




1.为什么要部署本地模型?
DeepSeek 隐私政策中提到了关于用户输入信息收集的条款,无论你输入什么文本,以及上传什么文件都会被第三方机构所收集,所以如果是在进行相关的项目研究或者实验进展分析的时候,就很有必要对数据进行隐私保护,且本地部署是支持离线的

2.Ollama下载
大模型不是一个双击就可以使用的.exe可执行文件,是需要平台来运行的一个东西,Ollama就是一个支持各种大模型本地部署的一个平台 ,用这个平台管理和大模型之间的输出和输入
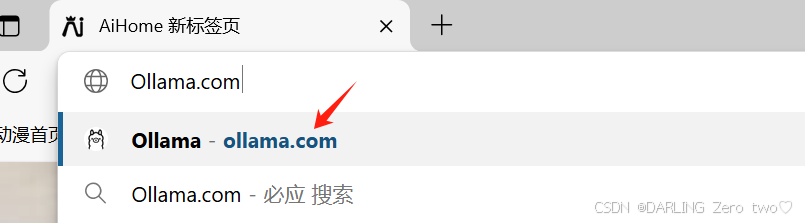
首先浏览器中输入Ollama.com网址,选择第一个

然后点击这里的下载按钮

继续点击下载按钮,根据自己电脑的版本选择,我这里选择的是Windows系统

在浏览器右上角下载处等待下载完成
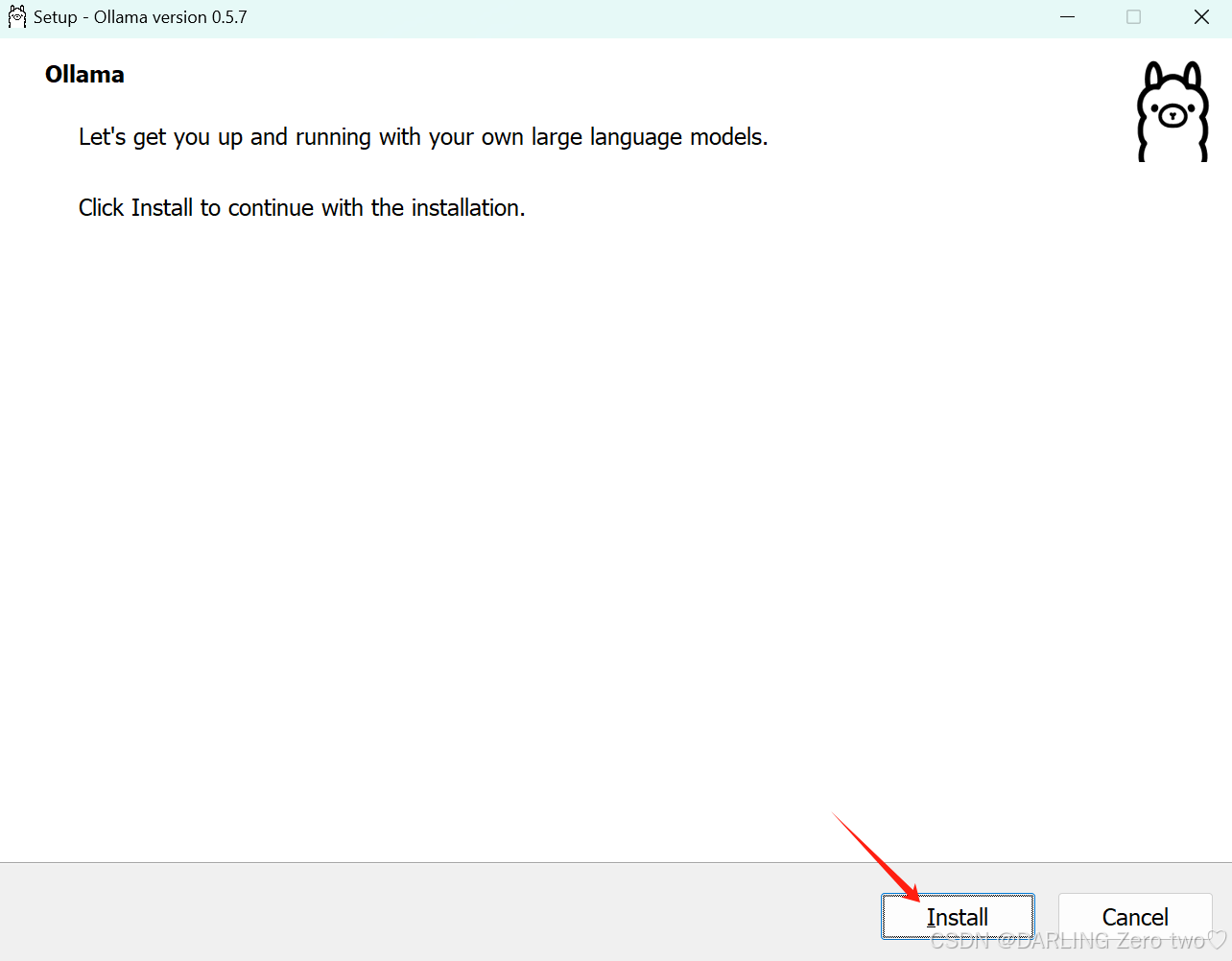
下载完后点击打开文件,弹出界面再点击Install下载,然后等待下载完成
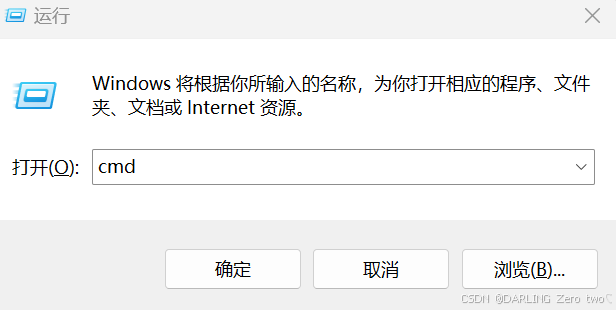
Ollama在桌面上不会生成桌面图标,所以我们win+R打开运行窗口,输入cmd打开命令行

然后输入ollama -v(中间有个空格),回车,会显示出版本号,说明已经安装成功了
