




在 AIoT、工业互联网场景中,类似"设备元数据(关系数据)+ 传感器数据(时序数据)"这样的联合查询是业务的重要需求之一。然而,在传统多库架构下,这类跨模查询往往意味着 “数据迁移 + 小时级等待”。KaiwuDB 创新自研的跨模优化技术,可将原本可能需要 5 小时的查询任务压缩至 64 秒,场景性能甚至能实现百倍的飞跃。今天就带大家一同探秘,深度拆解 KaiwuDB 跨模查询性能飞跃的核心技术。
先看结果------跨模查询的性能起飞
我们以能源管道网络物联网场景为测试基准,针对 3 个典型应用跨模优化的查询场景开展对比测试,具体结果如下:
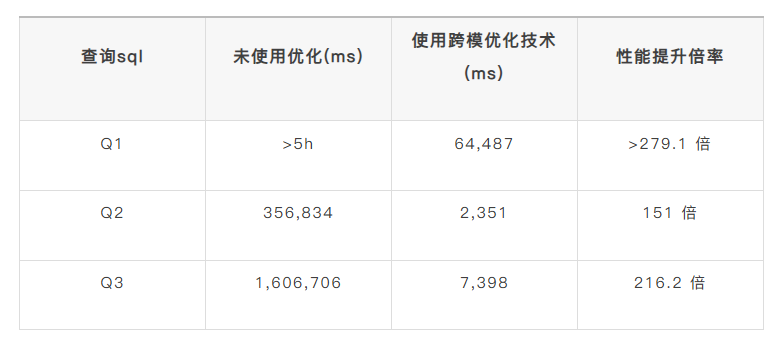
测试场景基础信息
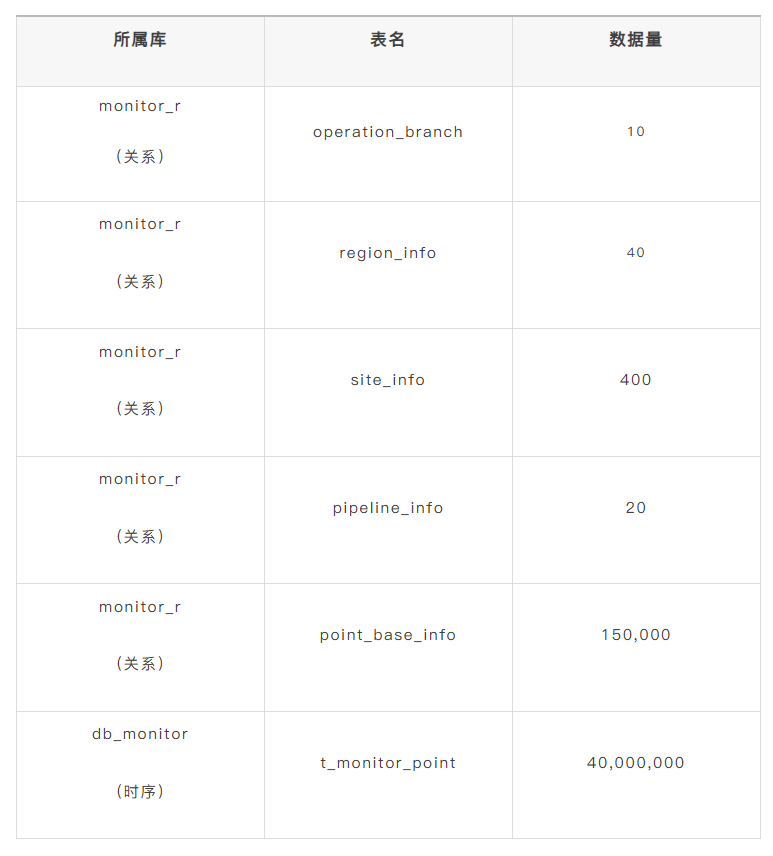
本次测试涉及的数据源包括关系型数据库和时序数据库,具体表结构与数据量如下:
测试查询场景 SQL 语句
Q2:
SELECT si.workarea_name,
si.site_name,
t.measure_type,
time_bucket(t.k_collect_time, '10s') as timebucket,
AVG(t.monitor_value) AS avg_value,
MAX(t.monitor_value) AS max_value,
MIN(t.monitor_value) AS min_value,
COUNT(t.monitor_value) AS number_of_values
FROM monitor_r.site_info si,
monitor_r.region_info wi,
monitor_r.pipeline_info li,
monitor_r.point_base_info pi,
db_monitor.t_monitor_point t
WHERE li.pipeline_id = pi.pipeline_id
AND pi.site_id = si.site_id
AND si.region_id = wi.region_id
AND t.point_id = pi.point_id
AND li.pipeline_name = 'pipeline_1'
AND wi.region_name in ('work_area_1', 'work_area_2', 'work_area_3')
AND t.k_collect_time >= '2023-08-01 01:00:00'
GROUP BY si.workarea_name,
si.site_name,
t.measure_type,
timebucket;
Q3:
SELECT si.site_name,
COUNT(DISTINCT point_id) AS abnormal_point_count
FROM
db_monitor.t_monitor_point t,
