




1 引言:为什么要用 Transformer 做风电功率预测?
风电功率时间序列有几个典型特征:
-
强非线性:风速、风向、空气密度、湍流度、机组运行状态等共同作用;
-
多变量耦合:不仅仅是一个风速,而是一整套 NWP/测风塔/SCADA 特征;
-
长时依赖:阵风、风向回转、天气系统演变会在几十分钟甚至数小时后体现到功率上。
传统 LSTM/CNN 模型已经可以做出不错的预测,但在长序列依赖和并行计算效率上仍有瓶颈。
Transformer 通过多头自注意力(Multi-Head Self-Attention)在序列任意两个时间步之间“直接连线”,擅长从长时间窗的多变量序列里挖出模式。Matlab 从 R2023a/R2023b 开始提供了 selfAttentionLayer、positionEmbeddingLayer、indexing1dLayer 等层,支持构建时序 Transformer 网络,用于金融时间序列、文本和一般序列建模。(MATLAB 中心博客)
本文围绕一个典型场景展开:
多变量输入 + 单步预测:
给定过去 (L) 个时间步的多源特征(风速、风向、气象预报等),预测下一时刻(或下一 10 分钟)的风电有功功率。
并给出一份完整的 Matlab 实现示例,方便你直接在自己的风场数据上落地。
2 问题定义与整体建模思路
2.1 多变量单步预测场景
假设你已有按时间对齐好的数据表(例如 10 分钟分辨率):
-
时间戳:
time -
实测有功功率:
P(或Power) -
多个输入特征:
-
测风塔 / 机舱风速:
WS_10m,WS_100m,WS_hub… -
风向:
WD(或按正交分解成u = WS*cos(dir)/v = WS*sin(dir)) -
温度、气压、空气密度等环境量:
Temp,Press,Rho… -
NWP 预报量:
WS_gfs,WS_ec,WD_gfs… -
机组/场站状态:可用容量、故障标记等。
-
目标是学习一个映射:
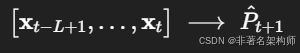
其中 (\mathbf{x}_t \in \mathbb{R}^{d}) 为第 (t) 个时间步的多变量特征,(L) 是窗口长度,输出为 (t+1) 时刻的功率。
2.2 Transformer 在风电预测中的优势
与 LSTM 相比,Transformer 在时间序列预测上的几个关键优势:(MATLAB 中心博客)
-
捕捉长时依赖能力更强
自注意力可以让每个时间步直接查看整个窗口内的其他时间步,不必逐步“记忆”。 -
多变量特征交互自然
多头注意力可以从不同“子空间”去关注不同量纲的特征(例如一头主看风速趋势,一头主看风向变化,一头主看 NWP 与实测残差等)。 -
更适合并行训练
对于固定长度窗口,Transformer 所有时间步可以在 GPU 上并行计算,相比 RNN 系列更高效。 -
可扩展性好
后期如果你要扩展到多步预测(sequence-to-sequence)或者加入更多辅助特征,只需要在网络尾部和损失函数上做一些改造即可。
2.3 模型总体流程
整体流程可以概括为:
-
数据预处理和特征工程
-
数据清洗、缺失值与异常值处理
-
统一时间分辨率与对齐
-
构建多变量特征矩阵
-
标准化(z-score)
-
-
滑动窗口构造样本
-
以窗长 (L) 构造序列样本 (\mathbf{X}_i \in \mathbb{R}^{d \times L})
-
每个序列的标签为下一时刻功率 (P_{t+1})
-
-
搭建 Transformer 时序回归网络(Matlab)
-
sequenceInputLayer(d)读取多变量序列 -
fullyConnectedLayer做线性特征嵌入(embedding) -
positionEmbeddingLayer+additionLayer引入位置信息 -
selfAttentionLayer进行多头自注意力建模 -
前馈网络(Feedforward)进一步提取非线性特征
-
indexing1dLayer("last")取最后一个时间步的表示 -
fullyConnectedLayer(1)输出单步功率预测
-
-
训练与评估
-
使用
trainnet+"mse"损失训练 -
指标:RMSE、MAE、MAPE 等
-
可视化预测曲线与误差分布
-
3 数据准备与特征工程
下面假设你已经有一个 CSV 文件:wind_data.csv,包含以下列(可按自己实际数据调整):
-
time:时间戳(可解析为datetime) -
Power:实测有功功率(单位 kW 或 MW) -
其余数值列全部作为特征(风速、风向、气象、状态等)。
3.1 读取与预处理
主要步骤:
-
时间排序
-
缺失值填补(这里用线性插值
fillmissing(...,'linear'),工程中可更精细) -
特征与目标做 z-score 标准化,方便网络收敛
4 Matlab 中基于 Transformer 的风电功率预测网络
注意版本:以下代码使用了
selfAttentionLayer、positionEmbeddingLayer和indexing1dLayer,需要 Matlab R2023a/R2023b 及以上版本的 Deep Learning Toolbox。(MathWorks)
4.1 模型结构设计(多变量输入 + 单步输出)
我们采用一个简化但完整的“单层 Encoder”结构:
-
输入:
sequenceInputLayer(numFeatures) -
线性嵌入:
fullyConnectedLayer(dModel)
将原始 d 维特征映射到 dModel 维的“时序表示空间”。 -
位置编码:
positionEmbeddingLayer(dModel, maxPosition)+additionLayer(2)
将位置嵌入与特征嵌入相加,形成带位置信息的表示。 -
自注意力:
selfAttentionLayer(numHeads, dModel, AttentionMask="causal")
