



基于改进的RETINAFACE算法的口罩佩戴智能检测与识别系统
摘要
新冠肺炎可通过空气飞沫、气溶胶等载体传播。为了更好地降低人们的感染风险,个人在前往公共场所、就医以及乘坐公共交通工具时需佩戴口罩以防止病毒传播。本文基于改进的RETINAFACE算法,有效实现了口罩佩戴检测,并在此基础上实现了判断口罩是否正确佩戴的功能。在人脸识别算法方面,本文设计了一种精度更高的人脸识别算法。该系统结合了口罩佩戴检测算法、口罩规范佩戴检测算法和人脸识别算法。此外,本文还增加了语音提示模块,以更好地辅助系统功能的完整性。最终实验测试结果表明,该系统能够有效实现口罩检测与识别的目的。
关键词 :口罩检测;口罩规范佩戴检测;人脸识别;RETINAFACE算法
一、引言
自2019年12月起,突如其来的新型冠状病毒肺炎(新冠肺炎)迅速在全国乃至全球蔓延[1]。截至2020年7月15日,全球220多个国家和地区累计报告确诊病例超过1365万例,死亡病例超过58万例。目前疫情仍在大范围持续传播[2]。新型冠状病毒具有高度传染性,可通过接触、飞沫、气溶胶等空气载体传播,在适宜环境中可存活5天[3]‐[4]。国家卫生健康委员会发布的《新型冠状病毒感染肺炎防控指南》强调,个人在前往公共场所、就医及乘坐公共交通工具时,需佩戴医用外科口罩或N95口罩,以防止病毒传播。因此,在疫情期间佩戴口罩是每个人在公共场所应尽的责任,但这不仅需要个人自觉遵守,还需采取一定措施进行监督和管理。
目前,尽管尚无专门应用于口罩佩戴检测的算法,但随着深度学习在计算机视觉领域的发展,基于神经网络的目标检测算法已被广泛应用于行人目标检测、人脸检测和遥感图像目标检测、医学图像检测以及自然场景文本检测等领域。人脸识别算法依赖于高精度的识别能力,在课堂考勤、身份认证、门禁系统、登录与解锁,以及社交媒体平台[12]等方面具有巨大的应用潜力。
目前,市场上的人脸识别设备功能相对单一,对人脸的要求较高,当人脸处于大面积遮挡状态时,识别精度会迅速下降。特别是在当前全民佩戴口罩的疫情形势下,传统人脸识别系统的能力显得捉襟见肘。考虑到我们需在保障人们安全的前提下尽力恢复生产和工作,因此设计了一套智能口罩佩戴检测与识别系统。该系统主要由口罩检测算法和人脸识别算法组成。系统的主要功能可分为三部分:口罩检测、人脸识别和语音提示。当多名行人经过摄像头时,配备该算法的摄像头会首先检测行人的口罩佩戴情况。当行人正确佩戴口罩时,不会发出语音提示;当行人佩戴口罩不规范时,语音会播报提醒其正确佩戴口罩;当行人未佩戴口罩时,系统将触发人脸识别模块,播报其姓名并提醒其佩戴口罩。该系统可应用于高铁站、地铁、商场等人员密集场所。
通过研究相关目标检测算法,发现用于人脸检测的深度学习模型可应用于口罩佩戴检测任务。本文采用更为精确的人脸检测算法RetinaFace[13]作为口罩人脸检测的基础算法,并在此基础上对RetinaFace算法的网络结构进行改进,引入注意力机制以满足新功能的需求;在本系统中,我们计算口罩与人脸关键点的位置,并返回不同人脸上佩戴口罩的置信度,以判断人是否标准佩戴口罩。计算快速且准确,算法稳定高效;对于当前主流的人脸识别方法,我们采用DeepFace[14]算法。该算法将人脸识别问题划分为若干相关子问题,每个子问题由一个机器学习算法完成,并通过以下四个步骤构建流水线来实现人脸识别。
(1) 找出图片中所有人脸
(2) 调整人脸的不同姿态
(3) 对人脸进行编码
(4) 从代码中查找人的姓名