monitor_r.pipeline_info li,
monitor_r.site_info si
WHERE li.pipeline_id = t.pipeline_id
AND t.site_id = si.site_id
AND li.pipeline_name = 'pipeline_1'
AND t.monitor_type = 4
AND t.k_collect_time >= '2023-08-01 00:00:00'
AND t.k_collect_time <= '2024-08-01 01:00:00'
AND t.monitor_value < 0.5 * (
SELECT AVG(t1.monitor_value)
FROM db_monitor.t_monitor_point t1
WHERE t1.pipeline_id = li.pipeline_id
AND t1.monitor_type = 4)
GROUP BY
si.site_name
ORDER BY
abnormal_point_count DESC;
Q8:
SELECT ci1.sub_company_name,
wi1.region_name,
si1.site_name,
t1.measure_type,
time_bucket(t1.k_collect_time, '10s') as timebucket,
AVG(t1.monitor_value) AS avg_value,
MAX(t1.monitor_value) AS max_value,
MIN(t1.monitor_value) AS min_value,
COUNT(t1.monitor_value) AS number_of_values
FROM monitor_r.site_info si1,
monitor_r.site_info si2,
monitor_r.region_info wi1,
monitor_r.region_info wi2,
monitor_r.company_info ci1,
monitor_r.company_info ci2,
monitor_r.pipeline_info li1,
monitor_r.pipeline_info li2,
monitor_r.point_base_info pi1,
monitor_r.point_base_info pi2,
db_monitor.t_monitor_point t1,
db_monitor.t_monitor_point t2
WHERE li1.pipeline_id = pi1.pipeline_id
AND pi1.site_id = si1.site_id
AND si1.branch_id = ci1.branch_id
AND si1.region_id = wi1.region_id
