 NumPy深度解析:创建、操作与广播的N维数组指南
NumPy深度解析:创建、操作与广播的N维数组指南





 本文详细介绍了如何使用NumPy创建、操作Ndarray对象,涉及数据类型、数组属性、从不同源创建数组、切片与索引、广播机制以及迭代数组。重点讲解了广播规则和高级索引技巧,适合初学者和进阶者深入理解NumPy数组操作。
本文详细介绍了如何使用NumPy创建、操作Ndarray对象,涉及数据类型、数组属性、从不同源创建数组、切片与索引、广播机制以及迭代数组。重点讲解了广播规则和高级索引技巧,适合初学者和进阶者深入理解NumPy数组操作。
目录
一、NumPy Ndarray 对象
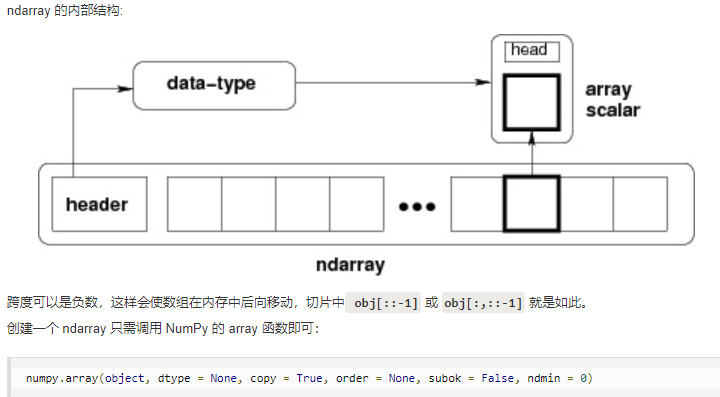
NumPy 最重要的一个特点是其 N 维数组对象 ndarray。ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
-
一个指向数据(内存或内存映射文件中的一块数据)的指针。
-
数据类型或 dtype,描述在数组中的固定大小值的格子。
-
一个表示数组形状(shape)的元组,表示各维度大小的元组。
-
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
二、NumPy 数据类型
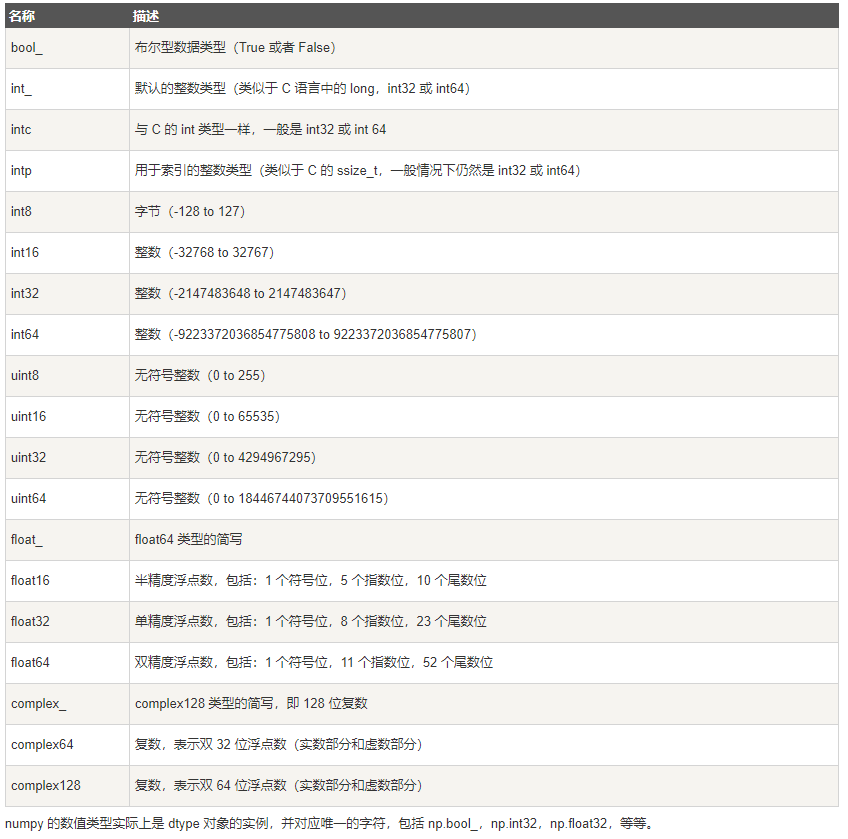
三、Numpy数据类型对象 (dtype)
数据类型对象(numpy.dtype 类的实例)用来描述与数组对应的内存区域是如何使用,它描述了数据的以下几个方面::
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,那么它的形状和数据类型是什么。
numpy.dtype(object, align, copy)
#object - 要转换为的数据类型对象
#align - 如果为 true,填充字段使其类似 C 的结构体。
#copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用四、NumPy 数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
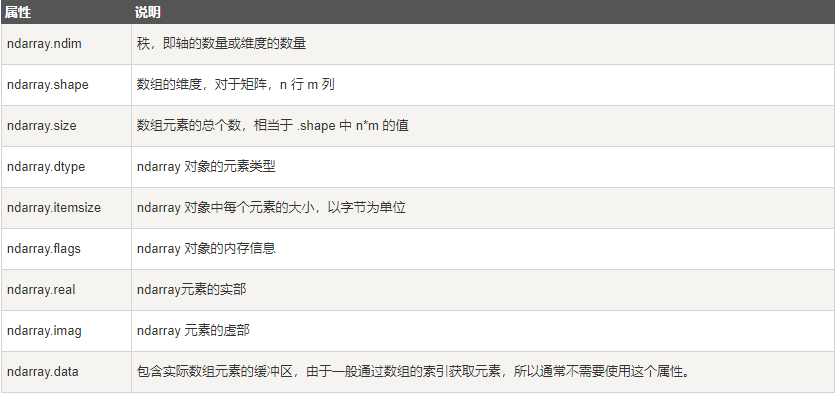

五、NumPy 创建数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
- numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组;
- numpy.zeros方法创建指定大小的数组,数组元素以 0 来填充;
- numpy.ones方法创建指定形状的数组,数组元素以 1 来填充;
import numpy as np
# 默认为浮点数
x = np.ones(5)
print(x)
x = np.ones([2,2], dtype = int)
print(x)六、NumPy 从已有的数组创建数组
- numpy.asarray 类似 numpy.array,直接创建数组,但所需参数只有三个;
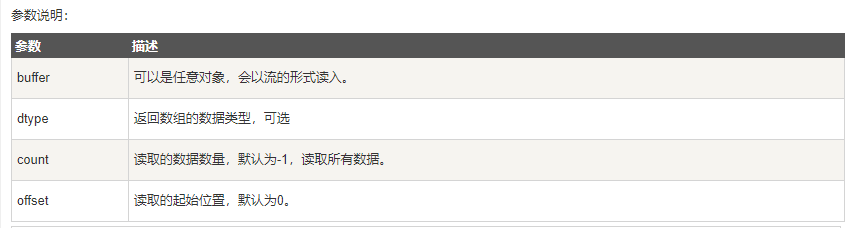
- numpy.frombuffer 用于实现动态数组。numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。(注意:buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b);
-
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
#frombufferer举例
import numpy as np
s = b'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print (a)
#fromiter举例
list=range(5)
it=iter(list)
x=np.fromiter(it, dtype=float)
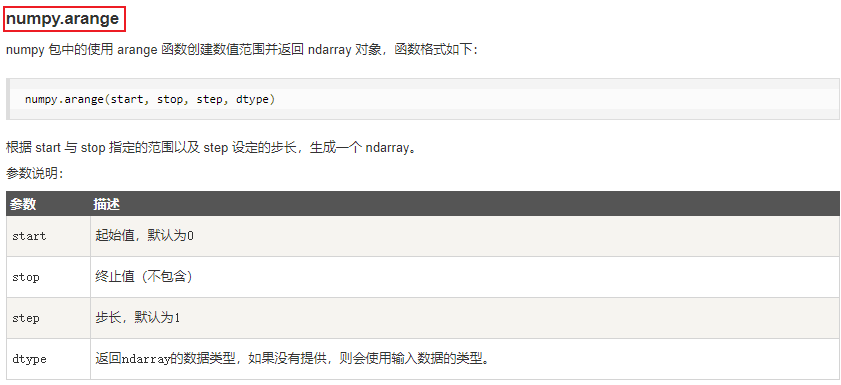
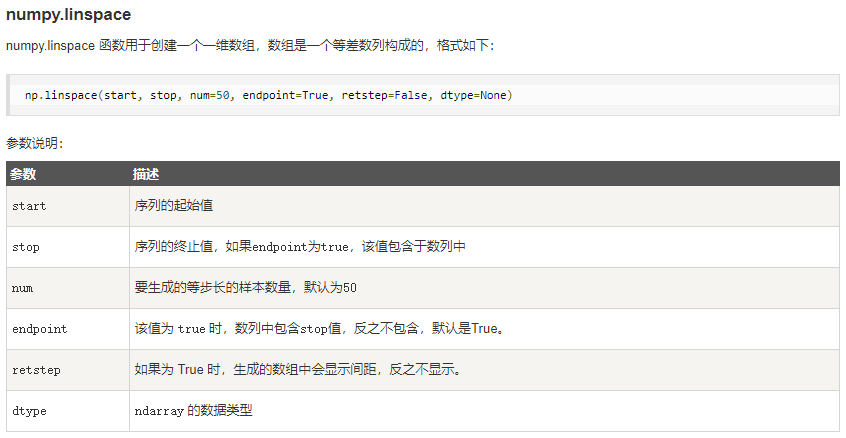
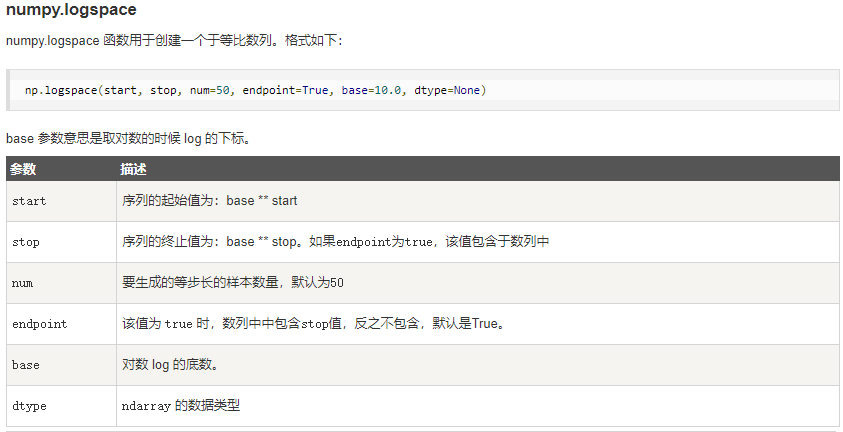
print(x)七、NumPy 从数值范围创建数组
八、NumPy 切片和索引
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # slice函数:从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
#[]如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。
