






Zero-Shot YOLO Detection using Vision-Language Knowledge Distillation
问题.
- 什么是零样本检测?
- 视觉语言知识蒸馏是什么意思?
摘要重点
- To advance zero-shot detection, we develop a Vision-Language distillation method that aligns both image and text embeddings from a zero-shot pre-trained model such as CLIP to a modified semantic prediction head from a one-stage detector like YOLOv5.
为了推进零样本检测,我们开发了一种视觉-语言蒸馏方法,对齐来自零样本预训练模型的图像和文本嵌入。比如将像CLIP与将CLIP与修改后的语义预测头相结合。像YOLOv5这样的单阶段检测器的修改语义预测头。
-
With this method, we are able to train an object detector that achieves state-of-the-art accuracy on the COCO zero-shot detection splits with fewer model parameters.
训练出一个对象检测器,在COCO零样本检测分割上达到了最先进的准确度,并且模型参数更少。 -
During inference, our model can be adapted to detect any number of object classes without additional training.
在推理过程中,我们的模型可以适应检测任意数量的物体类别,无需额外训练。 -
We also find that the improvements provided by the scaling of our method are consistent across various YOLOv5 scales.
我们还发现,我们方法的扩展带来的改进在不同的YOLOv5规模上是一致的。
Furthermore, we develop a self-training method that provides a significant score improvement without needing extra images nor labels.
此外,我们开发了一种自训练方法,它在不需要额外图像或标签的情况下提供了显著的得分提升。
- 视觉-语言蒸馏方法,将像CLIP这样的零样本预训练模型的图像和文本嵌入与像YOLOv5这样的单阶段检测器的修改语义预测头对齐。
- 自训练方法,它在不需要额外图像或标签的情况下提供了显著的得分提升。
现实世界的对象采样会产生长尾分布,需要为稀有类型增加指数级的图像。旨在检测看不见的物体的零样本检测是解决这个问题的一个方向。
结论
- ZSD-YOLO,这是一个零样本检测器,它在COCO数据集上两个主要的零样本检测设置中超越了之前所有的零样本检测结果。
- 此外,我们设计了一种自标记方法,可以在不需要新数据或标签的情况下提高零样本检测性能。我们探索了传统扩展方法对零样本检测任务的影响,并发现典型的模型扩展可以很好地转移到我们的架构中,从而创建一系列高效准确的零样本检测器。
1.导言