AND t1.point_id = pi1.point_id
AND li1.pipeline_name = 'pipeline_1'
AND wi1.region_name in ('work_area_1', 'work_area_2', 'work_area_3')
AND ci1.sub_company_name = 'sub_com_1'
AND li2.pipeline_id = pi2.pipeline_id
AND pi2.site_id = si2.site_id
AND si2.branch_id = ci2.branch_id
AND si2.region_id = wi2.region_id
AND t2.point_id = pi2.point_id
AND li1.pipe_start_point = li2.pipe_start_point
AND pi1.signal_type = pi2.signal_type
AND pi1.signal_id = pi2.signal_id
AND li2.pipeline_name = 'pipeline_4'
AND wi2.region_name in ('work_area_7', 'work_area_8', 'work_area_9')
AND ci2.sub_company_name = 'sub_com_2'
AND t1.k_collect_time >= '2023-08-01 01:00:00'
AND t1.k_collect_time = t2.k_collect_time
AND t1.monitor_type = t2.monitor_type
AND t1.monitor_value > t2.monitor_value
GROUP BY ci1.sub_company_name,
wi1.region_name,
si1.site_name,
t1.measure_type,
timebucket;
“原生多模” 的独有优势
百倍级别的性能提升,绝非 “简单调优” 能实现 。其背后的密码是------KaiwuDB 通过跨模统计信息融合、跨模聚合下推、高速跨模连接算子这三项优化技术,把 “关系数据 + 时序数据” 的联合查询时间极致缩短。
目前一些支持 “多模” 的数据库选择的方案,是在关系库上套一个时序插件。这类方案的跨模查询,本质还是 “在关系库中模拟时序计算”,因此性能依然受限。而 KaiwuDB 凭借"原生双引擎 + 算子下推"的跨模性能优势,从架构层面实现了 “多模数据的存储协同 + 计算协同”:
• 存储协同:时序/关系数据同节点、同实例存储;
• 计算协同:算子下推到对应引擎,避免跨库/跨节点的数据移动。
KaiwuDB 多模的基础框架
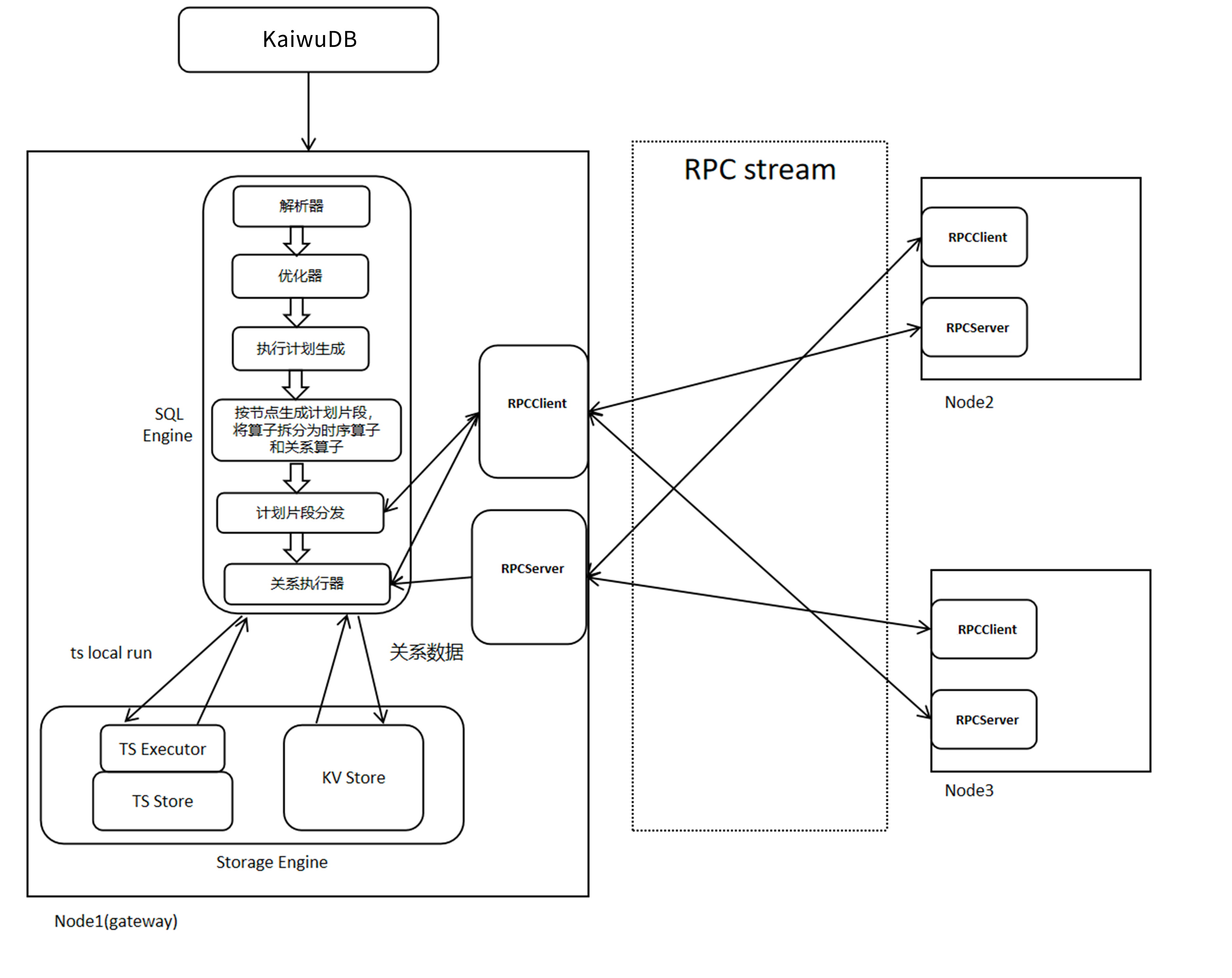