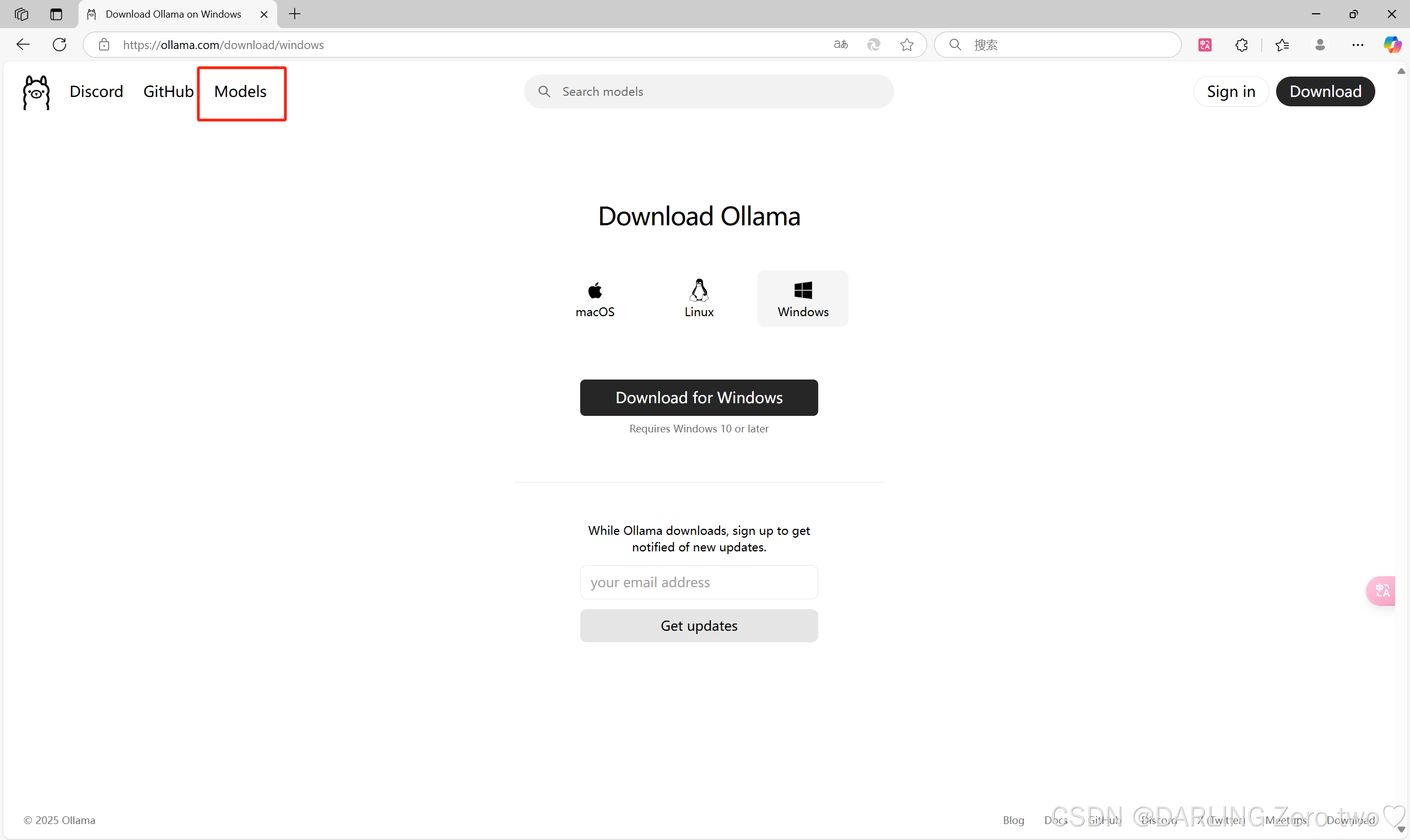
3.大模型下载部署
回到Ollama的网站,点击Models板块

接着点击deepseek-r1
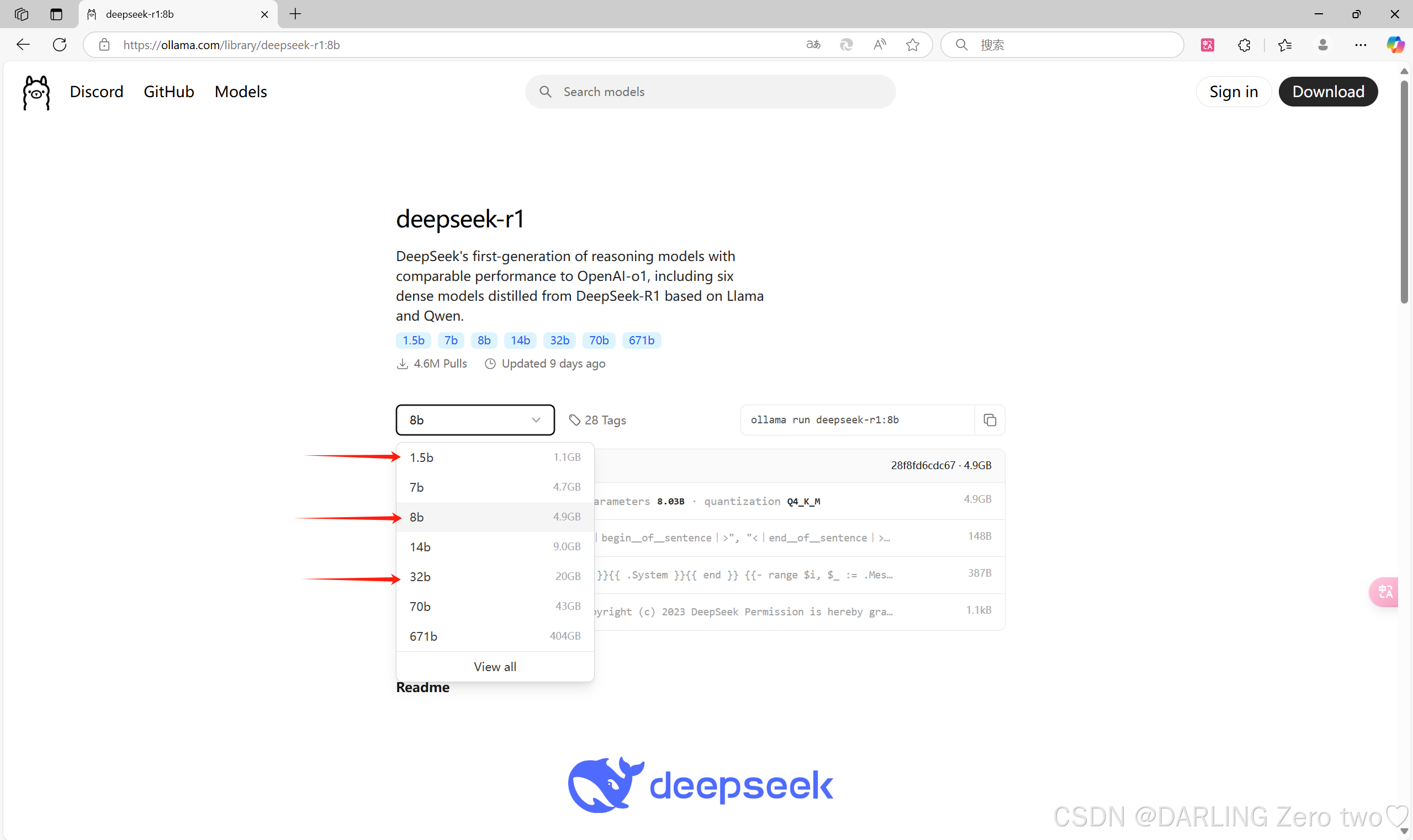
选择大模型的体积,体积越大使用效果越好,但是磁盘占用的空间就越大,所以根据自己电脑的磁盘空间选择,该模型一般下在C盘(也可以选择打开D盘新建仓库下载),这里建议选择1.5b、8b或者32b
模型和GPU显卡的适配表格以供参考:
| 模型 | 参数 (B) | VRAM 要求 (GB) | 推荐 GPU |
|---|---|---|---|
