



>- **🍨 本文为[🔗365天深度学习训练营(https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.youkuaiyun.com/)**
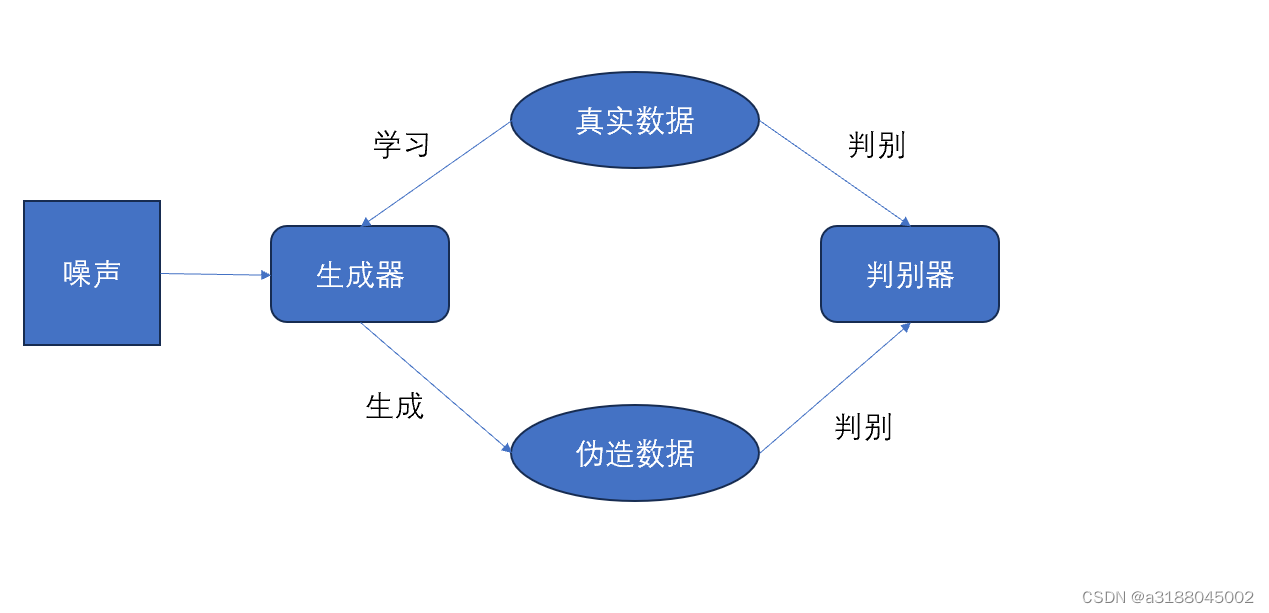
一,基础理论
生成对抗网络(GAN)是近几年神经网络的一个热门的方向。GAN指的是一类基于博弈思想而设计的网络。GAN主要有两个部分组成,分别是生成器和判别器。其中,生成器是从某种噪声分布中随机采样作为输入,输出和训练样本很相似的人工样本。判别器的输入则是真实样本和人工样本,其目的是尽可能地将真实样本和人工样本区分出来。这样,生成器和判别器之间相互博弈,双方的水平得到提升。理想的情况是判别器无法判别出样本的真实性,无论生成什么样的样本都输出50%的真,假概率。这样就获得了一个具有制造伪造样本的生成器。
1.生成器
GANs,生成器G选取噪声z作为输入,通过生成器不断地拟合,最终输出一个和真实样本尺寸一样,分布相似的伪造样本G(z)。生成器原本是一个使用生成式方法的模型,它对数据的分布假设进行学习,然后根据学习到的模型重新采样出新的样本。
从数学的角度上来讲,生成器是先假设一个数据分布,然后将真实数据输入进去,去学习真实数据里面的显示变量和隐式变量,最后得到一个和真实数据相似的数据分布。而机器学习就没有假设的部分,它是直接进行训练,然后对分布假设里面的参数进行修改,最后得到一个数据分布。
2.判别器
GANs中,判别器D对输入样本x,输出一个[0,1]的概率值D(x)。这里的x既可以来自真实数据,也可以来自生成器D(z)。通常约定D(x)越接近1,就代表生成的数据来自真实数据的可能性就越大,反之就来自生成器。这里面判别器的作用是辨别数据的真伪,而不是判断数据的类别,GANs的学习过程是一个无监督的过程。
代码如下
import os
import torch
import numpy as np
import torch.nn as nn
from torchvision import datasets
from torchvision.utils import save_image
import torchvision.transforms as transform
from torch.autograd import Variable
from torch.utils.data import DataLoader
这些是需要的相关库
os.makedirs("./images/", exist_ok=True)
os.makedirs("./save/", exist_ok=True)
os.makedirs("./datasets/mnist/", exist_ok=True)
创建相关的文件夹
n_epochs = 50
batch_size = 128
lr = 0.0002
b1 = 0.5
b2 = 0.999
n_cpu = 1
latent_dim = 100
img_size = 28
channels = 1
sample_interval = 500
相关的参数
img_shape = (channels, img_size, img_size)
img_area = np.prod(img_shape)
# 设置cuda:(cuda:0)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
mnist = datasets.MNIST(
root='./datasets/', train=True, download=True, transform=transform.Compose(
[transform.Resize(img_size), transform.ToTensor(), transform.Normalize([0.5], [0.5])]),
)
dataloader = DataLoader(
mnist,
batch_size=batch_size,
shuffle=True
)
这里下载MNIST手写数据集,然后加载数据集。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(img_area, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
这里是判别器的网络,主要是将输入的图像进行真伪的判别。
class Generate(nn.Module):
def __init__(self):
super(Generate, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, img_area),
nn.Tanh()
)
def forward(self, z):
imgs = self.model(z)
imgs = imgs.view(imgs.size(0), *img_shape)
return imgs
这里时生成器的网络,这段代码的主要功能是将输入的噪声转换成和真实图片尺寸一样的伪造图片。
generator = Generate()
discriminator = Discriminator()
criterion = torch.nn.BCELoss()
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
if torch.cuda.is_available():
generator = generator.to(device)
discriminator = discriminator.to(device)
criterion = criterion.to(device)