KaiwuDB 的多模框架是面向 AIoT 场景设计的 “统一 SQL 执行层 + 异构引擎融合 + 分布式协同” 架构,核心是在一个数据库实例内同时支持时序、关系等多类型数据的统一存储、计算与管理,避免"专库专用" 的复杂度。
📌 统一的 SQL 执行层
通过 KaiwuDB 客户端接收请求,对外提供标准 SQL 接口(兼容 PostgreSQL 语法),屏蔽多模数据的差异。
多模 SQL 处理:
• 解析器:将 SQL 解析为抽象语法树,识别数据类型(时序 / 关系);
• 优化器:根据数据类型选择引擎(时序引擎 / 关系引擎),并将算子拆分为 “时序算子 + 关系算子”;
• 执行计划生成与分片:按节点 / 数据类型生成分布式执行计划,通过 RPC 将子计划分发到对应节点。
📌 分布式协同层(RPC stream)
• 采用 RPC 作为统一通信协议,实现节点间(如 Node1 与 Node2/Node3)的执行计划分发、数据传输;
• 每个节点同时具备 RPCClient 和 RPCServer 能力,支持无中心对等通信,保证分布式场景下的多模计算协同。
📌 多模存储引擎层(Storage Engine)
在每个节点的 Storage Engine 中,集成两种核心引擎,实现多模数据的本地处理。
• TS Executor + TS Store(时序数据存储引擎):负责时序数据的存储与计算;对应架构图中的 “ts local run”,处理本地时序数据的写入/查询。
• KV Store(关系数据存储引擎):基于 MVCC 实现关系型数据的事务处理,采用 B + 树索引保证低延迟点查;处理关系型数据的增删改查,与时序引擎共享存储资源。
两大关键多模能力
✅ 多模数据统一管理
• 统一存储:时序数据(如传感器数据)和关系数据(如设备元数据)存储在同一实例中,通过元数据服务区分数据类型;
• 跨模计算:支持时序数据与关系数据的联合查询。如:按设备 ID(关系数据)查询某时段的传感器数据(时序数据),无需数据迁移。
✅ 自适应引擎协同
• 引擎自动选择:SQL 优化器根据数据类型自动路由到对应引擎(时序数据→TS Store,关系数据→KV Store);
• 算子下推:将计算推近数据(即就地计算),如时序聚合算子直接下推到 TS Store 执行,避免全量数据传输;
• 跨节点协同:通过 RPC 将多模算子分发到不同节点的引擎中执行,再汇总结果返回客户端。
跨模查询优化技术
为了提升跨模查询的性能,KaiwuDB 提出并应用了三种跨模查询优化技术:
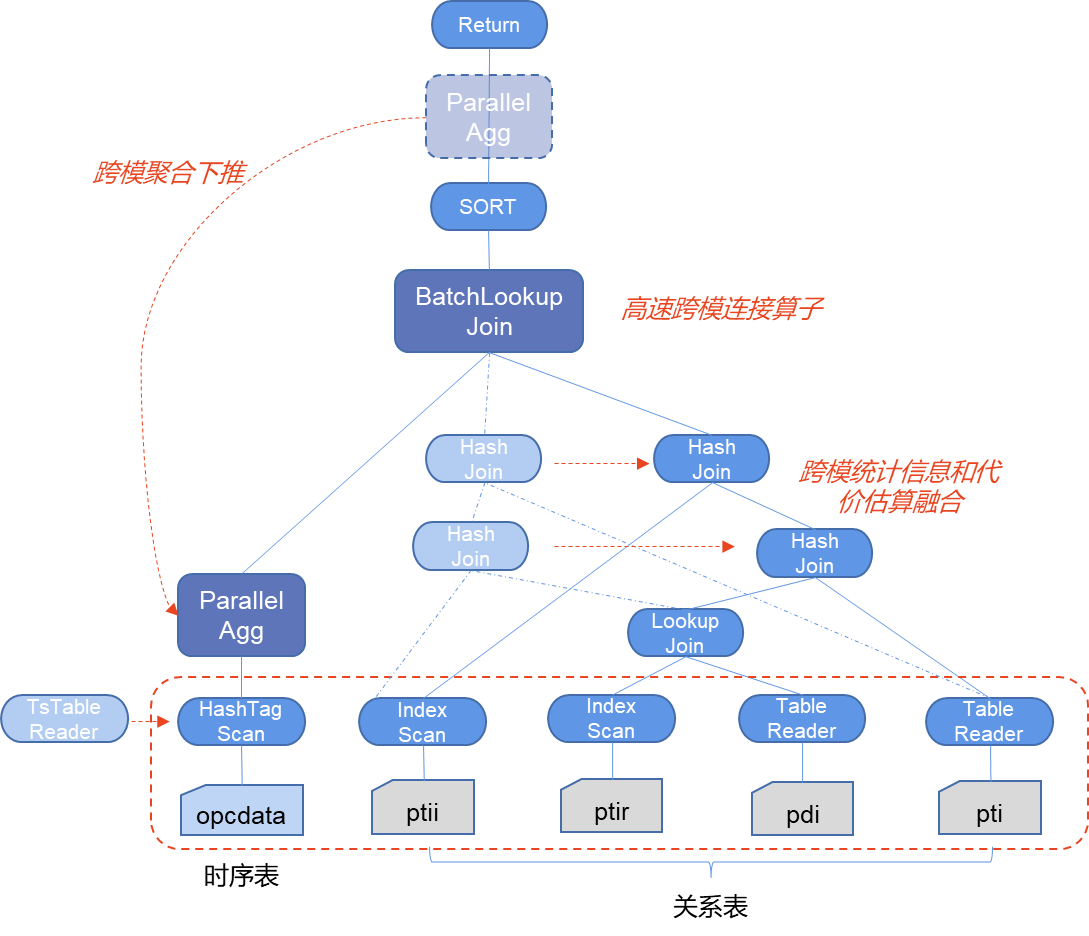
1、 跨模统计信息和代价估算融合:让优化器"读懂"时序数据
传统优化器对时序数据的认知存在盲区,既不了解其"按时间有序存储"的特性,也无法精准掌握数据分布情况,导致生成低效执行计划。KaiwuDB 通过给优化器补充时序专属统计信息,实现了代价估算的精准化。
🛠️ 技术原理