#如果为 [2:],表示从该索引开始以后的所有项都将被提取。
#如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
a = np.arange(10)
b = a[2:7:2] #冒号分割:从索引 2 开始到索引 7 停止,间隔为 2
print(b)
#切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。
#如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print (a[...,1]) # 第2列元素
print (a[1,...]) # 第2行元素
print (a[...,1:]) # 第2列及剩下的所有元素九、NumPy 高级索引
1.整数数组索引;
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print (y)
# 输出结果为:[1 4 5]
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:' )
print (x)
print ('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print ('这个数组的四个角元素是:')
print (y)
'''输出结果为:我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
这个数组的四个角元素是:
[[ 0 2]
[ 9 11]]'''2.布尔索引;
我们可以通过一个布尔数组来索引目标数组。布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:')
print (x)
print ('\n')
# 现在我们会打印出大于 5 的元素
print ('大于 5 的元素是:')
print (x[x > 5])
'''输出结果是:我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]'''3.花式索引;
花式索引指的是利用整数数组进行索引。花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。花式索引跟切片不一样,它总是将数据复制到新数组中。
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[[-4,-2,-1,-7]])
'''输出结果是:[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4 5 6 7]]'''
十、NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。
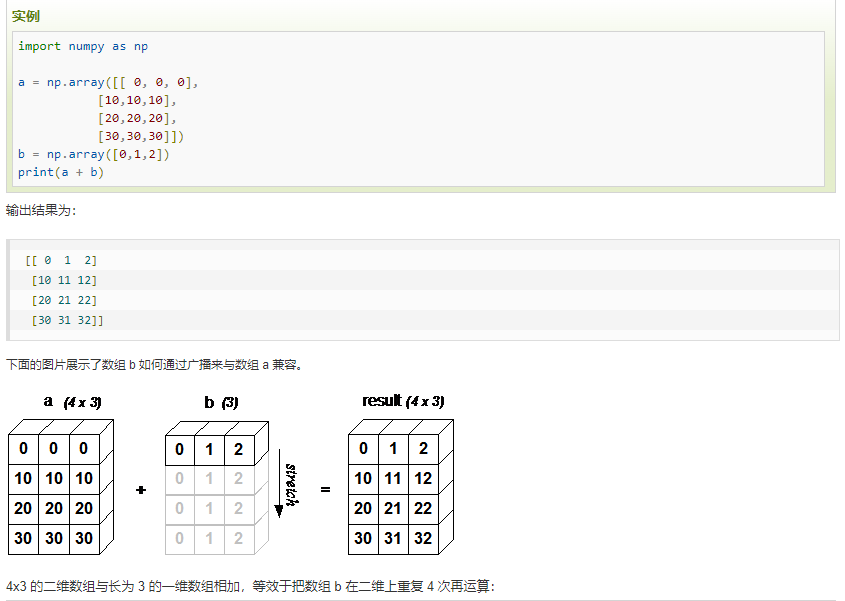
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
- 数组拥有相同形状。
- 当前维度的值相等。
- 当前维度的值有一个是 1。
若条件不满足,抛出 "ValueError: frames are not aligned" 异常。
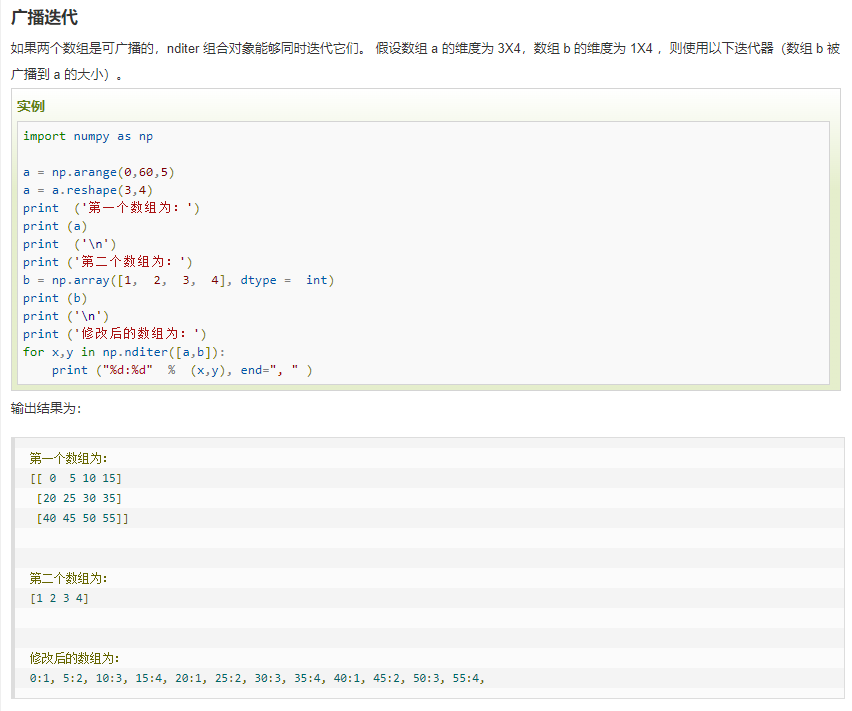
十一、NumPy 迭代数组
NumPy 迭代器对象 numpy.nditer 提供了一种一个或者多个数组元素的方式,迭代器最基本的任务是可以完成对数组元素的访问。
import numpy as np
a = np.arange(6).reshape(2,3)
print ('原始数组是:')
print (a)
print ('\n')
print ('迭代输出元素:')
for x in np.nditer(a):
print (x, end=", " )
print ('\n')控制遍历顺序:
for x in np.nditer(a, order='F'):Fortran order,即是列序优先;for x in np.nditer(a.T, order='C'):C order,即是行序优先;
修改数组中元素的值
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 readwrite 或者 writeonly 的模式。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
for x in np.nditer(a, op_flags=['readwrite']):
x[...]=2*x
print ('修改后的数组是:')
print (a)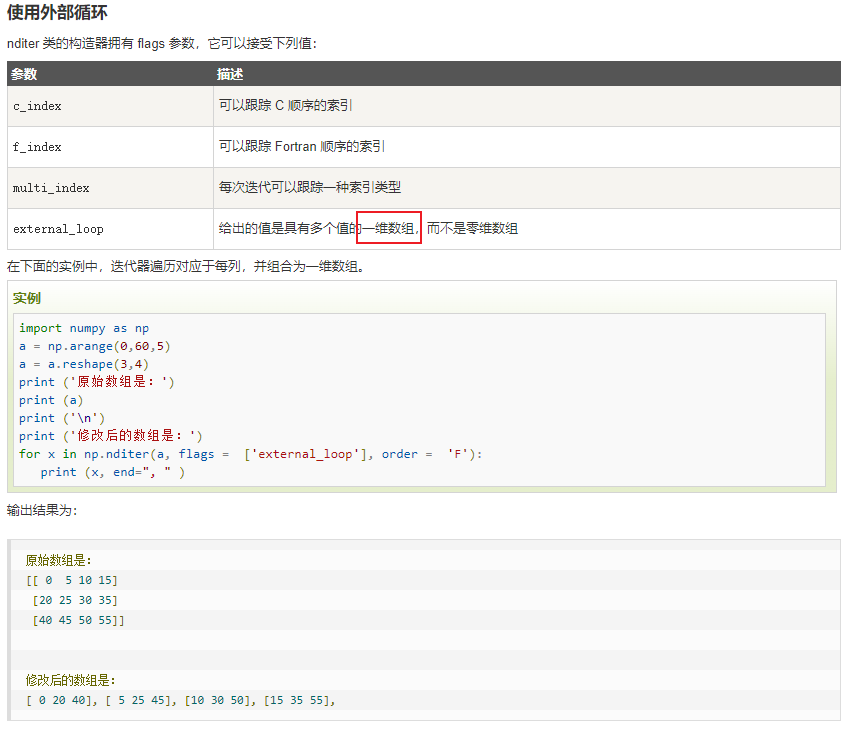

















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