由于是二分类的任务,所以这里使用的时BCEloss函数。这里还定义了生成器和判别器的损失函数。我这里使用的是GPU进行训练。
for epoch in range(n_epochs): # epoch:50
for i, (imgs, _) in enumerate(dataloader):
## =============================训练判别器==================
## view(): 相当于numpy中的reshape,重新定义矩阵的形状, 相当于reshape(128,784) 原来是(128, 1, 28, 28)
imgs = imgs.view(imgs.size(0), -1) # 将图片展开为28*28=784 imgs:(64, 784)
real_img = Variable(imgs).cuda() # 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度
real_label = Variable(torch.ones(imgs.size(0), 1)).to(device) ## 定义真实的图片label为1
fake_label = Variable(torch.zeros(imgs.size(0), 1)).to(device) ## 定义假的图片的label为0
## ---------------------
## Train Discriminator
## 分为两部分:1、真的图像判别为真;2、假的图像判别为假
## ---------------------
## 计算真实图片的损失
real_out = discriminator(real_img) # 将真实图片放入判别器中
loss_real_D = criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
## 计算假的图片的损失
## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新
z = Variable(torch.randn(imgs.size(0), latent_dim)).to(device) ## 随机生成一些噪声, 大小为(128, 100)
fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。
fake_out = discriminator(fake_img) ## 判别器判断假的图片
loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的loss
fake_scores = fake_out ## 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
## 损失函数和优化
loss_D = loss_real_D + loss_fake_D # 损失包括判真损失和判假损失
optimizer_D.zero_grad() # 在反向传播之前,先将梯度归0
loss_D.backward() # 将误差反向传播
optimizer_D.step() # 更新参数
## -----------------
## Train Generator
## 原理:目的是希望生成的假的图片被判别器判断为真的图片,
## 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
## 反向传播更新的参数是生成网络里面的参数,
## 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的, 这样就达到了对抗的目的
## -----------------
z = Variable(torch.randn(imgs.size(0), latent_dim)).to(device) ## 得到随机噪声
fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片
output = discriminator(fake_img) ## 经过判别器得到的结果
## 损失函数和优化
loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的loss
optimizer_G.zero_grad() ## 梯度归0
loss_G.backward() ## 进行反向传播
optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数
## 打印训练过程中的日志
## item():取出单元素张量的元素值并返回该值,保持原元素类型不变
if (i + 1) % 300 == 0:
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"
% (epoch, n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(),
fake_scores.data.mean())
)
## 保存训练过程中的图像
batches_done = epoch * len(dataloader) + i
if batches_done % sample_interval == 0:
save_image(fake_img.data[:25], "./images/%d.png" % batches_done, nrow=5, normalize=True)
训练得到的结果如下所示:



















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