考虑到系统需要检测和识别不同的人脸姿态、各种光照以及其他实际场景,在收集和比对戴口罩人脸数据集后,本项目最终选用了WIDER FACE[15]数据集和MAFA[16]数据集。共有7959张图像,其中训练集6067张,验证集300张,测试集1592张。并对数据进行了颜色反转、随机裁剪和水平翻转等数据预处理操作;此外,系统还增加了语音提示功能,当检测到未佩戴或佩戴不规范时,将通过调用win32API SPIVOICE语音合成服务及时向人员广播信息。
II. 方案论证与设计
由于目前尚无专门应用于口罩佩戴检测的算法,传统的单目标识别算法功能相对单一,对人脸完整性和光照强度要求较高,应用场景受限。为此,我们设计了一套针对高密度人流场景下的多目标口罩佩戴智能检测与识别系统。
系统的主要流程如图1所示:

设计了以下四个主要功能模块:
(1)在口罩检测方面,我们对常用的RETINAFACE人脸算法进行了改进,并在此基础上增加了口罩检测功能,能够实时检测人是否佩戴口罩,高效且稳定。同时,也拓宽了算法应用的领域。首先通过摄像头获取一帧数据,然后通过改进的RETINAFACE算法对图像进行处理,识别并定位关键点。通过人脸检测算法检测人脸,然后利用目标检测算法定位口罩的位置,如果口罩覆盖了包括鼻子和嘴巴在内的人脸关键点,则判定人员规范佩戴口罩,并在界面上用绿色框标记人脸;如果口罩仅覆盖鼻子和嘴巴以下的人脸关键点,则认为口罩佩戴不规范,在界面上用人脸外的橙色框标记,并显示佩戴口罩的置信度。
(2)关于口罩佩戴不规范的检测,我们计算口罩和人脸关键点的位置,返回戴口罩的置信度,对比阈值信息,判断人是否标准佩戴口罩。
(3) 在人脸识别方面,我们采用高性能且广泛应用的DEEPFACE人脸识别库,将人脸库图像编码并转换为128位测量值,然后对视频帧进行同样的处理,将处理后的数据与人脸编码库中的数据进行比对查找,返回最接近的认知人脸库中的测量值,从而获得人的姓名。之后通过声音广播该人的姓名和警告信息,提示该人佩戴口罩。
(4) 在语音广播方面,首先获取Windows API的COM对象,通过Windows API调用系统的底层语音合成服务,然后传入需要广播的信息,提醒未佩戴口罩或未正确佩戴口罩的人员佩戴口罩,以降低感染风险。
三、算法设计
A. RETINAFACE算法原理
由于RETINAFACE算法仅能实现人脸检测,无法满足本项目实际场景的需求,因此本文在RETINAFACE算法的基础上进行了改进。3.2.1节介绍了RETINAFACE算法的原理以及口罩检测的基本网络,3.2.2节介绍了基于RETINAFACE算法为实现特定功能所做的改进。
RETINAFACE是一种鲁棒的单级人脸检测算法。该算法利用多任务联合附加监督学习和自监督学习的优势,实现对不同尺度人脸的像素级定位。该算法融合了特征金字塔网络、上下文网络和任务联合等优秀的建模思想。
1) RETINAFACE特征提取网络
在RETINAFACE算法中,使用了从P2到P6的五个层级的特征金字塔,其中P2到P5通过相应的残差网络(残差网络[18])输出的特征图(C2到C6)进行自上而下和横向连接计算。P6是通过对C5进行卷积采样得到的,使用大小为3×3、步长为=2的卷积核。C1到C5在ImageNet‐11数据集上采用ResNet‐512。训练后的残差层[19]对P6层使用“XAVIER”方法[20]进行随机初始化。
RETINAFACE算法采用五个独立上下文模块,对应P2到P6的五个特征金字塔层级,以扩大感受野范围,并增强鲁棒的上下文语义分割能力。此外,使用可变形卷积网络(DCN)[]替代上下文模块中的3×3卷积层,进一步增强了非刚性上下文建模能力。
