




 本文分享了作者接触Vulkan半年多的经验,介绍了Vulkan能更好控制底层、提升CPU端效率。详细阐述了Command Buffer的编码、提交频率、管理等内容,还涉及Upload Command Buffer、渲染调用、Barrier、RenderPass和SubPass等方面,分析了在ue4引擎中的应用及优化思路。
本文分享了作者接触Vulkan半年多的经验,介绍了Vulkan能更好控制底层、提升CPU端效率。详细阐述了Command Buffer的编码、提交频率、管理等内容,还涉及Upload Command Buffer、渲染调用、Barrier、RenderPass和SubPass等方面,分析了在ue4引擎中的应用及优化思路。
接触Vulkan大概也有大半年,概述一下自己这段时间了解到的东西。本文实际上是杂谈性质而非综述性质,带有严重的主观认知,因此并没有那么严谨。
使用Vulkan会带来什么呢?简单来说就是对底层更好的控制。这意味着我们能够有更多的手段去提升绘制的效率。这里Vulkan主要能够提升的是CPU端的效率,GPU端的效率是无法直接提升的。
这里所说的提升CPU的效率,实际上描述的是Vulkan能够更好地控制渲染数据的准备,那么这个渲染数据的准备具体来说就是完成渲染指令的编码。
那么作为开发者来说,在已经封装好的Vulkan框架下,还有必要了解Vulkan的实现细节吗?在我看来,还是很有必要的。一个通用的引擎提供的是比较普适性的封装,这意味着它基本不会出错,但并不会考虑到每个项目的实际情况,进而没有办法发挥出Vulkan本身的优越性。
编码渲染指令
Vulkan的工作简单来看就是编码渲染数据,提交给GPU,如此反复。编码渲染数据是在CPU段发生的事情,因此会消耗CPU时间。而直到数据被提交到GPU,GPU才会知道自己需要做什么。
在Vulkan中,Command Buffer就是用于记录绘图操作、内存传输以及计算调度等任务的缓冲区。我们所谓的编码渲染数据,就是填充Command Buffer,所谓的提交到GPU,就是把Command Buffer从CPU传输到GPU,整个过程从另外一个角度来看就是一个数据流的过程。
从这里可以看出来,我们之所以说Vulkan提供了更底层的控制,也就是说它其实把渲染的本质暴露了出来:填充编码了渲染任务的缓冲区,并把这个缓冲区数据传输到GPU。而在传统图形API中,Command Buffer的概念是隐藏的,我们只能指定要做什么,而我们指定的事情看起来就像是GPU即时去做的。
从功能性上来看,Command Buffer包含如下三种类:
① 编码绘制指令
② 编码计算指令
③ 编码上传指令
Command Buffer提交频率
把Command Buffer暴露出来,一个好处就是它更贴近底层实际在做的事情,第二个就是我们可以直观地去控制CPU和GPU的调度。
一个Command Buffer可以编码非常多个指令,这意味着我们可以在一帧的所有指令都放到一个Command Buffer中去编码。
由于频繁提交Command Buffer本身是耗时的,我们可以仅在必要的时候去拆分Command Buffer。我们多次提交Command Buffer是为了GPU尽快地响应我们的任务。
