




关于数据分发
数据分发,简而言之,就是将数据从源头高效、可靠地传输到一个或多个指定目的地的过程。其核心目的在于,确保需要数据的人或系统能够在正确的时间、以恰当的形式获取到准确的数据,实现数据的共享与同步。
为什么需要数据分发?
• 实时数据共享
集团各部门协同合作,需确保所有数据部门获取最新数据,避免因数据延迟导致的业务决策偏差,如供应链协同场景、IoT 设备运维、营销自动化等。
• 云边端数据协同
终端设备产生的海量原始数据按需(全量或者预处理)同步至云端分布式集群,进行全局数据的建模、预测、分析。
• 实时计算与告警
实时将变更数据主动推送出去,客户端根据业务需求自由订阅数据,进行数据的实时计算、展示与告警。
设计理念与架构
1、 核心设计理念
KaiwuDB 数据分发以**“数据价值最大化”**为核心设计原则,在源端与多目标端之间搭建高效、灵活、可靠的流转桥梁,以最小化传输带宽、时间成本实现最大传输效率,发挥最大数据价值。
• 实时数据驱动,赋能业务即时决策
以 “数据实时流转为业务价值服务” 为核心,确保数据从产生到分发的延迟控制在毫秒级。让业务能基于最新数据做即时决策,将数据的 “时间价值” 最大化。
• 业务场景导向,降低实时数据集成门槛
围绕 “让实时数据集成更简单” 的理念,设计了开箱即用的订阅发布能力:无需用户开发复杂的自定义同步逻辑,通过配置化的方式即可实现跨集群、跨系统的数据实时同步,同时兼容多种技术生态(时序引擎、消息队列、业务应用),让不同业务场景能快速复用该能力。
• 云边端一体化
以 "本地计算 + 按需同步"为核心,边缘侧过滤冗余数据、云端汇聚核心信息,适配工业物联网、车联网等分布式场景。
2、 数据分发流程
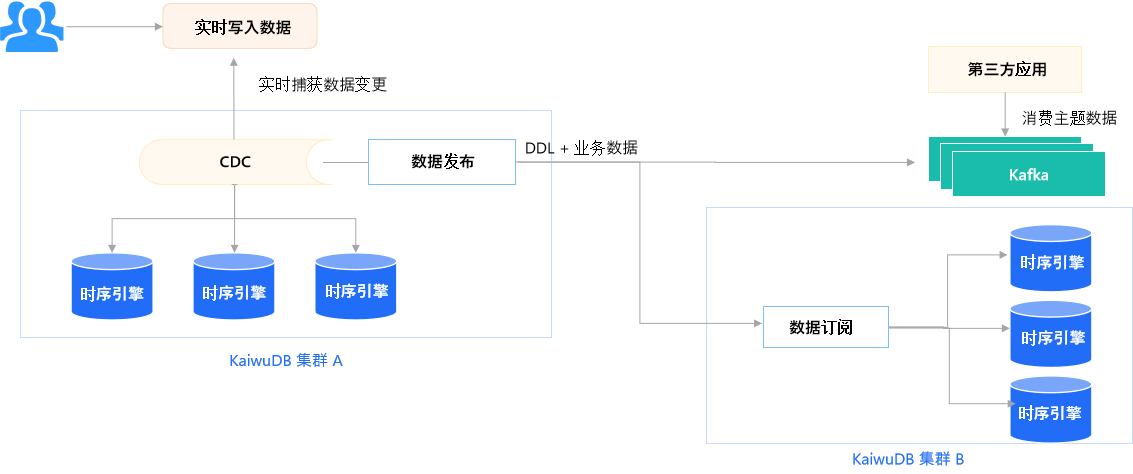
KaiwuDB 数据分发流程图
• 核心层
借助 CDC(Change Data Capture,变更数据捕获)技术,精准捕获数据变更,支持基于 SQL 的订阅规则定义(如 WHERE vibration > 阈值的异常数据过滤)。
• 传输层
支持 DDL(数据定义语言,用于数据库结构变更)和业务数据同步分发:
• 发送至 Kafka(分布式消息队列),供第三方应用消费主题数据,支持多端异步数据消费场景;
• 传递至 KaiwuDB 集群 B 的数据订阅模块,实现跨集群的数据同步。
核心功能特性
1、 多维度数据订阅
• 提供全量初始化 + 增量同步双模式;
• 支持基于 SQL 条件的行过滤和列级投影同步。
2、 高可靠传输机制
• 基于 Raft 协议的多副本机制,单点故障后仍可从其它正常节点继续同步;
• 边缘节点断网时本地缓存数据,恢复后自动续传,保障弱网场景可用性。
3、 断点续传
定期保存已处理日志的时间点,在故障恢复时从断点继续同步,避免数据重复或遗漏。
4、 元数据智能映射
自动识别源库表结构变更(如字段增删),同步更新目标端 Schema,保持上下游数据结构一致性。
5、 高效传输
通过实时捕获数据的增量变更,仅传输变化部分,提升数据同步效率。
应用场景与核心价值
1、 部分典型应用场景

2、 核心业务价值
• 提升实时决策
• 打破设备厂商数据壁垒,实现跨部门协同优化,实时数据共享打破信息孤岛,生产、运维、供应链等部门可基于同一数据源协同决策;
• 动态分析与预测,结合历史数据分析趋势并预测潜在问题,提前制定维护计划,减少非计划停机时间。
• 降低系统资源消耗
• 按需订阅关注数据信息,避免全量数据传输,减少 70%+ 云端传输量,带宽成本降低 30%~50%+;
• 边缘计算预处理,进行滤波、聚合或降采样处理,降低云端计算压力。
• 增强业务灵活性
• 支持灵活增减数据源或订阅主题,无需重构系统架构;
• 允许第三方开发者基于实时数据流开发增值应用,加速创新并丰富业务生态。
• 安全合规
支持数据脱敏订阅,符合 GDPR 数据最小化原则,保障车联网等场景的数据安全。


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