2) RETINAFACE多任务损失函数
对于训练好的锚框I,多任务联合损失函数定义为:
$$
L = L_{cls}(p_i, p_i^
) + \lambda_1 L_{box}(t_i, t_i^
) + \lambda_2 L_{pts}(l_i, l_i^*)
$$
其中,$L_{cls}$为分类损失函数,$p_i$表示锚框包含预测目标的概率,$p_i^ \in (0,1)$表示负锚框和正锚框。$L_{box}$为目标检测框回归损失函数,$t_i = {x,y,w,h}$表示与正锚框相关的预测框的坐标信息,同理,$t_i^ $表示与负锚框相关的预测框的坐标信息。$L_{pts}(l_i, l_i^ )$为面部关键点回归损失函数,$l_i = {x_1,y_1,…,x_5,y_5}$和$l_i^ $分别为正锚框预测的五个面部关键点和标注的五个面部关键点。$L_{pixel}$表示面部密集点的回归损失函数。
$\lambda_1$、$\lambda_2$和$\lambda_3$为损失平衡权重参数,在RETINAFACE算法中分别设置为0.25、0.1和0.01,意味着在监督学习中加入了检测框和面部关键点的信息。
B. 改进的RETINAFACE算法
该改进算法框架分为三部分:特征金字塔网络、上下文网络和多任务联合损失。其中,特征金字塔中的骨干网络为ResNet‐512,用于特征提取,并引入注意力机制模块以增强特征图的表达能力。在多任务联合损失中,舍弃了无关的人脸密集点回归损失,提高了算法模型的训练速度和效率。
1) 特征提取网络
使用预训练ResNet‐512作为特征金字塔网络的骨干网络进行特征提取。除了第一层的7×7卷积外,其余4层均由残差连接单元组成。对于RES_N层,包含n个A型残差连接单元。采用残差连接可有效解决深度网络训练中的梯度消失或梯度爆炸问题。
在残差连接单元中,对于输入特征向量x和输出特征向量y,残差连接建立的计算公式为:
$$
y = V(f(x,W) + x)
$$
其中,V表示修正线性单元(Rectified Linear Unit, ReLU)激活函数,$W_i$表示权重参数,$f(x,W_i)$表示需要学习的残差映射。对于图中的三层残差连接单元,其计算方法如公式(3)所示。加法操作通过捷径连接和逐元素相加实现,相加之后再次使用ReLU激活函数进行非线性化。
$$
y = V(W_3(V(W_2(V(W_1x)))) + x)
$$
2) 改进的自注意力机制
该系统在口罩人脸检测算法中引入了注意力机制模块,其内部结构如图2所示,主要包括金字塔注意力机制(PAM)[21]和自注意力机制(Self‐Attention, SA)[22]。金字塔注意力机制能够增强特征图的表达能力,而自注意力机制可以更好地利用特征之间的关联关系,提升注意力特征图的描述能力。

3) 多任务联合损失
基于人脸检测算法RetinaFace的损失函数,为了提高算法的训练速度和检测效率,本系统仅保留相关的分类损失、检测框回归损失和面部关键点回归损失,并对其进行优化,移除了面部密集点和返回损失。总损失函数表示为:
$$
L = L_{cls}(p_i, p_i^
) + \lambda_1 L_{box}(t_i, t_i^
) + \lambda_2 L_{pts}(l_i, l_i^*)
$$