使用因果掩码,保证每个时间步只看当前及过去的时间步,适合自回归预测。(MathWorks) -
前馈网络 + 非线性:
fullyConnectedLayer(4*dModel)→reluLayer→fullyConnectedLayer(dModel)
相当于 Transformer Encoder 中的 position-wise feedforward。 -
序列聚合:
indexing1dLayer("last")
从时间维度上取最后一个时间步的特征表示,作为整个窗口的“摘要”。(MathWorks) -
输出层:
fullyConnectedLayer(1)
直接回归出下一时刻的功率。
4.2 完整 Matlab 示例代码
提示:记得把 CSV 列名替换成你自己的数据列名(尤其是功率列名),窗口长度
windowSize、训练集比例等参数可以按场站实际情况调整。
%% ================== 0. 基础配置 ==================
clear; clc;
dataFile = "wind_data.csv"; % 风电场数据文件
windowSize = 24; % 滑动窗口长度(例如 24 个 10min 点 ≈ 4 小时)
trainRatio = 0.7; % 训练集比例
rng(2025); % 固定随机种子便于复现实验
%% ================== 1. 读取数据 & 预处理 ==================
T = readtable(dataFile);
% 假设列名为 time / Power,酌情修改
time = T.time;
power = T.Power;
% 其余所有数值列作为特征
featureTbl = removevars(T, {'time','Power'});
X_raw = featureTbl{:,:};
% 按时间排序
[time, idxSort] = sort(time);
power = power(idxSort);
X_raw = X_raw(idxSort,:);
% 缺失值简单线性插值(工程中可结合物理规则做更复杂处理)
power = fillmissing(power, 'linear');
X_raw = fillmissing(X_raw, 'linear');
% 去掉可能的全零或全 NaN 行(示例简单处理)
validMask = ~isnan(power) & all(~isnan(X_raw), 2);
time = time(validMask);
power = power(validMask);
X_raw = X_raw(validMask,:);
%% ================== 2. 标准化与滑动窗口构造样本 ==================
[numSamples, numFeatures] = size(X_raw);
% z-score 标准化
[X_norm, muX, sigmaX] = zscore(X_raw);
[power_norm, muY, sigmaY] = zscore(power);
% 滑动窗口:每个样本输入为 L 步特征,标签为下一时刻功率
numObs = numSamples - windowSize; % 可构造的样本数
XSeq = cell(numObs, 1); % 输入序列(每个 cell: numFeatures × windowSize)
Y = zeros(numObs, 1); % 输出标量(下一时刻功率)
for i = 1:numObs
idxWin = i:(i+windowSize-1); % 当前窗口
idxLabel = i + windowSize; % 对应的下一时刻
% 输入:numFeatures × windowSize
XSeq{i} = X_norm(idxWin, :).'; % 转置:行=特征,列=时间
% 标签:标量(归一化后)
Y(i) = power_norm(idxLabel);
end
% 划分训练/测试集(这里按时间前后切分)
numTrain = floor(numObs * trainRatio);
XTrain = XSeq(1:numTrain);
YTrain = Y(1:numTrain);
XTest = XSeq(numTrain+1:end);
YTest = Y(numTrain+1:end);
% 对应的真实时间(用于画图)
tTest = time(windowSize+1+numTrain : windowSize+numObs);
fprintf("总样本数: %d, 训练: %d, 测试: %d\n", numObs, numTrain, numObs-numTrain);
%% ================== 3. 构建 Transformer 时序回归网络 ==================
% 模型维度与超参数
dModel = 64; % 特征嵌入维度
numHeads = 4; % 注意力头数(需整除 dModel)
ffnFactor = 4; % 前馈层放大倍数
ffnDim = ffnFactor * dModel;
maxPosition = windowSize; % 序列最大长度
% 主干层(按顺序)
layers = [
sequenceInputLayer(numFeatures, Name="input")
% 线性特征嵌入:将原始特征映射到 dModel 维
fullyConnectedLayer(dModel, Name="fc_embed")
% 位置嵌入:根据时间位置生成可学习位置向量
positionEmbeddingLayer(dModel, maxPosition, Name="pos_emb")
% 将特征嵌入与位置嵌入相加
additionLayer(2, Name="add")
% 多头自注意力(因果掩码,保证只看当前及过去时间步)
selfAttentionLayer(numHeads, dModel, ...
