




 本文介绍了链表的概念及其分类,重点讨论了不带头结点的单链表与带头结点的单链表的区别,包括初始化和操作上的差异。不带头结点的链表在处理第一个节点时需要特殊操作,而带头结点的链表则能简化这些操作,并有利于统一空表和非空表的处理。文章还概述了不带头结点单向链表的基本操作。
本文介绍了链表的概念及其分类,重点讨论了不带头结点的单链表与带头结点的单链表的区别,包括初始化和操作上的差异。不带头结点的链表在处理第一个节点时需要特殊操作,而带头结点的链表则能简化这些操作,并有利于统一空表和非空表的处理。文章还概述了不带头结点单向链表的基本操作。
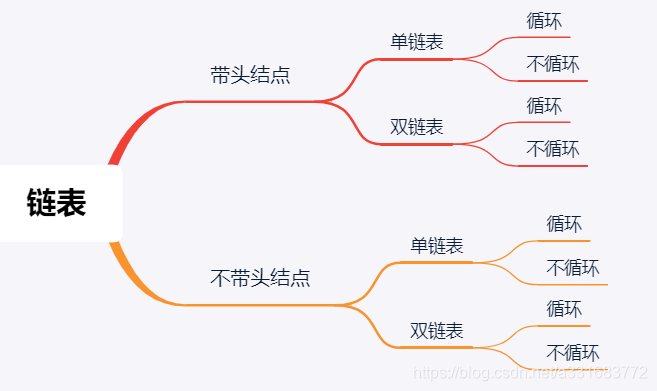
一. 什么是链表,链表的分类?
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的。
分类:
1.单链表
不带头节点
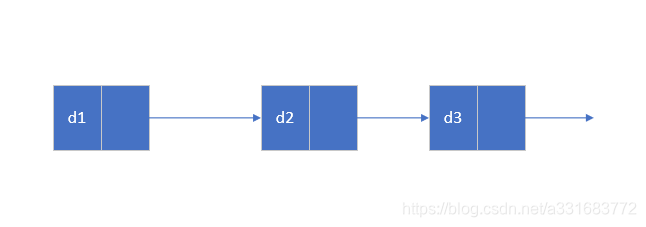
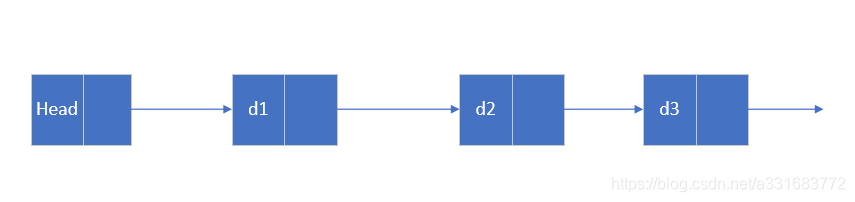
带头结点
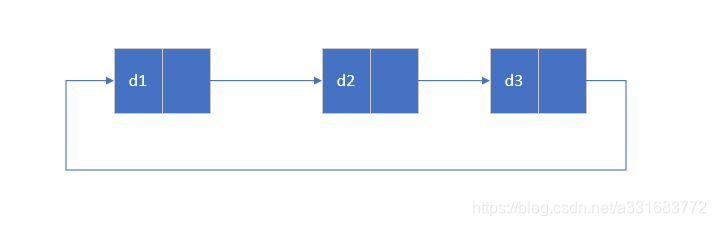
循环单链表
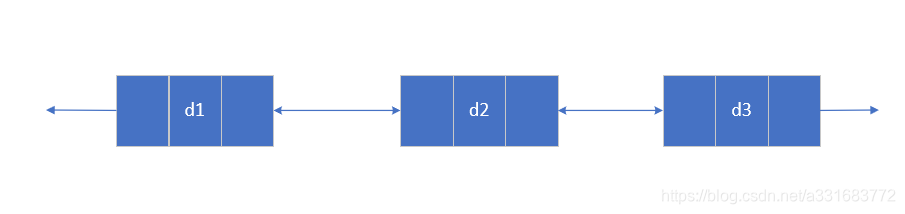
2.双向链表
不带头节点
带头结点的

循环双链表
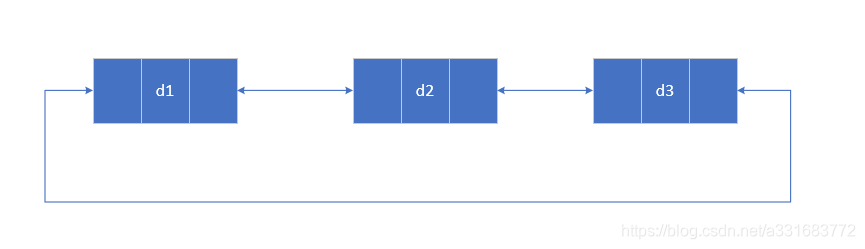
最后总结如下:
二. 链表带头结点和不带头结点的区别?
初始化不同:不带头结点的单链表对于第一个节点的操作与其他节点不一样,需要特殊处理,这增加了程序的复杂性和出现bug的机会,因此,通常在单链表的开始结点之前附设一个头结点。 带头结点的单链表,初始时一定返回的是指向头结点的地址,所以一定要用二维指针,否则将导致内存访问失败或异常。
引入头结点虽然会使链表变得复杂,但会有以下优势:
1.可以更快删除/插入第一个结点
2.能够统一空表和非空表的处理
注:链表是否有头结点,头指针始终指向链表的第一个结点。如果有头结点,头指针就指向头结点。
三、 单链表的基本操作(不带头结点单向链表)
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SDataType;
typedef struct SListNode
{
SDataType _data;
struct SListNode* _pNext;
}Node,*PNode;
typedef struct SList
{
PNode _pHead;
}SList,*PSList;
//链表初始化
void SListInit(SList *s)
{
assert(s);
s->_pHead = NULL;
}
//创建一个节点
Node *BuyNode(SDataType data)
{
Node* pNewNode = (Node *)malloc(sizeof(Node));
pNewNode->_data = data;
pNewNode->_pNext = NULL;
return pNewNode;
}
//销毁节点
void SListDstoryNode(Node *node)
{
assert(node);
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