零样本检测(Zero-shot Detection, ZSD)[1]是目标检测领域的一个重要研究方向,因为在模型开发过程中预测每一个可能的探测器应用是困难且常常是不可能的。例如,为了开发一个黑猩猩检测器[31],动物科学家需要收集专门的训练数据并对黑猩猩进行详尽的标注,但如果使用零样本检测器,他们可以使用一个普遍训练的检测器,简单地通过new reference embeddings来进行检测。零样本检测系统的另一个主要优势是,使用零样本检测器的应用可以更容易地在通过研究做出新的优化时更新到最先进的方法,因为它们不需要任何重新训练,并且可以立即部署到任何检测应用中。
典型的目标检测器在固定数量的类别上进行训练。PASCAL VOC数据集[5]包含20个类别,而COCO数据集[20]包含80个类别。这些数据集激发了许多重要的目标检测方法,如DPM[7]、R-CNN家族[9, 8, 30]、SSD[21]、YOLO[28, 29]。为了扩展标准目标检测器的词汇量,研究社区还收集了包含1203个对象类别的数据集,如LVIS[11]。但由于Zipf定律,这些对象遵循标准的长尾分布,因此收集大量罕见类别的训练样本仍然是一个困难的任务,需要指数级更多的图像来找到足够的罕见类别。虽然在提高罕见类别检测准确性的研究已经取得了广泛进展,模型对罕见对象的评分仍然明显较低。相比之下,收集配对的图像和文本描述要容易得多,因为这些图像可以从互联网上获取,以组装像YFCC100M[15]这样的大型训练数据集。使用这个数据集,Radford等人[25]在一系列具有不同类别粒度的计算机视觉数据集上展示了令人印象深刻的零样本能力,如[2, 3, 16, 22],但Radford等人尚未探索零样本在目标检测上的能力。在这项工作中,我们从CLIP[25]的文本和图像两侧提取信息,并开发了一个零样本目标检测系统,用于修改YOLOv5模型[14],以创建一个快速准确的零样本检测模型。
为了实现这一目标,我们提出了一种方法,通过从trained vision language model中提取知识,来适应传统的单阶段检测网络以执行零样本检测。**我们首先改变检测网络的典型类别输出,以创建与CLIP模型嵌入形状相等的输入。为了获得文本嵌入,我们将类别名称和提示结构输入到文本编码器中,这些嵌入与模型的语义输出使用修改后的交叉熵损失函数进行对齐。**与之前只从文本嵌入对齐中学习的ZSD工作(如[1, 27, 36])相比,我们的方法还考虑了图像嵌入对齐。我们发现,将图像嵌入添加到我们提出的损失函数中,可以显著提高模型性能。为了获得图像嵌入,我们裁剪真实的边界框,并将这些输入到CLIP[25]图像编码器中。然后使用L1损失函数对模型类别输出进行对齐。此外,我们为YOLO[28]风格的模型创建了一种新的后处理操作,专门针对ZSD任务,以更好地在仅检测未见类别时过滤掉已见类别的实例。YOLO和其他检测模型提供的另一个关键优势是它们的可扩展性,以便在各种设备上运行推理。为了将这一优势扩展到ZSD模型,我们探索了标准扩展操作对YOLO模型家族的影响,发现我们提出的方法可以像标准YOLO模型一样进行扩展,同时权衡mAP推理速度。
- predicting every possible application of detectors during model development is difficult and often impossible
在模型开发过程中预测每一个可能的探测器应用是困难的,通常也是不可能的。 - zero-shot object detector
could use a generally trained detector and simply detect using new reference embeddings