各变量定义如公式(1)所示,其中分类损失$L_{cls}(p_i, p_i^ )$通过交叉熵损失函数实现两类分类(完整人脸和戴口罩人脸)。检测框回归损失$L_{box}(t_i, t_i^ )$采用Smooth‐L1损失函数。面部关键点回归$L_{pts}(l_i, l_i^*)$使用Smooth‐L1损失函数对五个检测到的面部关键点进行归一化处理。此外,本文将损失平衡权重参数$\lambda_1$和$\lambda_2$分别设置为0.3和0.1。
C. 非标准戴口罩检测原理
1) 面部关键点检测原理
人脸关键点检测是人脸识别与分析领域中的关键步骤,是前提和突破口。正确检测口罩的关键点。因此,我们对基于深度学习方法的人脸关键点检测进行了研究,并在人脸标注了68个关键点,如图所示。从图3可以看出,我们使用眼睛、鼻子和嘴巴作为关键点来检测口罩是否佩戴正确。从图中发现,佩戴口罩后,脸颊以及嘴巴和鼻子的关键点发生了不同程度的偏移。输出鼻中心与眉毛之间的距离以及置信度,以此作为判断是否佩戴口罩的标准。
2) 实现
为了减少干扰并准确检测口罩,我们首先使用FACE_LOCATION函数快速定位人脸,返回人脸、鼻子、眼睛等关键点数据,然后调用DETECT_MASK函数检测人脸位置处的口罩特征信息,并计算置信度。返回是否佩戴口罩的标签信息、人脸位置坐标等。由于图像中可能存在多张人脸,需要循环读取人脸位置信息。为了快速处理口罩分类检测,我们根据返回的标签信息,将FACE_LOCATION返回的结果分别存储到NOMASKDATA和MASKDATA数组中。
D. 人脸识别
人脸识别通常包含几个部分:首先,在图片中找到所有人脸(检测到人脸)。对于每张人脸,无论光线明亮或昏暗,或是不同的人脸姿态,仍能识别出同一个人的脸。然后,可以找出每张人脸用于区分他人的独特特征,例如眼睛的大小、人脸的长度等。最后,将这张人脸的特征与所有已知人脸进行比较,以确定人的姓名。这些问题需要将多个机器学习算法连接起来,构建一个流水线,使得前一步的输出可作为下一步的输入,从而启动流水线运行。
(1)
人脸检测
。使用方向梯度直方图(Histogram of Oriented Gradients),简称HOG的方法。在该HOG图像中寻找人脸。找出图像中与某些已知HOG模式最相似的部分。
(2)
人脸的不同姿态
。在将图像中的人脸分离后,接下来需要处理的问题是同一张人脸朝向不同方向的情况,这会带来不同的挑战。典型的处理方法是使用人脸地标估计算法。其基本思想是找到人脸上的特定点(称为地标点),这些点在68个关键点上具有共性——包括下巴顶端、每只眼睛的外轮廓以及每条眉毛的内轮廓。然后训练一个机器学习算法,使其能够在任何人脸上找到这68个关键点。进行一些变换以保持图像相对平行,例如,进行仿射变换来旋转和缩放图像。
(3)
面部编码
。训练一个深度卷积神经网络,并用它为面部生成128个测量值。将复杂的原始数据(如图片)缩减为计算机可生成的一系列数字的方法,并对面部信息数据库的图像进行编码以生成128位测量值。训练卷积神经网络输出面部嵌入的过程需要大量数据和强大的计算能力。在花费一定时间后,获得面部编码库。
(4)
从编码中找出人的姓名
,训练一个机器学习分类算法,使用它查找测试图像的测量值与数据库中最接近的人的编码值,并返回姓名。
人脸识别的整体过程如图4所示:
第四节 实验结果与分析
为了验证训练好的口罩检测模型和人脸识别模型在复杂场景中的能力,本实验通过设置一些评估指标进行评价,并使用真实场景检测与识别视频。
A. 评估指标
