




引言:当时间序列遇见关系模型
在工业物联网监控场景中,每分钟即可产生百万级的传感器时序数据,同时需要关联设备元数据表进行实时分析;在金融交易系统中,每秒数万笔交易流水需要与账户关系表进行 ACID 事务处理;在车联网平台系统中,特殊车辆的产生的大量定位信息,在查询中需要定位信息需要关联车辆的静态数据信息进行检索。
这种时序数据与关系数据的交织处理需求,正在催生新一代多模数据库的崛起。本文将深入探讨在这类特定场景下,多模数据库的核心技术究竟是如何实现的。
KWDB 多模融合架构设计
我们在数据库的核心模块改造了多模 SQL 解析器,多模 SQL 优化器,多模 SQL 执行器,并优化了自适应查询。
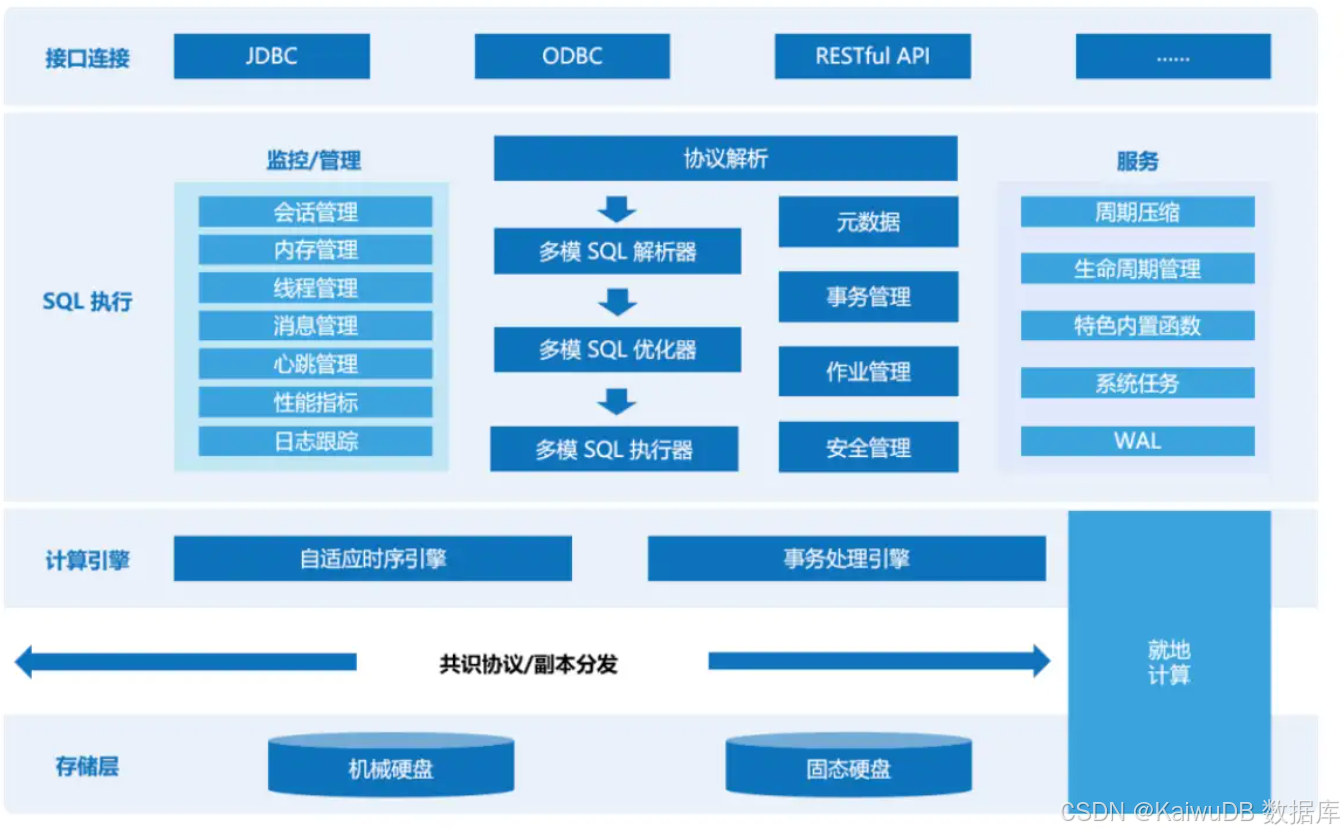
多模架构设计思路
以物联网场景为例,因设备产生的数据通常具有时间戳,如传感器读数、设备状态等,数据管理通常以时序数据为核心。然而,物联网系统不仅限于时序数据,还包括设备元数据、用户信息、日志记录等非时序数据。这些数据同样重要,广泛应用于设备管理、用户交互和系统维护。因此,在物联网业务场景下,市面上存在以下非多模方案:
• 关系数据存储在 MySQL 等的关系数据库中,时序数据存储在 InfluxDB 等时序数据库中,在进行关联查询时在数据中台将两部分数据汇总后进行关联查询,这种跨库的数据关联会产生极大的查询性能延迟。
• 时序数据库保存部分关系数据,使得关系数据和时序数据保存在一起,再采用优化手段,降低关系数据带来的冗余存储,这样虽然能提高部分关联查询的速度,但是由于关系数据和时序数据存储的特性,其无法支撑复杂的跨模关联的查询,也无法适应原有关系数据和新增时序数据的结合。
KWDB 的多模方案是将关系数据和时序数据统一管理,采用自适应数据存储和查询的方案。
根据不同模的数据的存储特性采用特定的存储方案,关系数据保存在关系存储引擎中,时序数据保存在时序存储引擎中,如此时序数据即可实现特定的存储优化,自带时间索引、设备索引等。
 多模数据管理
多模数据管理
用户进行查询时,根据查询的库表进行自适应的查询模式鉴别,通过统一的查询优化器,针对时序和关系的数据做特定的查询优化,生成统一的逻辑计划,最终根据查询的数据模不同定制不同的物理查询计划和物理计划优化。非跨模数据可以在就地计算完成后直接反馈给客户端,跨模关联计划则需要将多模的计算结果汇总后反馈给客户端。
