差。同样,这些异常值通过使用tsclean()被剔除。我们使用 ggplot绘制清洗后序列,如下图4所示。我们观察到

数据仍然具有波动性。考虑一条穿过峰值和谷值的线,这条线被称为移动平均(MA)。它通过取平均值来平滑数据点,使数据变得更加稳定且可预测。这里可以考虑日/周/月移动平均。通过分析数据,我们在下图5中将序列建模为日移动平均(以蓝线表示)。

3) 分解数据 此步骤利用季节性、趋势和周期来构建一个稳定的预测模型。首先,使用stl()函数确定数据的季节性成分,以对序列进行去季节化处理。如图6所示,我们每月使用了30个观测值。

4) 平稳性 我们使用“增强型迪基‐福勒(ADF)”检验来检查平稳性。原假设通过检验趋势成分的存在,认为序列是非平稳的。由于故障平均数量随时间变化,因此我们的数据被视为非平稳的数据。经视觉检查发现,ADF检验未拒绝非平稳性的原假设。在对移动平均数据进行ADF检验时,观察到迪基‐福勒值为‐0.2557,滞后阶数为8,p值为0.99,备择假设为平稳。将非平稳序列转换为平稳序列的解决方案是使用差分(ARIMA的d分量)。
5)
自相关与模型阶数选择
为了检验序列的平稳性,使用自相关图(ACF)。阶次参数还通过这些图表选择了。我们考虑d=1,并检查是否需要进一步差分。ADF在差分数据上拒绝了非平稳性的原假设。当绘制差分序列时,如图7所示,可以看出振荡模式围绕0波动,并且在图9中显示没有明显的趋势。
ADF检验使用差分数据计数,观察到迪基‐福勒值为‐9.9255,滞后阶数为8,p值为0.01,备择假设为平稳。尖峰

上述序列中的信息有助于为我们的模型选择p和q。我们看到在滞后1、2及更远的位置存在显著的自相关性。图8和图9中的ACF和PACF图分别在滞后1和7处包含一个显著尖峰。因此,我们的模型的AR和MA参数可能为1、2或7阶。


VII. 结果与讨论
为了测试所开发的模型,在进行任何预测之前定义一个预测范围h,并使用所开发的模型生成这些预测。在本例中,我们对 h=5(短期)和 h=15(长期)进行预测。以下两个图表(图10 和 图11)中的浅蓝色线条展示了所开发模型提供的拟合效果。
 )
)
 )
)
A. 检查模型的未来准确性
为了检验所开发模型的有效性,我们将部分数据保留作为“留出”集,对模型进行测试拟合,并将观测值与实际值进行比较,如下图12所示。

蓝色线条表示预测。可以观察到有时它会迅速接近一条直线,这并不符合实际的前期序列值。这可能是因为该模型假设序列中没有季节性,并对原始的非平稳数据进行了差分处理。我们在此假设该序列完全基于一个假设性假设:即数据不会波动,因为每日传感器故障的数量在均值和方差上保持恒定,这是一个假设性假设。然而,该基础模型可以作为选择合适ARIMA模型的基准。我们执行以下步骤来提高该基础ARIMA模型的预测准确性:
- 将我们之前提取的季节性成分重新添加回去。我们看到AIC、AICc和贝叶斯信息准则的值都更低,表明准确性更高,如表1所示。
- 默认使用auto.arima()函数来选择模型中的(p, d, q)值。
表I 预测准确性比较
| 去季节性拟合 | 季节性拟合 |
|---|---|
| 序列:去季节化cnt 模型:ARIMA(1,1,1) | 序列:去季节性 cnt 模型:ARIMA(2,1,2) (1,0,0) |
| AIC=9413.82 | AIC=9379.17 |
| AICc=9413.85 | AICc=9379.29 |
| BIC=9427.57 | 贝叶斯信息准则=9426.68 |
通过考虑上述快速修复方法,我们重新拟合了模型,并观察到一些季节性模式仍然存在,这与去季节性模型的情况相同,如图13和14所示。值得注意的是,ARIMA参数的值在我们加入季节性成分后发生了变化。该模型通过残差和 ACF‐PACF图进行评估和调整。


所开发的预测估计均包含置信区间,其中一个为深蓝色阴影,对应80%置信限,另一个为浅蓝色阴影,对应95%限值。正如预期,长期预测表现出更大的不确定性,因为模型需要基于先前预测的值来回归未来的值。这一点从置信区间的形状中可以明显看出,随着时序的延长,置信区间开始变宽。
VIII. 结论
提出了一种基于ARIMA时间序列预测方法的稳健模型,用于预测无线传感器网络中的传感器节点故障。研究发现,该模型适用于短期预测,但也存在一些缺点。首先,该模型依赖于历史值,因此最适合长而稳定的序列。其次,需要注意的是,ARIMA仅能近似历史模式,因而无法描述底层数据机制的结构,而这一结构对于任何现象的理解都至关重要。然而,ARIMA仍是获取洞察、估计故障模式和故障频率的有效工具,这正是本研究试图提供的。关于未来研究,为了提高整体准确性,我们计划将广泛接受和普遍使用的ARIMA与采用反向传播学习的人工神经网络结合,形成一种混合组合,用于此任务。

















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









