






leetcode:763. 划分字母区间 - 力扣(LeetCode)
题目
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。
示例:
- 输入:S = "ababcbacadefegdehijhklij"
- 输出:[9,7,8] 解释: 划分结果为 "ababcbaca", "defegde", "hijhklij"。 每个字母最多出现在一个片段中。 像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
提示:
- S的长度在[1, 500]之间。
- S只包含小写字母 'a' 到 'z' 。
思路
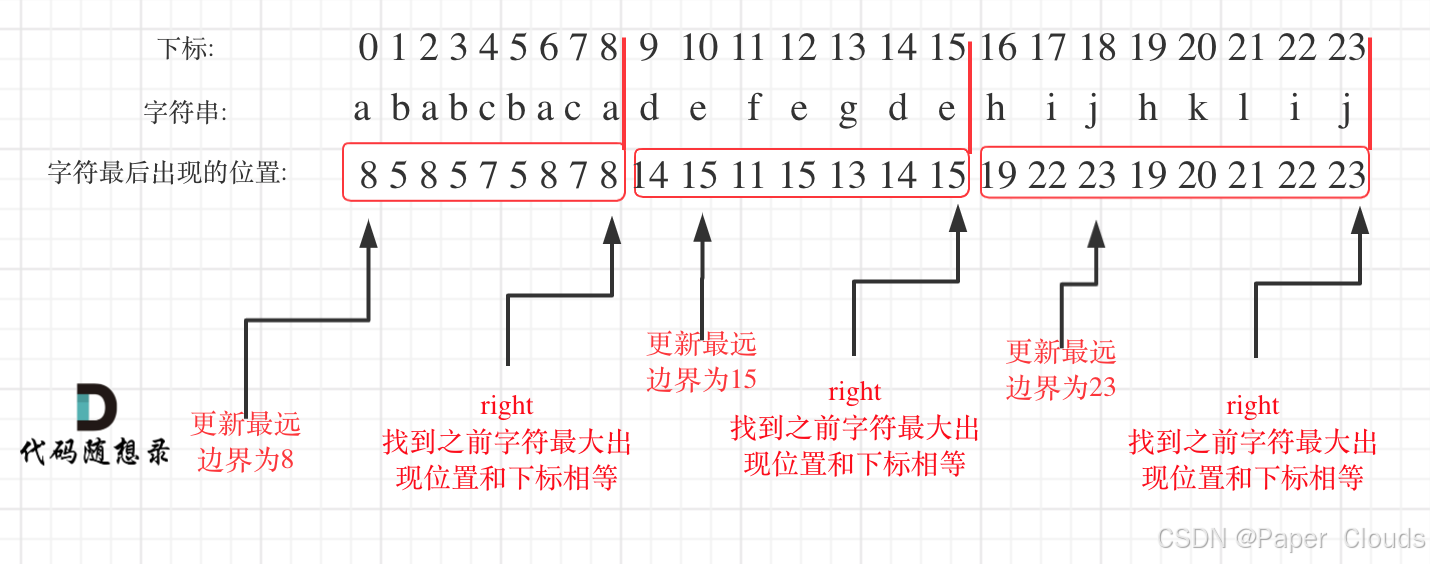
同一个字母一定要在同一区间片段内,也就是说字母出现的最远位置。如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点。
这道题的过程如下:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
如何找字符出现的最远下标,首先肯定是在遍历中操作,但是这里涉及到字符跟索引的对应关系?
这个思路之前有过,但是这次还是没想到:
使用数组(数组也算哈希表)hash来记录,映射字符到索引,而且用hash[S[i] - 'a']这种相对索引,避免了ASCII。
依次来看下步骤:
1、统计字符最后的出现位置
int hash[27] = {0};
for (int i = 0; i < S.size(); i++)
{
hash[S[i] - 'a'] = i;
}2、动态更新右边界
right = max(right, hash[S[i] - 'a']); // 更新当前区间的最远右边界 [[3]][[6]][[8]]例如,若当前字符 'a' 最后出现在索引 5,则 right 会被更新为 5,确保区间覆盖所有 'a' 的出现位置。
3、确定分割点
如果当前的i已经到了当前区间的最远右边界,就开始分割,然后把前面的这一段区间长度计算一下,加入到我们的结果里面。
if (i == right) { // 当遍历到当前区间的右边界时,完成一次分割 [[3]][[6]][[8]]
result.push_back(right - left + 1);
left = i + 1;
}整体代码:
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
class Solution
{
public:
vector<int> partitionLabels(string S)
{
// hash[i]为字符出现的最后位置
int hash[27] = {0};
for (int i = 0; i < S.size(); i++)
{
hash[S[i] - 'a'] = i;
}
vector<int> result;
int left = 0, right = 0;
for (int i = 0; i < S.size(); i++)
{
right = max(right, hash[S[i] - 'a']);
if (i == right)
{
result.push_back(right - left + 1);
left = i + 1;
}
}
return result;
}
};总结
hash的使用,对于这种字符的问题。

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









