






GPU需求数与算力需求和显存需求数有关,具体计算公式为:GPU需求数 = max(算力需求,显存需求)
1 算力需求
根据OpenAI发布的缩放定律:算力需求C6*P*D,其中P为模型参数量,D为数据量
1.1 语料+34B模型需要的浮点运算数
假设在增量预训练中,语料总量预计5B token:
D = 5B tokens = 5*10^9 tokens
34B模型表示其参数量:
P = 3.4×10^10
则总计算量:(FLOPs = Floating point operations)
C ≈ 6PD = 1.02 × 10^22 FLOPs(来源:OpenAI缩放定律论文)
1.2 浮点运算数折算GPU-hours(单位 每块GPU每小时)
1.2.1 显卡利用率计算
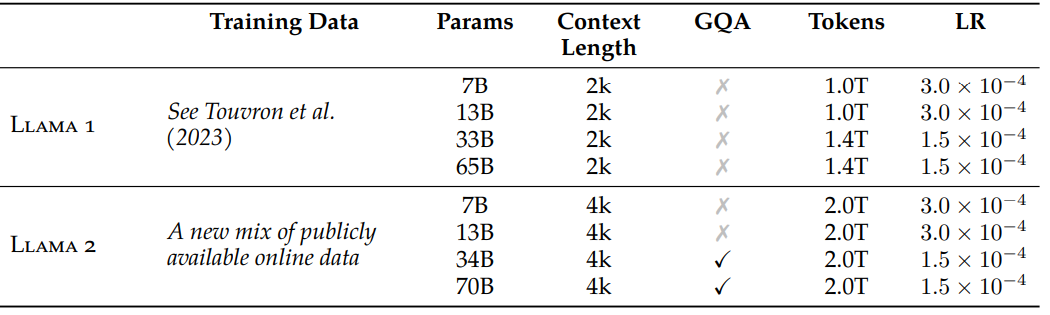
根据LLAMA2论文数据,可以推算出Meta训练策略中34B预训练模型的显卡利用率。
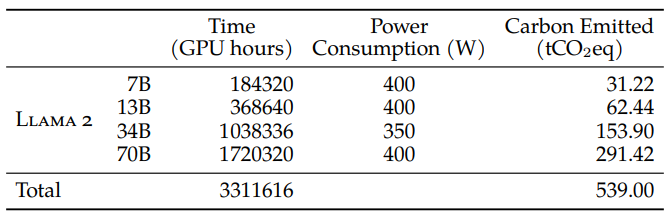
LLAMA2-7B的计算量为 6 × 7 × 10^9 × 2 × 10^12 = 8.4 × 10^22 FLOPs
其理论GPU-hours为(8.4 × 10^22 / 312 × 10^12) × (1/3600)= 74800 GPU hours
论文中的实际时间为184320,可以计算其A100显卡利用率为 74800/184320 ≈ 40.5%
同理得到不同规模模型的显卡利用率LLAMA2-34B(35.0%)、LLAMA2-70B(43.5%)。
1.2.2 A100峰值算力折算
上述A100稳态算力约为峰值算力的0.35,A100显卡算力:
312 TFLOPS × 0.35 = 109.2 TFLOPS(Tera Floating point operations per second)
则GPU-hours的计算如下
(1.09 × 10^22FLOPs) / (109.2 × 10^12 FLOPS) × (1/3600)= 27700 GPU小时
即1块A100需要27700小时(80块A100 80G 需要14.5天)计算完成。
三、显存需求
除了算力需求,GPU显存需求往往是制约训练的瓶颈。
仅放下34b的模型启动训练需要4-6张A100(80G),主要包括:
-
将模型加载到GPU
-
保存优化器状态、加载优化器参数
-
存储Transformer模型激活值
-
中间梯度保存
Memory = 模型内存 + 优化器状态使用量 + 激活值使用量 + 梯度使用量
实测34B模型的权重占用显存为70GB。采用AdamW优化器以及混合精度训练,优化器状态参数与中间梯度共占用至少四倍以上显存,因此需要4-6张A100(80G)。
训练过程的激活值占用约40-60张A100(80G)(来源chatGLM团队、Eleuther AI比例估算值)。