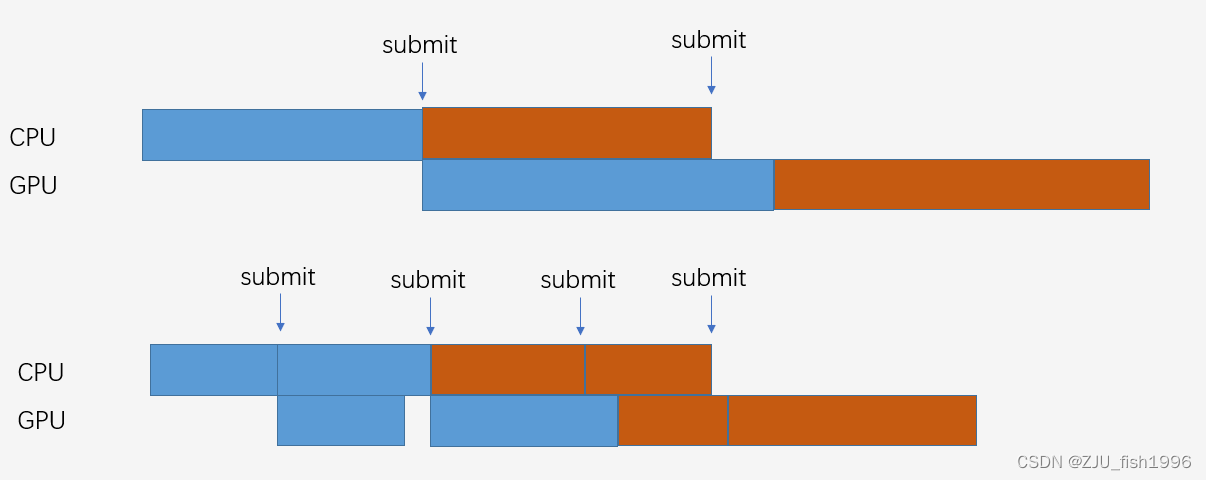
如图1所示,在我们不限帧的理想情况下,把一帧拆成两个Command Buffer使得整个绘制流程变得更紧凑了,GPU能够尽早地结束绘制任务,屏幕也能更快地拿到需要绘制的数据。这个越紧凑,那么拖累后续流程造成等待的情况也就越少。
这里实际上有一个容易让人产生误会的点,因为哪怕是仅用1个Command Buffer来提交,看起来CPU和GPU的利用率也没有直观上的下降,因为GPU只是较晚开始执行当前帧的任务,并不是完全停摆了,因为在当前帧CPU还没有准备好数据时,GPU可能还在执行上一帧的任务,整个流程仅仅是“滞后”了。
所以这里想要描述的Command Buffer数量的影响并不直接体现在利用率上,而是体现在周期上。也就是从CPU开始准备数据,到GPU结束的周期变短了,流程越短可能出现的卡顿越少。当我们后面讨论到交换链的时候,应该会对此有更好的理解。
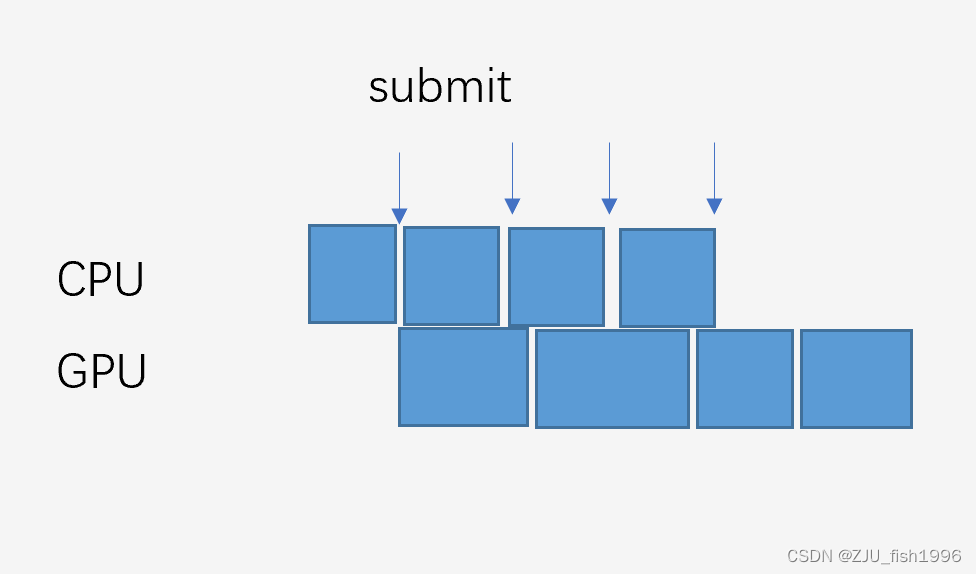
再来考虑另外一个极端的现象,如果我们把Command Buffer的粒度设置的足够小,那么整个渲染周期也会变得足够短,这相当于CPU端发起一个任务,GPU端立即执行一个任务。但是我们需要考虑到渲染指令的提交本身会产生一些额外的成本,这类似于文件系统多次少量写入效率会低于少次大量写入一样。所以通常来说我们会取一个折中的数值。
我们来看ue4引擎中对于Command Buffer拆分的设计。
它把传输指令(Upload)和渲染指令(Graphics,Compute)分配到不同的Command Buffer中,因为我们在执行渲染前通常需要保证数据都上传了,所以在Render Command Buffer提交前,需要确保Upload Command Buffer全部提交。
这样的话可以有效地把数据传输和图形渲染隔绝开,不过也仅仅是时序上的隔绝,ue4默认并没有添加额外的屏障,资源屏障需要我们上层正确的设置。但它也提供了相关的调试接口让我们来排除资源有效性的问题。
Upload Command Buffer什么时候提交,实际上ue4也并没有明确,而是提供了两种选项,一个是编码完成一个资源后立即提交,这是默认的选项;另一个是等到执行渲染指令的时候再去提交前面的Upload Command Buffer。前者的弊端是在纹理流式加载的时候,帧首可能会出现大量的Submit,这个是非常耗时的;后者的弊端是资源提交的过晚会阻塞渲染任务的提交,这里如何改进是一个值得思考的地方。
而对于其它渲染指令(Graphics,Compute),ue4默认拆分成两个Command Buffer,它首先会在Render主函数中的中间部分显式调用一次Submit,然后会在present之前强制调用一次Submit(不然无法保证正确性)。
在ue4默认的情况下,我们会有2个绘制的Command Buffer,至少一个Upload Command Buffer,CPU端可能会有多帧数据引用不同帧的Command Buffer,那么整体的一个Command Buffer画面静止情况下是个位数,在移动的过程中会涨到两位数。