零样本目标检测器,可以使用一个通用训练好的检测器,并通过简单地使用新的参考嵌入来进行检测。
零样本检测系统的另一个主要优势在于,使用零样本检测器的应用可以更加轻松地更新到最先进的方法。
当研究有新的进展的时候,我觉得可能是目标检测模型的优化改进吧,ZSD可以更轻松的跟进到先进的方法中,因为他用的是训练好的检测器,不需要再重新训练了可以立即部署到任何检测应用中。
可以感觉到有点象即插即用的模块 - 典型的目标检测器在固定数量的类别上进行训练这些方法通常需要在有限的类别集合上进行训练,并且能够检测这些类别中的物体。这意味着,对于这些检测器来说,它们在训练时能够识别的物体类别是固定的,而在实际应用中,它们可能无法识别训练时未见过的类别。
为了扩展标准目标检测器的识别范围,研究社区还收集了包含更多类别的数据集,比如LVIS(Large Vocabulary Instance Segmentation)数据集,它包含了1203个不同的物体类别。
这些物体遵循一种标准的长尾分布,这意味着常见类别的物体实例数量远多于罕见类别。为罕见类别收集大量的训练样本仍然是一个困难的任务,并且需要指数级更多的图像来找到足够的罕见类别样本。
目前模型在稀有物体上的得分仍然相当低(虽然有了很多进展),相比之下,收集配对的图像和文本描述是一项更为简单的任务,因为这些图像可以从互联网上获取,以组装像YFCC100M[15]这样的大型训练数据集。利用YFCC100M这个数据集,Radford等人[25]在多个具有不同类别粒度的计算机视觉数据集上展示了令人印象深刻的零样本学习能力,就是之前的CLIP论文,例如[2, 3, 16, 22]。这些数据集涵盖了从粗粒度到细粒度的各种类别。然而,Radford等人并没有探索零样本学习在目标检测任务上的能力
因此,我们从CLIP模型的文本和图像两个方面提取信息,并开发了一个零样本目标检测系统,用于修改YOLOv5模型,以创建一个快速且准确的零样本检测模型。
我们提出了一种方法,通过从训练好的的视觉-语言模型中提取知识,来适配传统的单阶段检测网络进而进行零样本检测。我们修改了检测网络的典型类别输出,进而与CLIP模型的输入相匹配。
为了获得文本嵌入,我们将类别名称同一个提示结构输入到文本编码器中,这些嵌入与模型的语义输出使用修改后的交叉熵损失函数进行对齐。
作者不仅考虑了文本嵌入对齐,还考虑了图片嵌入对齐,一下子明显提升了模型性能。为了获得图像嵌入,我们裁剪出真实标签的边界框,并把这些裁剪后的图像输入到CLIP模型的图像编码器中。类别输出随后使用L1损失函数进行对齐。我们为YOLO风格模型创建了一种新的后处理操作,专门针对零样本检测(ZSD)任务,以便在仅检测未见类别时更好地过滤掉已见类别的实例。YOLO和其他检测模型提供的另一个关键优势是它们能够进行扩展,以便在各种设备上运行推理。为了将这种可扩展性的优势应用到零样本检测(ZSD)模型上,我们研究了将标准扩展(缩放)操作应用于YOLO一系列模型是如何影响模型的平均精度(mAP)和推理速度之间的权衡的。我们发现,我们提出的方法可以像标准YOLO模型一样进行扩展。
- 通俗来说我们要让计算机能够理解图片里的东西,但有时候我们没有那些东西的图片,只有文字描述。为了解决这个问题,我们用了一个技巧:
- 把文字变成数字:
我们把描述物体的词语,比如“狗”或“树”,输入到一个工具里(这个工具叫做文本编码器)。这个工具可以把文字转换成一串数字(我们叫它文本嵌入),这串数字能代表这个词意思。
- 教计算机匹配文字和图片:
然后,我们用一种特殊的方法(叫做修改后的交叉熵损失)来教计算机,让它知道这些代表文字的数字和它从图片中看到的东西之间的关系。这样,计算机就可以通过这些数字来认出图片里的东西,即使它之前没有直接从图片中学到过这些东西。