| DeepSeek - R1 - Zero | 671B | ~1,342 GB | 多 GPU 配置(例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 | 671B | ~1,342 GB | 多 GPU 配置(例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 - Distill - Qwen 1.5B | 1.5B | ~0.75 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 7B | 7B | ~3.5 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Llama 8B | 8B | ~4 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 14B | 14B | ~7 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 32B | 32B | ~16 GB | NVIDIA RTX 4090 24GB |
| DeepSeek - R1 - Distill - Llama 70B | 70B | ~35 GB | 多 GPU 配置(例如,NVIDIA RTX 4090 x2) |
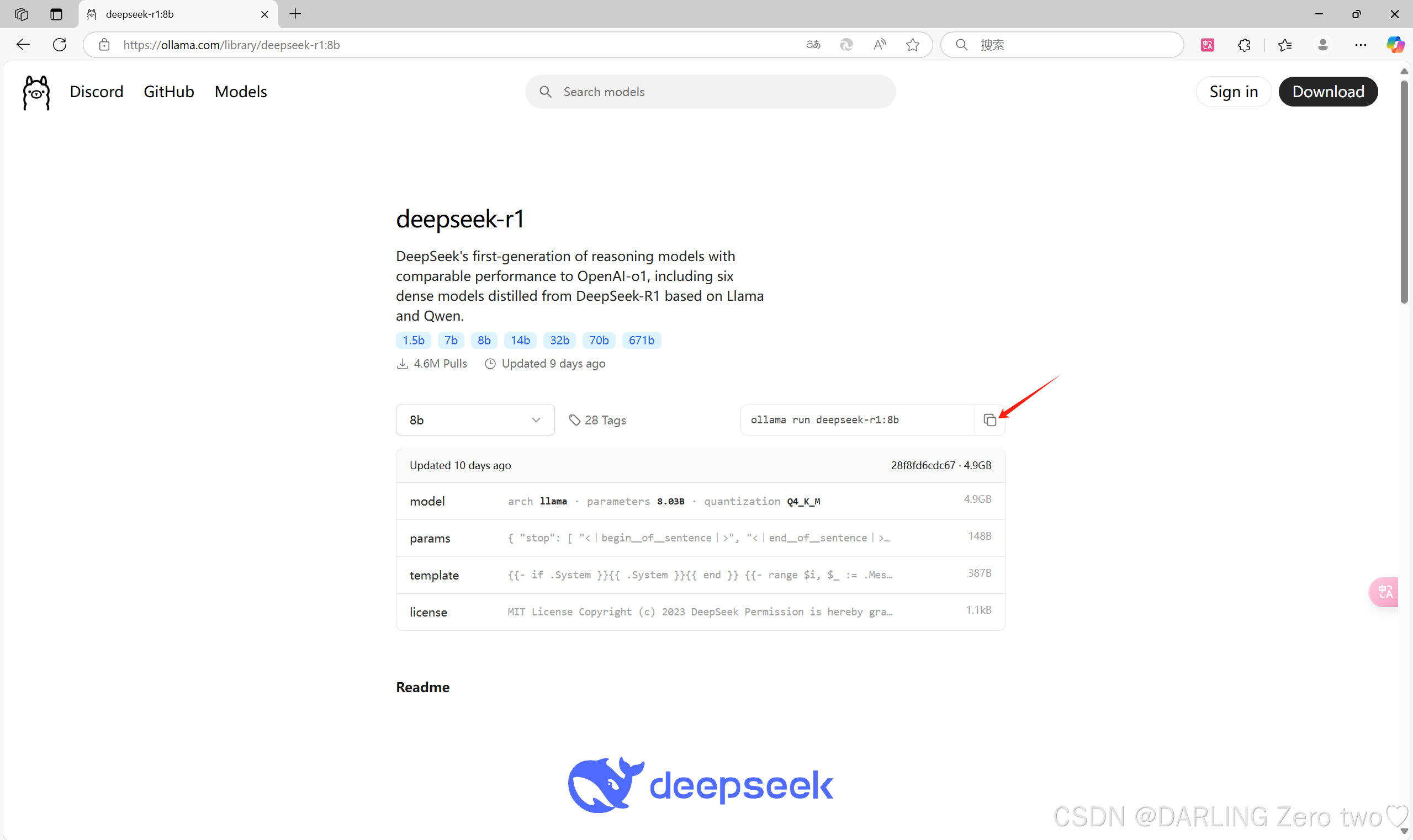
复制这里的下载命令
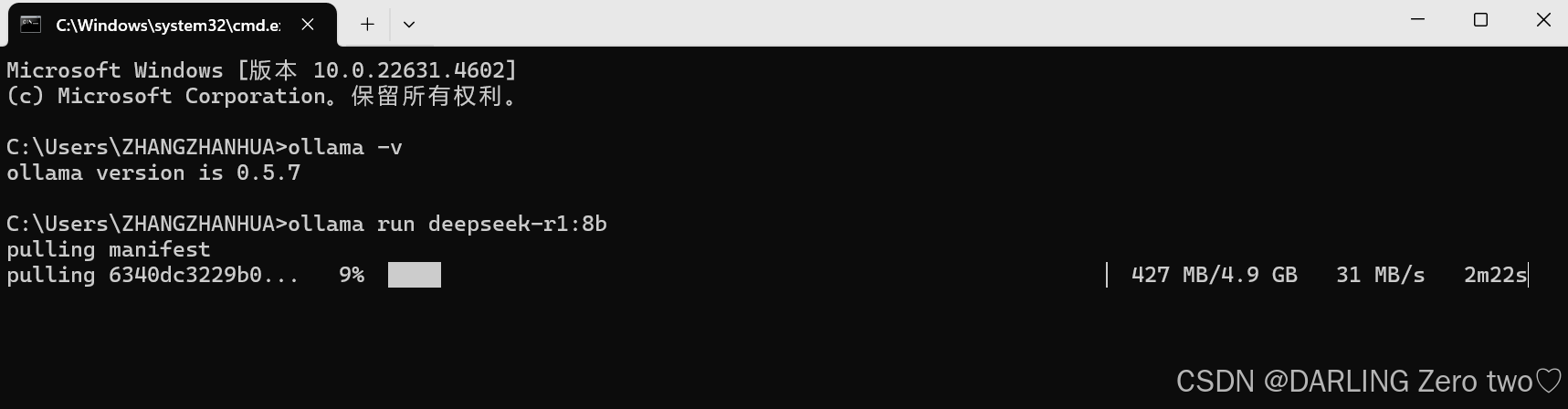
回到命令行,输入刚才复制的命令,回车,等待下载
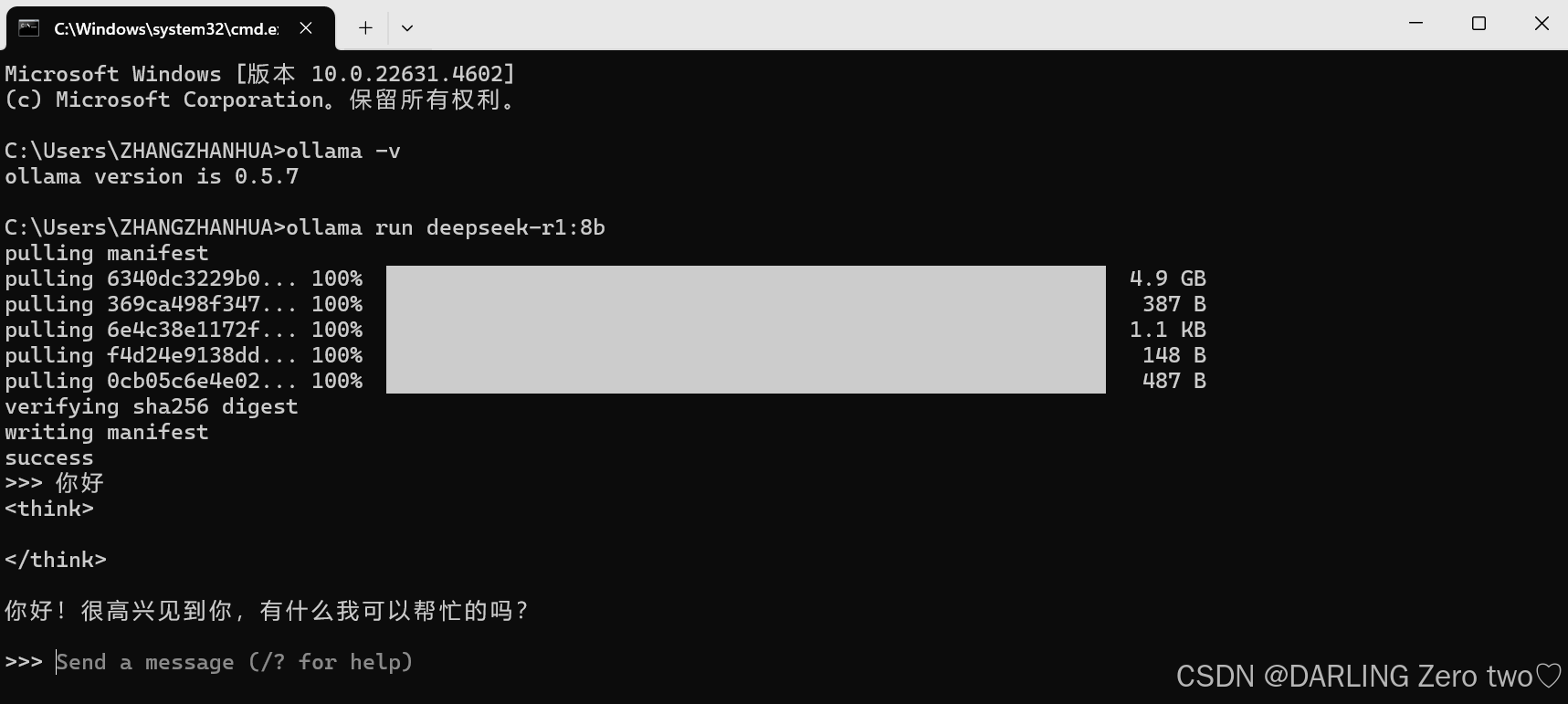
下载完成后就可以和Deepseek进行交流了,输入/bye来退出对话,但是每次调用窗口对话实在是太麻烦了
4.Chatbox AI下载
我们需要借助另一个软件来实现像手机端那样的界面使用
