




 本文深入讲解GPU和渲染优化,介绍了GPU指令流水线,包括Instruction Cache、Scoreboard与指令依赖等;阐述延迟隐藏,涉及Stall、Warp Scheduler等;还分析了分支、数据访问、寄存器等方面,以及线程利用率、ALU和编译器优化等内容。
本文深入讲解GPU和渲染优化,介绍了GPU指令流水线,包括Instruction Cache、Scoreboard与指令依赖等;阐述延迟隐藏,涉及Stall、Warp Scheduler等;还分析了分支、数据访问、寄存器等方面,以及线程利用率、ALU和编译器优化等内容。
[引擎开发] 深入GPU和渲染优化(基础篇)_quad overdraw-优快云博客
在上述的基础篇中,我们对各种概念做了一个简单的介绍,在此篇文章中,我们将做更进一步的讲解。
GPU指令流水线
CPU的设计更加偏向于复杂的逻辑计算,它可以通过分支预测、指令重排来提高执行效率,但它切换线程的上下文操作会比较重;而GPU则与之相反,它适用于大量相同指令的执行,而不擅长处理分支和逻辑,由于其切换线程的成本极低,GPU通常通过线程切换来隐藏延迟。
我们认为GPU的核心模块就是流式多处理器(Streaming Multiple Processor),本文将其简称为SM。一个SM上包含了多个Core,Core中有多个线程可以同时执行相同的指令(通常就是32/64个线程),这种多线程执行单一指令我们就称作SIMT(Single Instruction Multi Thread,单指令多线程)。我们把Core上执行的线程束称为warp,warp是一个软件层的概念,它也是shader执行的一个最小单位。
当我们发起一个GPU操作,比如Dispatch或Drawcall时,会根据顶点数/像素数/线程块数量去分配特定数量的warp去执行。
GPU遵循取指、译码、发射、操作数传送、执行、回写的流程。整个过程是顺序执行的,也就是会按照编写的顺序去排布一个个指令,不存在CPU中乱序发射的现象。

整个Shader的执行过程相当于一个不断取指-执行的过程,对于每个warp而言,当不再有任何指令的时候,我们认为warp执行完成,当GPU任务的所有warp完成后,我们认为该GPU任务完成。
GPU Cycle是GPU执行的最小时间单元,每个指令都会消耗不同倍数的GPU Cycle。当我们衡量Shader的执行效率时,我们可以简单的认为整体的GPU Cycle越短,Shader的效率越高。
在整个GPU指令流水线的过程中,GPU还会做不少事情:
Instruction Cache
在不同GPU硬件中,指令可能是变长或者定长的,比较常见的指令位宽是64bit。指令的每个位会去记录不同的信息,这个位宽越大,能记录的信息也就越多;不同类型指令的编码形式也会有所差异。
比如说会去记录输入数(SOP)和输出数(DOP)的地址,一些状态量、控制量等等。
每个Shader产生的所有指令地址循序记录在程序计数器(Program Counter)中,每完成一次一次取指,PC将往后挪一个单元,指向下一条指令。
取指的过程也就是从指令缓存(Instruction Cache)读取指令数,并且存储到指令寄存器的过程。假如说指令缓存未命中,则会发起一个从内存加载指令到指令缓存的异步请求。
一般来说,指令的缓存命中率都是非常高的。
Scoreboard与指令依赖
在指令流水线中,如果指令之间存在依赖关系,下一条指令需要在上一条指令完成后才能执行。但GPU实际上并不关心哪些指令之前存在依赖关系,它关心的仅仅是取指之后的指令是否是可执行的。
当我们取指并存储到I-Buffer(指令缓冲区)后,我们同时需要去记录这条指令是不是有效的,也就是说,它接下来能不能够被执行,这个信息会和指令一并记录到I-Buffer中。如果指令不能被执行,说明该指令依赖的一些数据还没有准备好,也就是相关的结果还没有写回到目标寄存器。
为了获取指令的可执行性,GPU需要知道的是输入数的寄存器是否已经被其它指令写入。这可以通过标志位来完成,我们称之为记分牌(Scoreboard)。如果标志位标识已经写入,那么下一条指令的输入是可用的,如果标志位未写入,下一条指令则会处于等待状态,它会定期检查标志位来更新自己的状态。
对于一些GPU来说,如果它认为一些指令产生的stall是定长的,它可能会自动添加一些stall count,来避免依赖的计算。而对于具有不定长stall的指令,则需要使用scoreboard来控制依赖。
SIMT-Stack
GPU不具备很好的处理分支·、跳转和循环的能力。当shader代码中出现了分支后,GPU采取的做法是分支的if和else两部分逻辑都会去执行,并且每部分逻辑执行的时候,只会对满足条件的线程去执行。
那么,如何去确认哪个线程是满足条件的呢?一种比较常见的GPU流程控制的方式是:GPU使用一个Active Mask去记录满足当前线程是否满足执行条件,每个线程会占用1个bit。
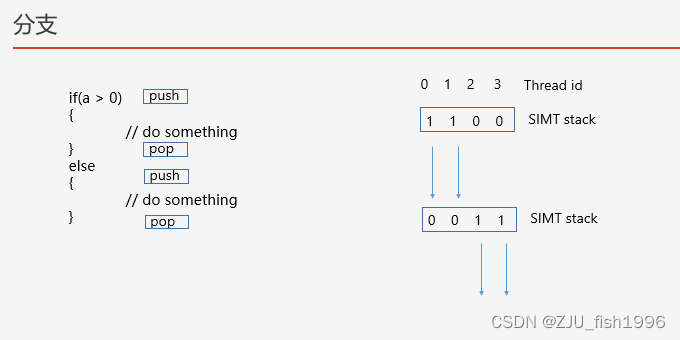
整体的分支控制是基于SIMT Stack模块来实现的。从名字我们可以看出来这是一个基于栈的设计,也就是说它伴随着一个入栈和出栈的过程,在进入分支的代码块后入栈,在离开分支的代码块后出栈,出栈的位置我们称为汇合点。
对于嵌套分支而言,就会伴随着更多入栈和出栈的流程:

SIMT Stack存储了:Active Mask、目标PC(Program Counter)、最近汇合点PC,如下图所示:

在上述的例子中,执行完所有Return PC为C的指令,才能开始执行NextPC为C的逻辑。如果SIMT栈顶的Next PC和I-Buffer中的Next PC一致,说明不存在分支。
我们可以把循环也看做分支的一种,在执行循环代码块前入栈,在执行完循环代码块后出栈,判断条件是循环的退出条件:

如果循环是动态的,也就是每个线程的循环次数不一致,那么循环次数少的线程就有可能会去等待循环次数多的性能,直到所有线程达到最终汇合点(active mask全部为0)。
GPU资源分配
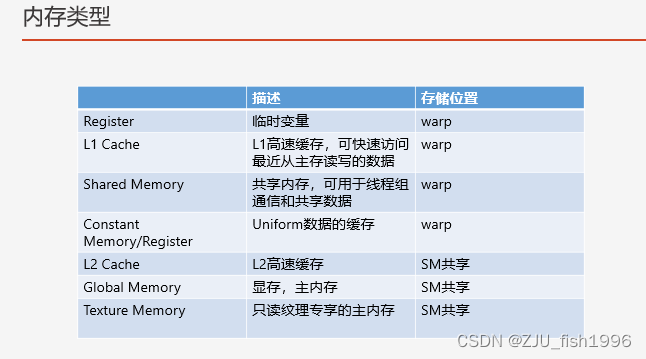
GPU设计是为了能够更快的执行并行计算,减少一些控制流的逻辑,所以大部分资源会在编译期就去计算使用的大小并预留分配,避免运行时动态的去计算。比较常见的就是常量寄存器、全局寄存器和共享内存,每个warp会根据使用情况分配对应资源。
由于这些资源分配是预先确认的,所以运行时不存在申请和销毁的逻辑,分配好的资源会固定预留给对应的线程。这样的弊端在于静态分析没有办法很好的处理分支的情况,它会假设所有分支都会执行到,这可能会产生一些冗余资源。
延迟隐藏
我们先来介绍GPU shader编程中重要的特性,延迟隐藏。
Stall
延迟隐藏从名字上来看,就是存在一些延迟的操作,但是被隐藏了,为什么能够隐藏呢?是因为在等待的期间,去做了一些其它的事情。这件事情非常好理解,就像做家务的时候,当你按下洗衣机的开关后,可以先去执行扫地的操作,而不是站着等待。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