简单来说,这个过程就像是给计算机一个物体的名字和一些提示,然后让它自己去理解这个名字和图片里的东西是怎么对应的。这样,即使计算机之前没有见过某些东西的图片,它也能通过名字来认出这些东西。
  Zipf定律通常用来描述许多自然和社会现象中的分布情况,其中少数常见事件的发生频率远高于大量罕见事件。在目标检测的上下文中,这意味着像“人”或“汽车”这样的常见物体类别有很多训练样本,而像“长颈鹿”或“钢琴”这样的罕见类别则样本较少。
  这种分布导致了所谓的“长尾问题”,即在数据集中少数类别有很多样本,而大多数类别只有很少的样本。这给机器学习模型的训练带来了挑战,因为模型可能会对常见类别过拟合,而对罕见类别的检测性能较差。为了解决这个问题,研究人员需要开发新的方法来平衡类别之间的样本数量,或者提高模型对于罕见类别的检测能力。零样本检测(ZSD)是应对这一挑战的策略之一,它允许模型在没有直接在训练样本中见过某些类别的情况下进行检测。
- 有三点贡献
1. 提出了ZSD-YOLO,这是一个单阶段的零样本检测模型,它从对比训练的视觉-语言模型中提取视觉和语言信息。
2. 开发了一种自标记方法,将我们的零样本检测模型在48/17[1]和65/15[26]分类任务上的mAP得分分别提高了0.8和1.7。
3. 对之前零样本检测模型的速度进行了基准测试,并且训练了多个规模的ZSD-YOLO,发现我们提出的模型能够像YOLOv5一样进行扩展。
2.相关工作
Zero-shot Learning:
零样本学习的目标是开发一个模型,这个模型能够识别在训练过程中未曾见过的类别。在ZSL中,依然有一些已标注的训练实例存在于特征空间中,这些实例所属的类别被称为已见类别(seen classes)。而我们把那些未标注的实例视为未见类别(unseen classes)。在ZSL领域,许多先前的研究工作都集中在属性学习上,其核心思想是学习识别物体的属性。这种方法可以追溯到Dietterich和Bakiri的研究[4]。Farhadi等人[6]以及Palatucci等人[24]在他们的研究中强调了在训练过程中学习属性时避免混淆的重要性。在推理阶段,他们的方法会预测属性,并将预测出的属性与未见类别的嵌入向量结合起来,使用相似度来推断类别。Lampert等人[17]开发了一个级联的概率框架,在推理阶段,第一阶段获得的预测可以被结合起来进行目标分类。这个框架提供了两种方法:
有向属性预测(Directed Attribute Prediction, DAP)
无向属性预测(In-Directed Attribute Prediction, IAP)
区别在于:预测属性时不会考虑属性之间的顺序或依赖性。
最近,CLIP[25]采用了对比学习的方法,联合训练了一个图像编码器和一个文本编码器在[15]的一个子集上,创建了一个网络,该网络能够预测一批图像-文本训练样本的正确配对。在推理阶段,学习到的文本编码器通过嵌入目标数据集标签的名称或描述,合成了一个零样本线性分类器。然而,CLIP模型并没有展示如何将这个预训练模型用于目标检测,而目标检测任务要求模型能够在复杂场景中定位并分类多个物体。
Zero shot detection:
零样本检测(Zero-Shot Detection,ZSD)是由Bansal等人[1]提出的,它描述了在训练集中没有标记样本的情况下检测物体的任务。[1]通过将模型输出映射到词向量嵌入中,使用线性投影的方法建立了一个基线模型,并在COCO2014数据集上创建了48/17的基准测试分割,这在零样本检测工作中常用。朱等人使用了YOLOv1来提高零样本对象的召回率。