激活值所消耗的额外显存随batchsize的大小而增加,在batchsize较大时,此部分额外显存消耗远远大于模型参数的消耗,采用激活重计算技术可将中间激活显存从O(n)减少到O(√n)。
显存上限决定了batchsize的上限。业界计算激活值占用显存通常采用以下公式:
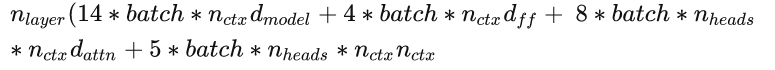
Llama 7b模型层数32层,隐藏层大小4096,中间隐藏层大小11008,注意力头数32,词表大小32000,上下文长度2048,那么当batchsize为32时,激活值占用显存为:
32 × (14 × 32 × 2048 × 4096 + 4 × 32 × 2048 × 11008 + 8 × 32 × 32 × 2048 × 4096 + 5 × 32 × 32 × 2048 × 2048)= 3.1e12 = 3100GB
可估算得40-60张A100最高支持CodeLlama34b模型的batchsize为64。
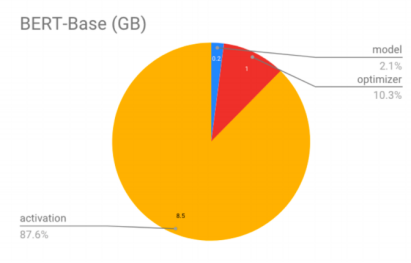
考虑到多卡部署时梯度更新过程的通信损耗,共需约(44~66)× 1.2 = (52~80)张A100(80G)。
补充说明——A100与A800的换算关系及影响估算
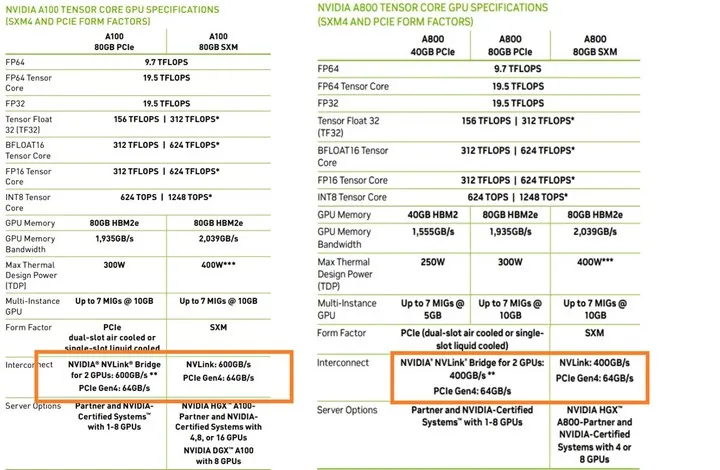
从官方给出的技术规格上来看,在模型训练中最关注的显存与算力参数完全一致,80GB版本GPU显存带宽一致。
唯一的区别在于NVLink互联桥的带宽下降至400GB/s,不满足美国的“每秒600GB及以上”的出口限制(NVLink——GPU间高速大带宽直连通信的互连技术)
在分布式训练中多GPU间数据传输频繁,各训练加速框架例如accelerate、deepspeed等支持的ZeRO算法涉及梯度、优化器状态、模型权重参数甚至激活值的通信,数据传输速率的下降提高了通信时长。
卡间通信延长对训练时长的影响未有明确测算公式,根据现有实例推测:H800相对于H100也仅有卡间通信速率的下降(约50%),其在执行训练任务时,H800消耗比H100多10%-30%的时间。
A800相对A100在数据传输速率有33%的下降,预计约有5%的训练耗时增加。
因此执行增量预训练任务时,鉴于数据规模较小且训练周期较短,认为可以与A100进行1:1的等量换算。
读者福利:倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

学习路上没有捷径,只有坚持。但通过学习大模型,你可以不断提升自己的技术能力,开拓视野,甚至可能发现一些自己真正热爱的事业。
最后,送给你一句话,希望能激励你在学习大模型的道路上不断前行:
If not now, when? If not me, who?
如果不是为了自己奋斗,又是为谁;如果不是现在奋斗,什么时候开始呢?

















 4281
4281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