• 时序统计信息 “模式化”:给时序数据定义专属统计项(比如 “标签条数”、“某设备的聚合统计信息”、“某设备的时序数据条数”),并和关系数据的统计信息存在同一个元数据系统里;
• 定制化统计规则:针对时序数据 “写密集、按时间有序” 的特点,创新统计项(比如 “聚合值预计算结果”);
• 自适应采集策略:即可手动收集时序数据统计信息,也可定时收集时序数据统计信息,tag 表会全量统计,metric 表粗量统计(精确统计表行数、预估列不同值与 null 值),既保证精度又不占资源;
• 代价估算融合:优化器同时参考关系数据和时序数据的统计信息,根据代价估算选择最优的连接顺序以及自动选择 “算子下推/高速连接” 等最优策略。
🎯 实战效果(Q1 场景)
统计"pipeline_1"管道下,2023-2024 年间测量值低于同管道均值 50% 的异常监测点数量(按站点分组排序)
无优化流程
因为不知道某型号设备的时序数据占比,与时序表的连接顺序不是最佳的,会先全量扫描时序表,再和关系表的型号做连接,产生大量的中间数据,导致计算慢,耗时 > 5 小时;
使用优化流程
通过时序统计信息知道该型号设备的时序数据远多于关系表,会先让关系表进行连接后再与时序表进行连接,这样的话就减少了大量的中间结果,最终耗时 64 秒,性能提升 279.1 倍。
2、 跨模聚合下推技术:让计算"贴着"数据跑
跨模查询的核心痛点之一是数据在引擎间的无效传输,KaiwuDB 的解决方案是"将计算逻辑推至数据所在引擎,就地计算后再汇总",从源头减少数据移动。
🛠️ 技术原理
KaiwuDB 的 SQL 引擎会做 “自底向上的下推判断” 机制:
• 下推白名单:提前定义时序引擎支持的算子以及操作(比如 TS Store 支持时序聚合等)。
• 场景化下推优化:
① 时间条件下推到时序表的时间索引,避免全表扫描;
② 聚合计算下推到时序表扫描阶段,减少中间数据;
③ 排序/窗口/limit 等算子,结合时序数据的有序性,直接下推到引擎层消除冗余计算。
🎯 实战效果(Q2 场景)
“统计 2023-08-01 01:00 后,pipeline_1 管道下 work_area_1/work_area_2/work_area_3 作业区所有站点的时序数据:按作业区、站点、测量类型分组,以 10 秒为时间桶,计算每个时间桶内测量值的平均值、最大值、最小值及数据条数”
无优化流程
① 时序库全量扫描:从时序表 db_monitor.t_monitor_point 中读取 2023-08-01 01:00 后的所有数据(无前置过滤,仅按时间范围拉取);
② 全量数据传输:将海量原始时序数据从时序引擎传输到关系引擎(monitor_r 库),涉及大量网络 IO 和数据序列化/反序列化;
③ 关系引擎多表关联:在关系引擎中依次关联关系表 ,筛选出 pipeline_1 管道 + 指定作业区的数据;
④关系引擎计算聚合:按作业区、站点、测量类型、10 秒时间桶分组,逐一计算平均值、最大值、最小值、数据条数,无预聚合优化。