而拉赫曼等人则采用了RetinaNet检测器进行零样本检测,并使用极性损失(Polarity Loss)来增加类别之间的距离。此外,他们还在COCO数据集上引入了65/15的零样本检测分割,这是另一个常用的零样本检测的评估基准。
- 注:65/15分割:这是一种数据集分割方式,其中65%的类别在训练集中可见,而15%的类别在训练集中不可见。这种分割方式用于评估模型在零样本检测任务中的表现,即在没有直接训练样本的情况下识别新类别的能力
李等人开发了一种注意力机制来解决零样本检测问题。赵等人使用生成对抗网络(GAN)来生成未知物体的语义表示,用来帮助检测未见物体。朱等人提出了DELO(Detection with Explainable Latent Optimization)方法,该方法能够从语义信息中合成未见物体的视觉特征,并将已见类别和未见类别的检测结合起来。
郑等人[36]提出了一种方法来解决零样本实例分割任务,该方法包括零样本检测器、语义掩码头、背景感知的区域提议网络(RPN)和同步背景策略。他们展示的方法在零样本目标检测和零样本实例分割方面都超越了之前的最佳方法。然而,这种方法的绝对性能还远未达到理想状态。此外,他们的架构并没有针对最小化推理时间进行优化。
Hayat等人[12]的方法在训练生成网络时需要知道未见过的语义属性,而我们的方法以及之前的工作,如[26]和[36],可以在没有未见类别的先验语义知识的情况下进行训练,并且能够在不需要任何重新训练的情况下对一组新的未见物体进行推理。因此,我们的论文以及之前的零样本检测论文,如[36],在基准测试中没有与他们的方法进行分数比较。
Gu等人[10]最近探索了如何从CLIP模型中进行知识蒸馏,以改善使用两阶段方法Mask-RCNN[13]的对象实例分割。我们的论文探索了将CLIP蒸馏后的信息嵌入到单阶段检测器,这些检测器在轻量级设置下的表现被证明比如Zou等人[40]所述的两阶段检测器更好。这项任务需要开发一个新的训练算法来进行知识蒸馏,以及对典型的YOLOv5模型架构进行修改。为了优化我们的方法,我们对典型的YOLOv5后处理方法进行了定制,以适应ZSD,并开发了一种自标记数据增强方法来扩展ZSD模型的知识。我们还探索了模型缩放,这是传统检测系统的另一个关键方面,它允许模型架构适应不同计算约束下的各种应用。
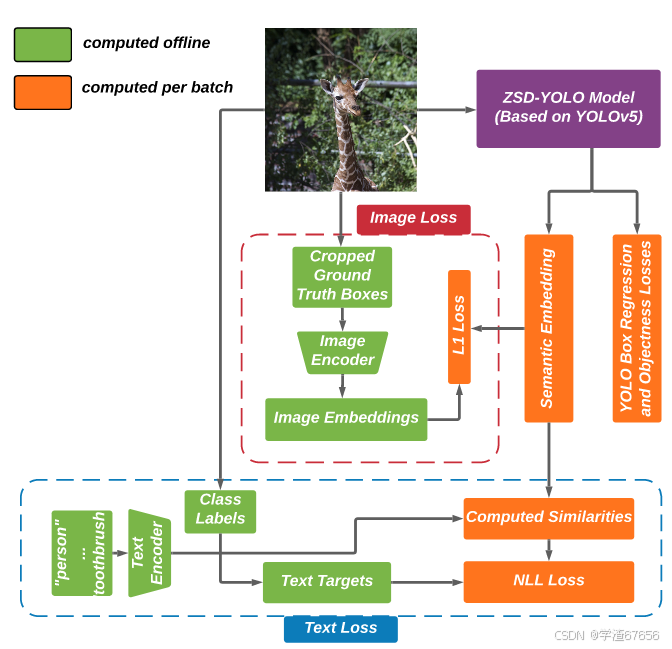
图1概述了使用ZSD-YOLO进行零样本目标检测训练的过程。ZSD-YOLO从预训练的视觉-语言模型(如CLIP)中提取知识。我们对YOLOv5进行了修改,用与CLIP模型嵌入大小相等的语义输出替换了典型的类别输出。然后,ZSD-YOLO使用第3.1节中描述的修改后的交叉熵损失函数,将正匹配锚点的预测语义输出与相应的真实文本嵌入对齐。接着,使用第3.2节中描述的修改后的L1损失函数对图像嵌入进行对齐。
3.方法Methodology
蒸馏的主要过程涉及修改YOLOv5[14]检测头,使其产生一个语义嵌入,该嵌入通过模仿CLIP模型的输出来学习CLIP模型的嵌入空间。为了实现这一点,我们修改了检测头,使其除了目标性(objectness)和边界框偏移(box offset)输出外,还能输出512个值,以匹配CLIP ViT-B/32模型[25]的512个输出。使我们的模型学习CLIP的嵌入空间,我们计算了文本和图像嵌入的蒸馏损失。为了使我们的模型学习的CLIP的嵌入空间,我们计算了文本和图像嵌入的蒸馏损失。
如图1所示,我们提议从一个视觉-语言模型(如CLIP)中提取知识,以适应一个单阶段检测器YOLOv5进行零样本检测。