AttentionMask="causal", Name="self_attn")
% 前馈网络(简化版 Transformer Encoder FFN)
layerNormalizationLayer(Name="ln1")
fullyConnectedLayer(ffnDim, Name="ffn1")
reluLayer(Name="relu1")
fullyConnectedLayer(dModel, Name="ffn2")
% 序列聚合:取最后一个时间步的表示(Index="last")
indexing1dLayer("last", Name="idx_last")
% 输出层:回归到 1 维功率
fullyConnectedLayer(1, Name="fc_out")
];
% 使用 dlnetwork + layerGraph 将嵌入层和位置层连接到 additionLayer 的两个输入
net = dlnetwork;
net = addLayers(net, layers);
% 主链路:input -> fc_embed -> pos_emb -> add (in1)
% 需要显式把 fc_embed 的输出也接到 add 的第二个输入
net = connectLayers(net, "fc_embed", "add/in2");
analyzeNetwork(net) % 如需可视化网络结构,可打开此行
%% ================== 4. 指定训练选项并训练 ==================
% 这里使用 trainnet(新 API),损失函数用 "mse"
% 训练选项可以根据需要微调
options = trainingOptions("adam", ...
MaxEpochs=80, ...
MiniBatchSize=64, ...
InitialLearnRate=1e-3, ...
GradientThreshold=1, ...
Shuffle="once", ...
SequenceLength="longest", ... % 固定长度窗口,直接用最长
Plots="training-progress", ...
Metrics="rmse", ...
Verbose=false);
% 训练 Transformer 网络
net = trainnet(XTrain, YTrain, net, "mse", options);
%% ================== 5. 测试集预测与反归一化 ==================
% 使用 minibatchpredict 在测试集上推理
YTest_pred_norm = minibatchpredict(net, XTest, SequenceLength="longest");
% 反归一化到原始功率尺度
YTest_true = YTest * sigmaY + muY;
YTest_pred = YTest_pred_norm * sigmaY + muY;
%% ================== 6. 误差指标与可视化 ==================
% 误差指标
err = YTest_pred - YTest_true;
RMSE = sqrt(mean(err.^2));
MAE = mean(abs(err));
MAPE = mean(abs(err ./ max(abs(YTest_true), 1e-6))) * 100;
fprintf("测试集 RMSE = %.3f, MAE = %.3f, MAPE = %.2f%%\n", RMSE, MAE, MAPE);
% 时间序列对比图
figure;
plot(tTest, YTest_true, '-', "LineWidth", 1.2); hold on;
plot(tTest, YTest_pred, '--', "LineWidth", 1.2);
xlabel("Time");
ylabel("Power");
title("风电功率预测:真实值 vs Transformer 预测值");
legend("真实功率","预测功率","Location","best");
grid on;
% 误差散点图
figure;
scatter(YTest_true, YTest_pred, 10, "filled");
xlabel("真实功率");
ylabel("预测功率");
title("预测值 vs 真实值 散点图");
hold on;
ax = axis;
plot([ax(1) ax(2)], [ax(1) ax(2)], "r--"); % y=x 参考线
grid on;
% 误差直方图
figure;
histogram(err, 50);
xlabel("误差 (预测 - 真实)");
ylabel("频数");
title("预测误差分布");
grid on;
5 结果解读与扩展方向
在上述示例中,你可以重点关注:
-
误差指标(RMSE/MAE/MAPE)
-
与基准模型(如简单持久性预测、线性回归、传统 LSTM)对比;
-
看在不同风速区间、不同季节/风向扇区下的表现。
-
-
预测曲线
-
是否能较好跟踪功率爬坡与回落;
-
极端工况(大风切出、低风停机)处是否有明显偏差。
-
-
误差分布
-
若误差集中在大功率区,可考虑在损失函数中增加对高功率段的权重(自定义加权 MSE)。
-
6 工程落地上的若干优化建议
-
多层 Encoder / 多头注意力
-
将
selfAttentionLayer+ FFN 这块堆叠 2–4 层可以增强表达力; -
增大
dModel或numHeads一般会提高精度,但也增加过拟合风险和训练成本。
-
-
加入更多物理特征
-
风速剖面(不同行高度)、垂直切变 (\alpha)、湍流强度,甚至简化的功率曲线残差特征;
-
NWP 与实测之间的偏差(bias)也可以作为额外输入,帮助模型感知预报系统误差。
-
-
多步预测扩展
-
可以将输出层
fullyConnectedLayer(1)改为fullyConnectedLayer(H),直接预测未来 H 个时间步; -
或使用 sequence-to-sequence 架构(编码器-解码器 Transformer)。
-
-
与 LSTM / CNN 的对比与融合
-
在 Matlab 中同时搭建 LSTM/CNN 模型,做精度和速度对比;
-
也可以在输入端先用 1D CNN 做局部模式提取,再接 Transformer。
-
-
版本兼容与降级方案
-
如果你的 Matlab 版本早于 R2023a/R2023b,没有
selfAttentionLayer等层,可以:-
暂时退回 LSTM 网络(
lstmLayer(OutputMode="last")+fullyConnectedLayer(1)); -
或自己实现简单的 attention 机制(用
functionLayer + dlarray自定义)。
-
-


















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











