




 本文解析了OSFormer中ReverseAttention和边缘注意力模块(REA)的代码实现,包括特征融合、边缘预测和DiceLoss计算。重点讨论了特征图上采样、边缘标签生成和与其他模块的交互。
本文解析了OSFormer中ReverseAttention和边缘注意力模块(REA)的代码实现,包括特征融合、边缘预测和DiceLoss计算。重点讨论了特征图上采样、边缘标签生成和与其他模块的交互。
前言
通过溯源Reverse Attention的论文,对反向注意力机制有了初步的了解。但是,仅仅通过论文很多细节的东西是没办法看到的,还是有很多疑问,这就需要阅读代码去理解。
- 输入REA模块的不同层级的特征图(T4、T3、C2)是否和之前的Reverse Attention一样经过了上采样?
- REA模块的输出边缘特征图 F e F_e Fe最终输出到了哪里?是否和之前的Reverse Attention一样与不同层级的REA输出相加到了一起?
- 通过侵蚀实例掩码标签来获得边缘标签是怎么实现的?
- Edge loss是怎么进行计算的?原论文中3.5节提到, L e d g e = ∑ j = 1 J L d i c e ( j ) L_{edge}=\sum_{j=1}^{J}L_{dice}^{(j)} Ledge=∑j=1JLdice(j)。那么, L d i c e L_{dice} Ldice又是什么?是V-Net论文中提到的Dice loss吗?那Dice loss有什么特别之处呢?这与之前的Reverse Attention所用的损失函数有什么区别?
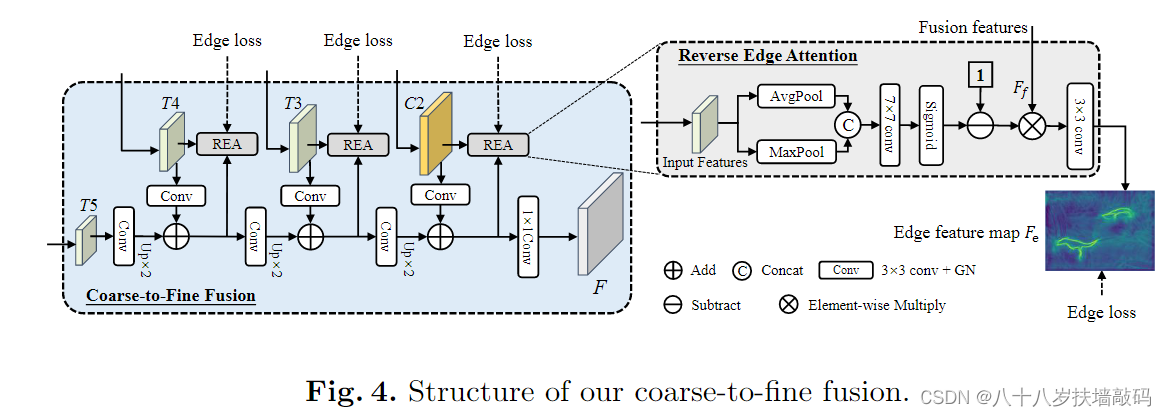
OSFormer模型的搭建代码一共由4个类组成:OSFormer()、CISTransformerHead()、C2FMaskHead()、ReverseEdgeSupervision()。其中,涉及到反向边缘注意力的主要是C2FMaskHead()和ReverseEdgeSupervision()。
1. REA模块的代码实现
class ReverseEdgeSupervision(nn.Module):
def __init__(self, chn):
super().__init__()
self.edge_pred = nn.Conv2d(
chn, 1,
kernel_size=3, stride=1,
padding=1, bias=False)
self.conv1 = nn.Conv2d(2, 1, kernel_size=7, padding=3, bias=False)
def forward(self, feat_fuse, feat_high):
avg_high = torch.mean(feat_high, dim=1, keepdim=True)
max_high, _ = torch.max(feat_high, dim=1, keepdim=True)
x = torch.cat([avg_high, max_high], dim=1)
x = 1 - self.conv1(x).sigmoid()
fuse = feat_fuse * x
return self.edge_pred(fuse)
通过forward()前向传播函数可以看到,参数feat_high代表输入的特征图Input Features。对于feat_high先按照行求平均值,返回形状(行数,1);再对feat_high按照行求最大值,返回形状(行数,1)。将二者通过torch.cat()函数按行拼接,得到形状(行数,2)的tensor向量。然后使用(输入通道数=2,输出通道数=1,卷积核大小= 7 × 7 7 \times 7 7
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