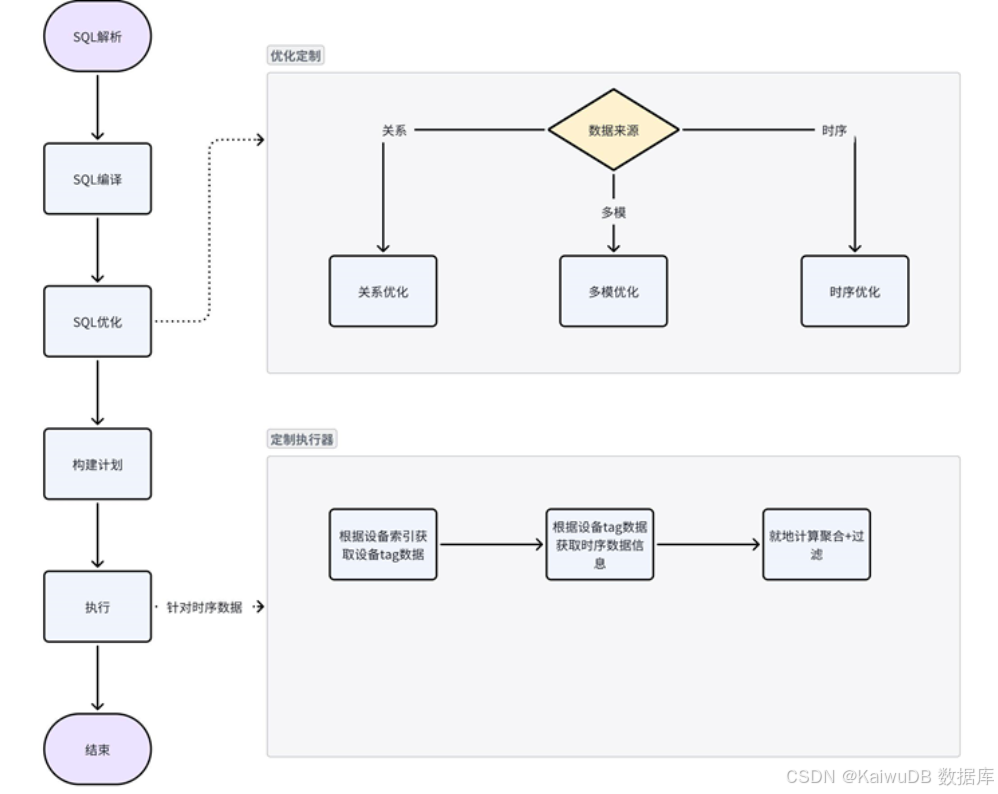
多模查询优化
技术要点
多模解析器
KWDB 数据库采用多模元数据统一管理模式,时序数据保存在 ts database 中,根据 database 的标记来区分时序和关系数据。针对时序数据的库标记来进行时序数据的管理,比如有些数据类型是时序数据不支持的(例如 decimal)。时序数据的查询函数限制等出现的位置有限定。例如:
sql-- 创建时序数据库db_pipecCREATE TS DATABASE db_pipec;-- TS table CREATE TABLE db_pipec.t_point ( k_timestamp timestamp NOT NULL, measure_value double ) ATTRIBUTES ( point_sn varchar(64) NOT NULL, sub_com_sn varchar(32), work_area_sn varchar(16), station_sn varchar(16), pipeline_sn varchar(16) not null, measure_type smallint, measure_location varchar(64)) PRIMARY TAGS (point_sn) ACTIVETIME 3h;
根据不同模的标记进行针对性的解析和编译,我们会根据时序数据的特性,针对性地增加和限制部分功能在时序数据的使用上,比如针对时序数据支持的特殊函数会在解析时进行判断,如果在关系数据中使用就会触发报错。
多模优化器
多模优化器会统一处理所有查询的优化,遇到针对时序的查询会充分利用时序数据的特点有针对性的优化。在优化之后还会针对时序数据不支持的算子和计算进行深度优化,将时序数据不支持的算子和计算放到关系执行器部分进行计算,时序计算完成后在关系执行器再次进行计算,保证查询的完整性。
• 跨模查询会根据时序和关系表的关联查询进行数据进行评估,根据代价评估来决定数据的流转方向,提高数据流转的效率。同时通过对时序数据计算进行优化以提高查询效率。
