




目录
前言
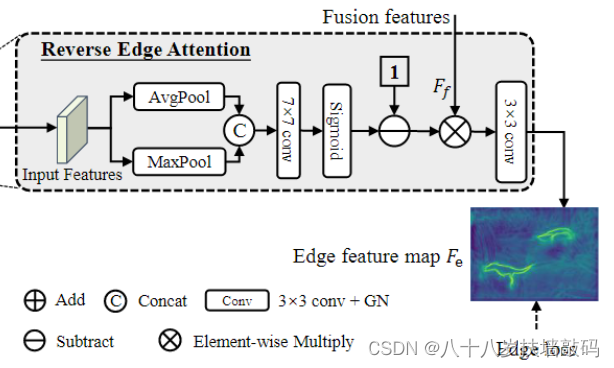
OSFormer模型中提到了反向边缘注意(Reverse Edge Attention)模块,通过十分简单的操作,就可以预测出伪装目标的边缘特征。作者也将OSFormer模型强大的细长边缘特征分割能力归功于反向边缘注意。那么,什么是反向注意(reverse attention)?反向注意有什么作用?为什么反向边缘注意可以预测出边缘特征?

1. Reverse Attention的提出
溯源Reverse Attention,发现Reverse Attention最早是2017年由来自美国南加州大学的团队提出的(Semantic Segmentation with Reverse Attention)。
这篇文章的主要目的是为了提高语义分割网络对于confusion area的预测能力。所谓的confusion area,是指网络对某些类别的预测概率都差不多大的区域。
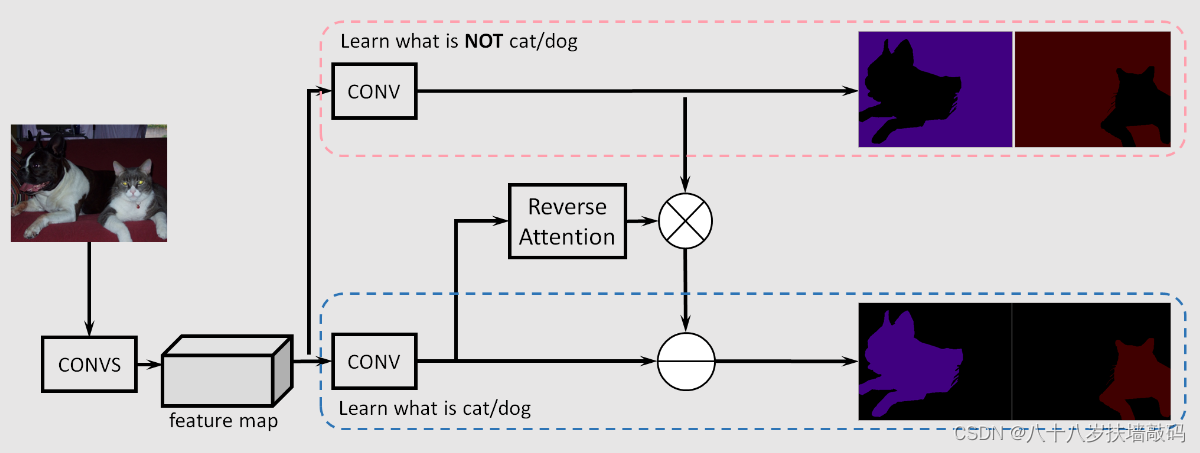
下面这张图表示FCN网络提取特征和预测的过程。右下角表示最终预测的结果,圆形区域内部就是猫和狗重合部分的区域,也就是confusion area。

作者的观点是,FCN只是预测某个pixel属于各个类别的概率,而对于那些confusion area,如果能训练一个网络来预测得到这个区域不属于猫的概率比不属于狗的概率更大,那么结合原始FCN的预测,就可以得到这个区域应该预测成狗。所以构建了一个reverse learning process反向学习过程,来预测pixel不属于各个类别的概率。也就是Reverse Attention Network(RAN)。

整体框架如上面两张图所示,主要分成三个分支。
- 第一个分支,也就是original branch,使用原始的FCN网络学习pixel属于各个类别的概率分布;
- 第二个分支,也就是reverse branch,学习pixel不属于各个类别的概率分布;
- 第三个分支,也就是reverse attention branch,学习第一、二个分支的预测图之间结合的权重。
最终用来预测的是经过attention branch输出的混合预测(combined pred)。
为什么需要第三个分支,也就是reverse attention branch:
最直接的想法是将original prediction和reverse prediction的结果直接相减,但是问题在于reverse learning的效果可能没有original learning的好。我们期望的是在original learning结果的confusion area上引入reverse learning的预测结果,因此需要引入一个attention机制,将reverse learning的结果引入confusion的区域。
数学表示:
I r a ( i , j ) = S i g m o i d ( − F C O N V o r g ( i , j ) ) I_{ra}(i,j)=Sigmoid(-F_{CONV_{org}}(i,j)) Ira(i,j)=Sigmoid(−FCONVorg(i,j))
( i , j ) (i,j) (i,j)表示像素位置坐标, F C O N V o r g F_{CONV_{org}} F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