Upload Command Buffer
我们刚刚说到默认情况下移动过程中Command Buffer会上涨,这里主要说的是Upload Command Buffer。我想对于绘制Command Buffer,由于它每帧都比较固定,大家不会有什么疑问。但是,究竟是什么情况下需要使用Upload Command Buffer呢?
首先需要明确一个前提,虽然Vulkan提供了桌面端的支持,但是绝大部分我们使用Vulkan的场景是在移动端,也就是统一内存(unified memory)环境。
Vulkan中资源的类型我们可以认为就是两种,Buffer和Texture,之所以这么区分是因为它们的内存排布不一样,Buffer是线性的,Texture可能是zigzag形状排列的,这是为了GPU端相邻四个像素访问的连续性。
这里的Buffer我们根据功能来说可能有Index Buffer, Vertex Buffer, Uniform Buffer, Texture Buffer。但这些对于上传来说都不重要,重要的是这个数据是否是Voliate的,也就是说它是否是单帧使用的。
如果它是多帧使用的,比如Index Buffer我们基本上不会去变动它,那么考虑到统一内存架构,我们在创建这个Buffer后就能直接拿到它映射后的CPU内存指针,可以直接进行内存操作,也不需要借助于Upload Command Buffer,因为我们可以在统一内存上操作,就不需要涉及到CPU到GPU的交互了。
在操作统一内存的时候,由于CPU和GPU都会访问到这段内存,我们要考虑到访问安全性的问题,这里Ue4使用了一种比较简单的做法就是多重缓冲,也就是GPU在使用第n个buffer的时候,CPU先去准备第n+1的buffer,这样就不会产生冲突了。这里假如我们不是操作统一内存,而是通过stagingbuffer调用vkCmdCopyBuffer去更新这段内存的话,就不需要考虑这种安全性问题了,如果你不能理解到这一点,说明对于command buffer本身只是记录命令这件事情理解的还不够到位。
而对于单帧使用的场景,我们可能会把它们标记为Voliate,比较常见的就是Uniform Buffer了,因为我们会有一些shader参数需要经常更新。这里最大的区别是非Voliate的Buffer会有固定的CPU句柄,而Voliate的Buffer会映射到一些临时分配的Buffer上,这样的话可以尽可能节约一些内存空间。为了降低Voliate类型的Uniform Buffer的临时缓冲区管理成本,ue也引入了业内常见的Ring Buffer方案。

但无论是什么类型的Buffer,在统一内存架构的情况下都是不需要Upload Command Buffer的。而纹理就比较特殊了,我们在前面说到纹理的GPU内存排布一般都不是线性的,但是我们在CPU中通常要么按行要么按列去存储纹理。这就涉及到一个转换问题,我们要保证上传到GPU的数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1540
1540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