基础模型的选择
我们选择YOLOv5模型家族作为我们的基础模型,主要有两个原因。
- 1 由于典型的检测模型通常被修改为每个锚点只产生一个边界框回归输出以完成ZSD任务,我们认为YOLOv5更适合零样本检测任务因为它已经每个锚点只使用一个边界框回归输出,而大多数基于锚点的目标检测器是每个类别使用一个回归输出。
- 2 YOLOv5模型以及其他的YOLO模型通常在标准的监督式目标检测中提供了最佳的推理速度和mAP(平均精度均值)之间的权衡,我们发现这些优势也能很好地转移到零样本检测任务中。
- 3 大多数两阶段检测模型不同,单阶段模型会为每个锚点计算类别置信度,而不考虑目标性得分,这允许即使对应锚点的目标性得分较低,也能改善对未见物体的检测。
3.1文本嵌入蒸馏
文本嵌入蒸馏过程涉及将模型的语义输出与由CLIP生成的目标文本嵌入对齐。这一过程的概述在图1中的点状蓝框内标出。为了计算文本嵌入的损失,我们首先通过将每个已见类别名称输入改为:prompt “A photo of {class} in the scene”来生成已见文本嵌入。设ti表示第i个已见类别名称计算出的文本嵌入,设T表示所有已见类别嵌入的集合,记作T = [t1, t2, · · · , tn ].。在图1中,T就是“文本编码器”的输出。
为了计算text loss,下一步我们要收集所有positive anchors输出的语义类别特征,是不是positive anchors我们用交并比IoU来衡量,设定一个score threshold即阈值,超过这个阈值后就可以判为positive,设 mi表示第 i 个模型的Semantic Embedding。M 表示这批数据中这些嵌入的集合M = [m1, m2, · · · , mn ]
然后,我们使用余弦相似度计算生成一个相似度矩阵,该计算关联了模型嵌入语义特征 M 和已知的文本嵌入 T 。此外,我们对这些相似度应用了温度为τ的softmax函数。

为了计算最终的损失值,我们针对每个正向匹配的锚点收集对应的真实边界框标签类别,并创建与生成的相似度矩阵 z 形状相同的独热编码标签向量 y。最终的文本损失通过负对数似然函数计算,该函数关联了 z 和 y。表达式可以写为
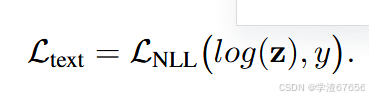
3.2图像嵌入蒸馏
图像嵌入对齐的过程涉及将每个正锚点(positive anchor)的语义输出与通过应用CLIP图像编码器到每个裁剪的真实边界框(ground truth box)生成的相应图像嵌入进行匹配。这与在文本嵌入蒸馏中选择的锚点相同。图像损失计算的概述可以在图1中的红色点线框中找到。
对图像进行的预处理是基于CLIP官方预处理流程调整的,其中典型的中心裁剪被替换为对所有裁剪区域进行224像素的统一缩放。我们的最终图像损失函数是使用简单的L1损失来计算的。虽然在超参数搜索过程中,我们尝试了为距离函数添加一个平滑的指数因子,但这些尝试并没有带来任何统计上显著的性能提升。
Mg, named ”Semantic Embedding”,表示与真实标注匹配的锚点的模型嵌入输出;
Ig, named ”Image Embeddings”,代表相应的目标向量嵌入。

3.3. Learning from self-labeling
为了在保持相同的基础标签集的同时增加模型可以学习的样本数量,在已见类别上,我们在训练的原始基础权重上进行自标记。
为了实现这一点,我们对每张训练图像进行推理,并运行非极大值抑制(NMS):包括真实标签,使用0.2的交并比(IOU)阈值和0.3的目标性阈值。在这次NMS操作中,真实标签总是优先于生成的标签。