无优化流程最终耗时 356,834 ms。
使用优化流程
时序引擎前置过滤 + 预聚合:
① 将核心条件下推:把过滤条件"li.pipeline_name = ‘pipeline_1’ AND wi.region_name in (‘work_area_1’, ‘work_area_2’, ‘work_area_3’) AND t.k_collect_time >= ‘2023-08-01 01:00:00’" 下推到时序引擎,先筛选出仅符合条件的测点数据;
② 时序引擎就地聚合:利用时序表按 k_collect_time 有序存储的特性(时间索引),直接在时序引擎内按 10 秒时间桶、测点 sn 分组,提前计算每个时间桶的平均值、最大值、最小值、数据条数(避免原始数据传输)。
使用优化流程最终耗时 2,351 ms,性能提升 151 倍。
3、 高速跨模连接算子技术:用"数据裁剪"换"传输效率"
跨模连接的核心成本是 “数据在关系时序引擎间的传输量”------KaiwuDB 的高速连接算子,通过先计算数据量较少的关系数据,再将关系数据传输到数据量巨大的时序引擎中进行计算达到过滤数据量的目的,最终可以把需要传输的数据大量裁剪掉,以此提升效率。
🛠️ 技术原理
• 自适应连接模式:通过优化器根据融合的统计信息和代价估算,自动选择是否使用高速连接算子以及连接顺序;
• 先关系后时序:通常时序的数据是巨大的,先将关系数据在关系引擎进行计算,然后将结果数据传输到时序引擎中与时序数据进行连接再聚合;
• 设备级并发:按设备维度拆分计算任务,多设备的连接/聚合并行执行。
🎯 实战效果(Q3 场景)
在指定工作区、同一时间戳下的监测数据差异,按 10 秒窗口聚合统计
无优化流程
① 两台设备的全量时序数据(如 4500 万条)传到关系库;
② 与 10 张关系数据做 join 连接;
③ 最后再做聚合。
无优化流程最终耗时耗时 1,606,706 ms。
使用优化流程
① 先通过跨模统计信息和代价估算,选择最优的连接顺序,将两张时序表放到最后再与关系表,同时选择高速连接算子;
② 在关系引擎先将 10 张关系表的数据进行计算;
③ 少量的结果数据传输到时序引擎进行连接再聚合(并发计算),大大减少了时序引擎向关系引擎传输的数据量。
使用优化流程最终耗时 7,398 ms,性能提升 216.2 倍。
性能提升的本质 ------让数据"少奔波"
从统计信息融合让优化器"选对路",到聚合下推让计算"贴着数据跑",再到高速连接算子"削减传输量", KaiwuDB 三项跨模优化技术的核心逻辑始终一致------让计算尽可能靠近数据,将"跨库跨引擎的数据传输"转化为"引擎内的就地计算"。当数据不再需要跨引擎、跨节点"奔波",自然能够实现从"查得出"到"查得快"的飞跃。


















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