本项目将对口罩检测算法进行评估,并使用第4.1.1节中设置的1592张图片进行实验测试分析。评估指标采用目标检测领域常用的ROC曲线(受试者工作特征曲线)[24]、平均精度AP(Average Precision)和平均平均精度MAP(Mean Average Precision),以评估算法在面部及口罩佩戴检测上的检测效果。其中,当AP值为红色时,单个目标的检测效果计算如下:
$$
AP = \int_0^1 p(r) \, dr
$$
其中,$p(r)$是真正率与召回率之间的映射关系。真正率和召回率的计算方法为:
$$
p = \frac{TP}{TP + FP}
$$
$$
r = \frac{TP}{TP + FN}
$$
其中,TP(真阳性,真正数)表示被预测为正样本的正样本数量,FP(假阳性,假阳性数)表示被预测为正样本的负样本数量,FN(假阴性,假阴性数)表示被预测为负样本的正样本数量。本文基于真正率与假阳性数之间的关系绘制ROC曲线,以表达目标检测的性能。
B. 系统整体功能实现
系统已完成预期设计,实现了人脸检测、口罩佩戴检测、佩戴规范检测、人脸识别、语音提示等功能。系统开启后,在摄像头的可检测范围内,可在自然场景下实现实时多人检测、识别和提示。
C. 口罩检测实验结果
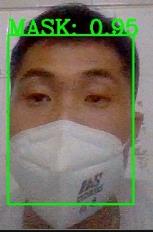
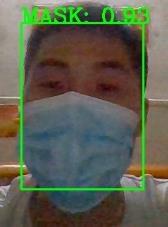
为了充分验证测试系统,我们进行了两组实验:不同类型口罩、多人测试的两个部分,如下图所示。从图中可以看出,无论何种情况,系统均能正确判断。该系统稳定且通用,易于应用。
对于模型性能,我们使用ROC曲线来评估口罩识别模块。ROC曲线图是一条反映灵敏度与特异性之间关系的曲线。横坐标X轴为1−特异性,也称为假阳性率(false positive rate),X轴越接近零,准确率越高;纵坐标Y轴称为灵敏度,也称为真正率(sensitivity),Y轴越大,准确性越好。
$$
\text{Sensitivity} = \frac{TP}{TP + FN}
$$
$$
\text{Specificity} = \frac{TN}{TN + FP}
$$
我们与RETINAFACE进行比较,结果如下:

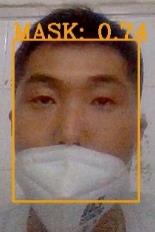
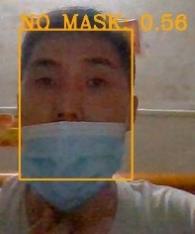
D. 口罩不规范佩戴测试结果
对于此类实验,我们设计了三组实验:遮盖口鼻、露出鼻子和口罩在嘴下。结果如下所示。口罩不规范检测部分依赖于返回的置信度和阈值的选择。我们以0.1为步长,从0.1到1.0选择阈值。实验结果如图8所示。

E. 人脸识别实验结果
我们在WILDER数据集上测试和训练人脸识别模型,并使用ROC曲线来衡量模型的性能。观察到ROC曲线0.6处急剧上升,AUC面积达到0.94,表明模型的分类明显,效果显著。

五、未来工作
针对系统实际设计过程中遇到的若干问题,我们计划从以下几个方面对口罩佩戴智能检测与识别系统进行改进:
(1) 为了增强应用区域的灵活性,未来可将口罩佩戴智能检测与识别系统移植到移动终端。通过开发一个简单的应用程序,可在任何需要检测与识别的区域部署移动终端,从而实现更实用的目的。
(2) 为了使系统能够在各种计算能力较弱的机器上运行,我们计划在未来设计一个更简单的网络,减少模型中的参数数量,降低训练成本,并提高系统与机器的兼容性。


















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