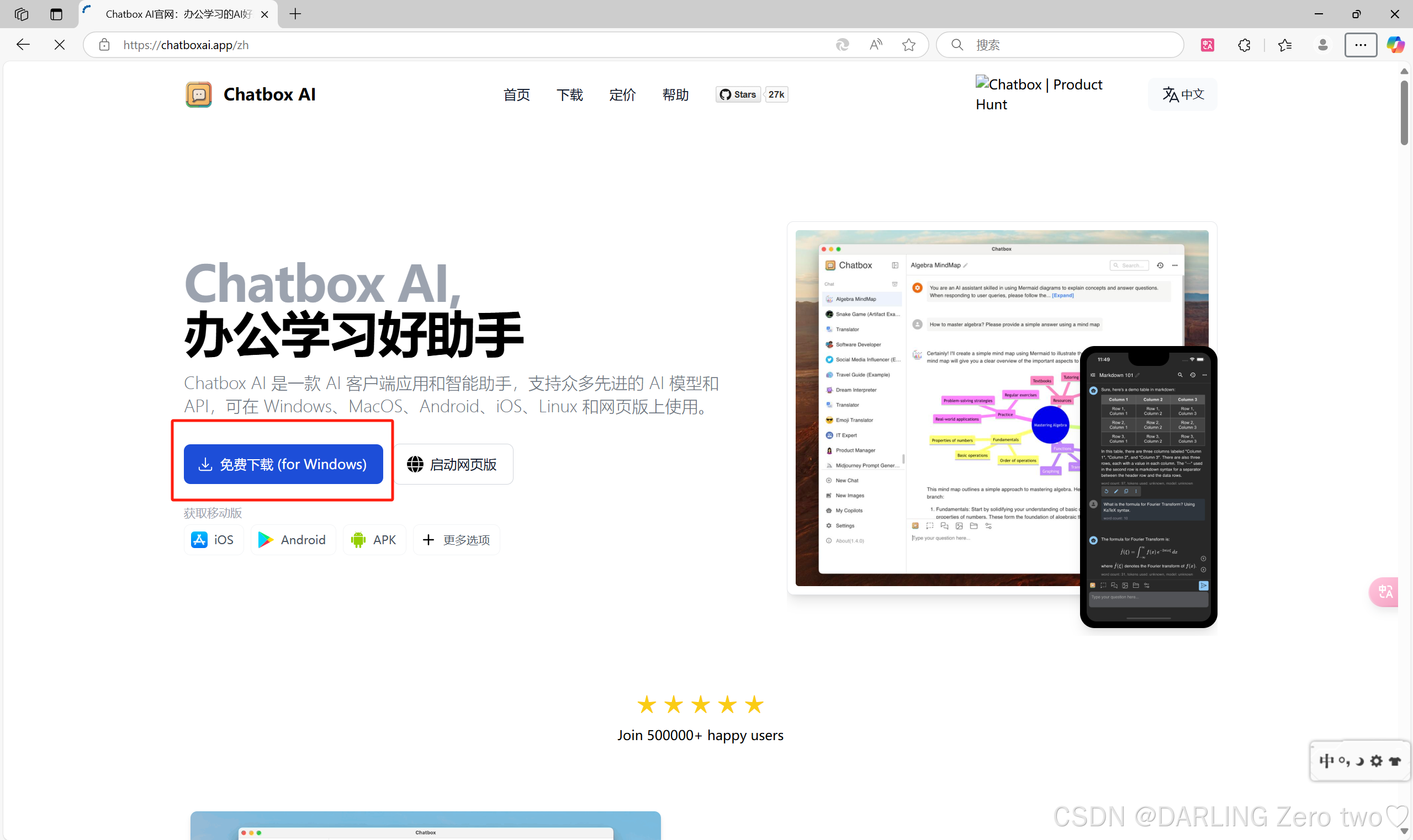
输入网址chatboxai.app下载该软件,建议用谷歌浏览器,我用微软浏览器有点卡(或者直接用网页版也行)
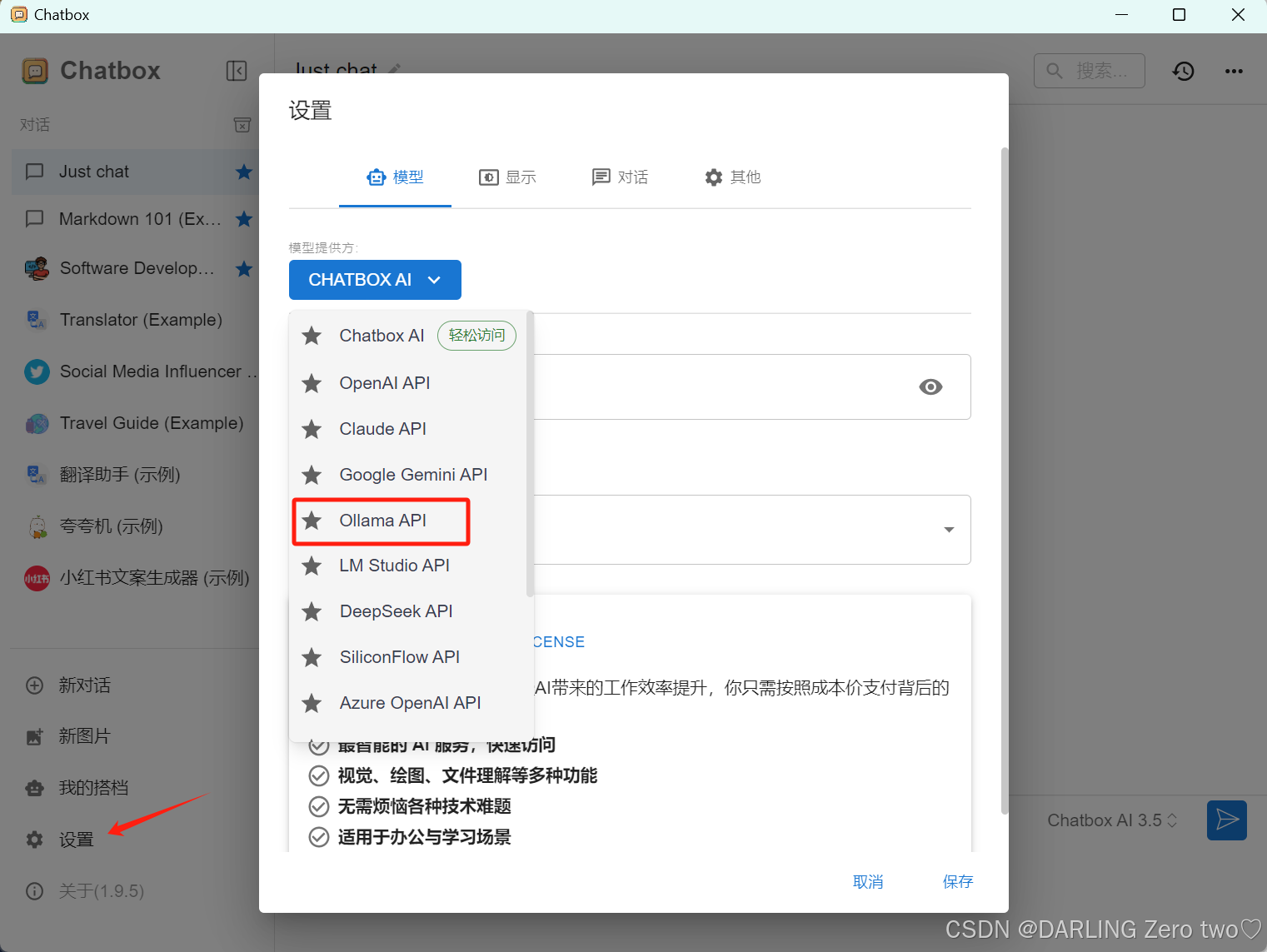
下载完之后,打开软件里的设置,选择模型提供方里的Ollama API
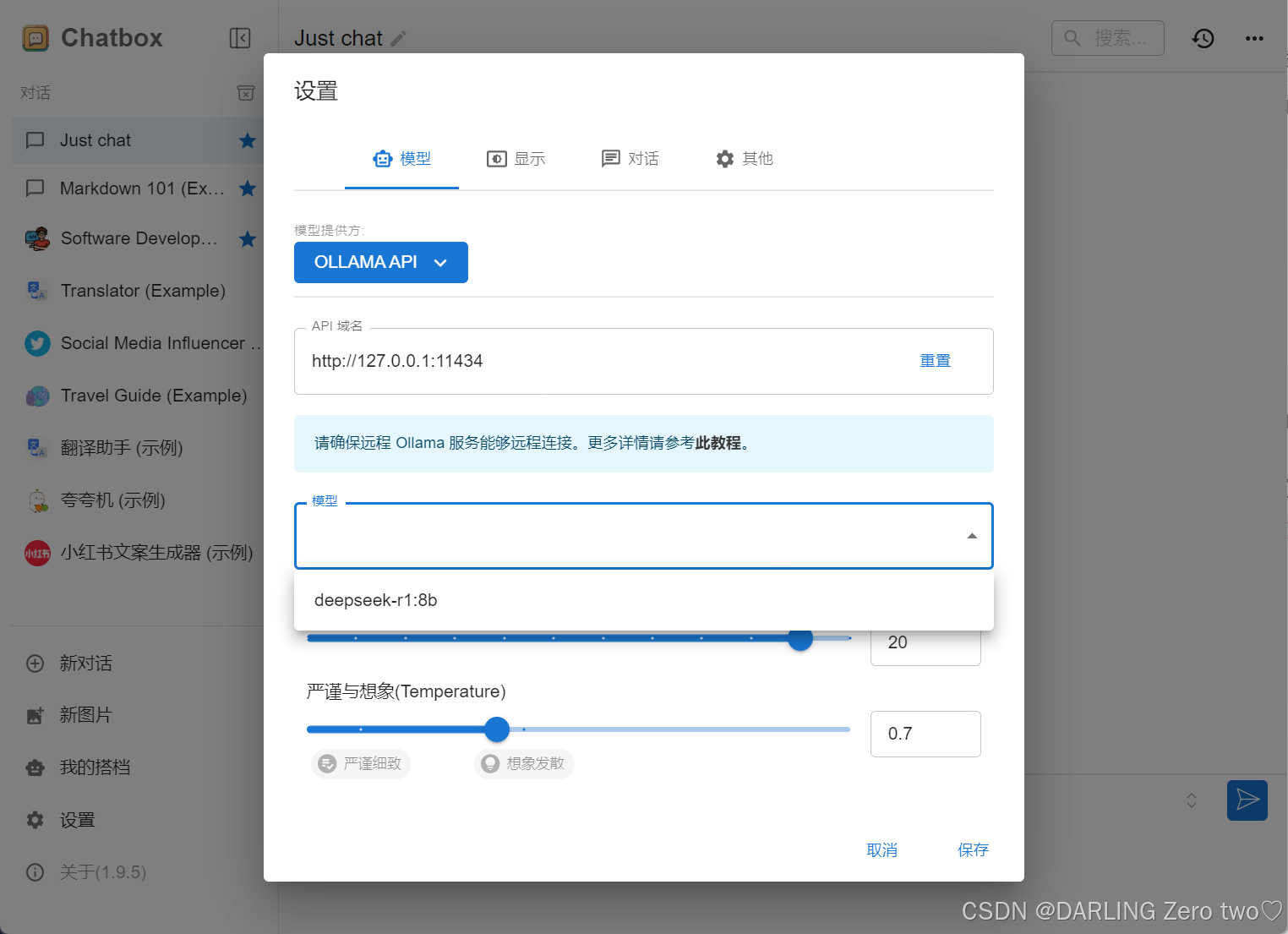
勾选你刚才在本地下载的模型

然后win+x,点击这里的系统
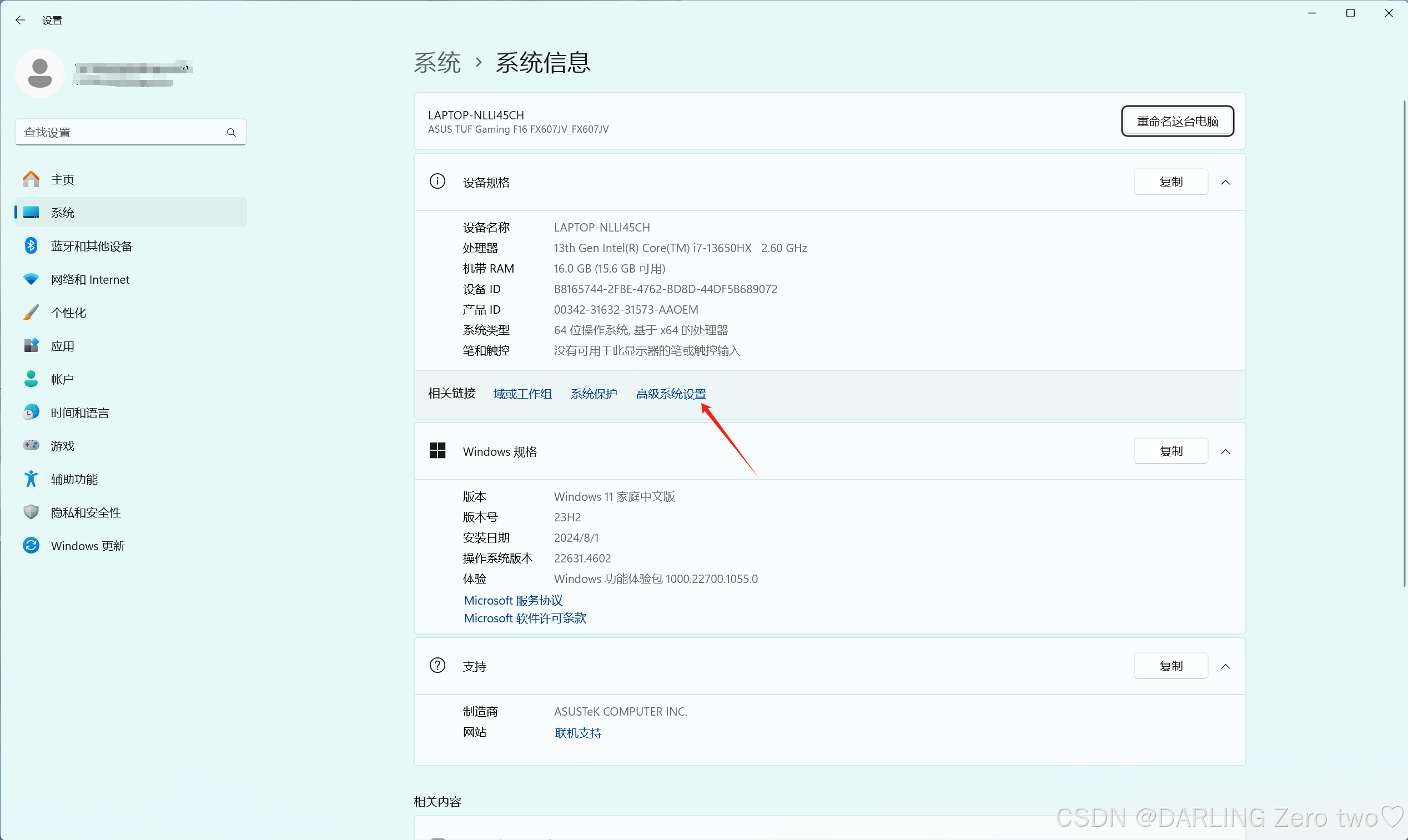
这里有个高级系统设置,点进去

点击这里的环境变量