• 单独的时序数据查询会使用时序特有的优化技术,采用多种优化策略,如时序索引(primary tag 索引,时间范围索引等)、算子下推、统计信息应用、聚合下推等多种手段提高时序数据的查询效率。
多模执行器
时序执行器和关系执行器通过抽象成统一的执行接口进行管理,针对一套逻辑计划进行多模执行的封装。给时序数据的执行定制一套专用的执行器,根据时序数据的存储结构定制执行计划。时序数据通常会根据不同的设备、时间范围、设备信息进行检索,因此执行器充分利用 primary tag 索引、时间范围索引、tag 索引做定制化的执行。
例如首先会根据查询的 primary tag 从存储的 tag 结构中获取 tag 的数据,然后查询到此 tag 对应的时序数据部分的内容,拿到整体的数据后进行 merge,输出为一条完整的数据传递给上层进行计算处理。
时序数据处理时会有选择性优化,比如关系数据和时序数据进行关联查询时:
• 如果关系数据的过滤性高并且关系数据和时序数据关联的条件中使用的是时序的 tag 值,则会选择将关系的数据下推到时序引擎端进行计算,优化的计算方式可以是直接 hash 过滤 tag 数据,还可以是 look up tag 数据,以此来提高时序数据的检索效率,提前过滤掉时序的大部分数据,减少跨模传递的数据量。我们称这种优化的方式为 outside-in 优化。
• 如果关系数据没有过滤,并且在关联查询后进行了聚合计算,那么可以选择将聚合计算下推到时序引擎进行计算,来提前聚合时序数据,以达到减少时序部分数据量的效果,减少跨模传递的数据量。我们称这种优化的方式为 inside-out 优化。
回归业务本质的数据架构
多模数据库不是简单的技术堆砌,而是面向真实业务场景的架构革新。通过深度整合两种广泛使用的数据模型,它既保留了关系数据库强大的结构化处理能力,又具备了时序数据库的海量吞吐优势,这种融合架构也正在工业物联网、金融科技、车联网等领域展现出强大的生命力,也标志着数据库技术进入垂直深度优化的新阶段。


















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