然后新建变量,变量名输入OLLAMA_HOST,变量值输入0.0.0.0,千万不能出错
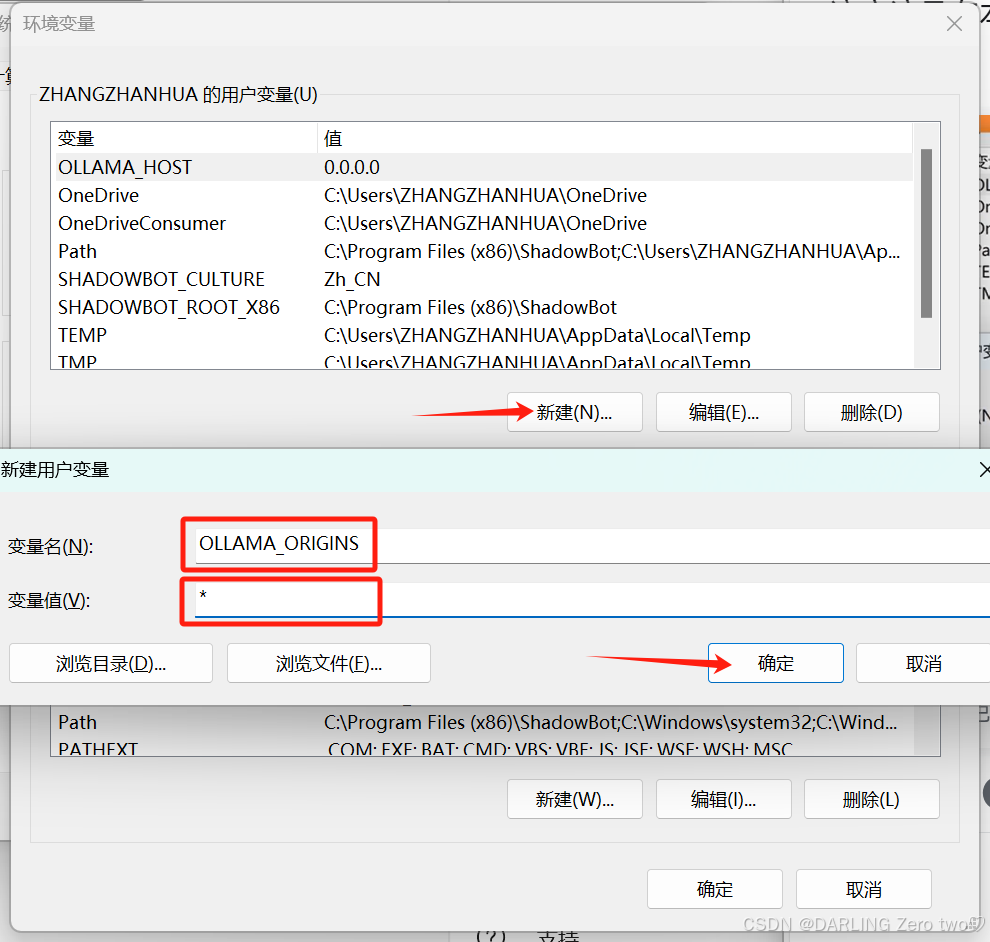
再新建一个新建变量,变量名输入OLLAMA_ORIGINS,变量值输入*

点击确定退出

再点击确定退出

然后在windows搜索栏里启动Ollama,要确保已经启动了,不然模型无法运行
然后就可以回到Chatbox就可以使用Deepseek了



















 2899
2899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