-NMS 是 Non-Maximum Suppression(非极大值抑制)的缩写,它是目标检测领域中常用的一种技术,用于筛选和优化检测结果,去除多余的边界框,从而保留最佳的检测结果。
在训练期间,这些自标记的边界框被视为真实标签,用于定位损失、边界框回归和目标性评分的目的。我们发现,这样做可以让模型通过提供更多样化的物体样本来学习更通用的物体定位表示。对于分类损失,我们使用了之前的方法,即对图像进行裁剪并应用CLIP图像编码器到裁剪的图像块上,以及相同的损失计算。设 Ms表示与自标记框正匹配的模型语义输出,而 I s表示相应的目标图像嵌 入,那么包含自标记的最终图像损失函数可以写为:
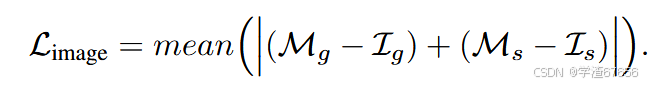
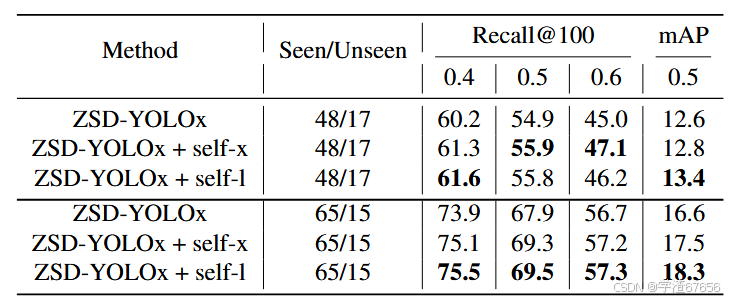
自标记的效果:我们在表1中记录了自标记的效果。请注意,除非另有说明,根据之前的零样本检测(ZSD)工作,mAP将始终指mAP@0.5。
我们进行了测试,首先是不使用自标记的“ZSD-YOLOx”,然后是使用模型自身基础权重生成的自标记“ZSD-YOLOx + self-x”,最后是使用另一个模型规模的基础权重进行自标记,我们使用ZSD-YOLOl的基础权重“ZSD-YOLOx + self-l”,这种方法是我们观察到的最佳的方法。指标最好
表1. 自标记方法对ZSD-YOLOx尺寸模型训练结果的影响比较。ZSD-YOLOx是我们方法在最大规模YOLOv5模型,即YOLOv5x上的应用。自标记的增加部分用self-x表示,意味着使用ZSD-YOLOx基础权重3.6生成自标记;self-l表示使用ZSD-YOLOl预训练基础权重生成自标记,这在两个分割上都以显著的优势提供了最佳结果。
- 表1. 自标记方法对ZSD-YOLOx尺寸模型训练结果的影响比较。ZSD-YOLOx是我们方法在最大规模的YOLOv5模型上,即YOLOv5x上的应用。自标记的增加部分用self-x表示,意味着使用ZSD-YOLOx基础权重3.6生成自标记;self-l表示使用ZSD-YOLOl预训练基础权重生成自标记,这在两个分割上都以显著的优势提供了最佳结果。
自标记方法在48/17和65/15类别分割上分别提供了0.8 mAP和1.7 mAP的整体提升。
通过实验,我们还发现,使用自身基础权重进行自标记的模型新学习到的物体数量明显少于使用另一个模型规模进行自标记的模型,因为后者通常会产生一组在预训练中未曾学习过的物体。当ZSD-YOLOx尺寸的模型使用ZSD-YOLOl进行自标记时,在48/17和65/15类别分割上,mAP的增益分别是0.6 mAP和0.8 mAP,比使用相同模型规模的ZSD-YOLOx自标记时要高。因此,在我们第4.4.3节的扩展实验中,我们使用ZSD-YOLOl尺寸的检测器对每个模型进行自标记,以基准测试其他每个模型规模的性能,并且不包括ZSD-YOLOl。
结合了两种损失函数的完整损失函数
在零样本检测(Zero-Shot Detection, ZSD)的上下文中,“Dual Loss function” 可能涉及到两种不同类型的损失:图像嵌入损失和文本嵌入损失。
将文本和图像蒸馏损失结合起来,形成一个带有权重值
Wt和 Wi 的单一函数,就得到了我们的完整损失函数,可以写为:
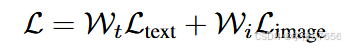 与之前只从文本嵌入对齐中学习的零样本检测(ZSD)工作相比,如文献[1]、[27]和[36],我们的方法能够结合双重损失并从文本和图像嵌入中学习。我们通过在保持其他超参数不变的情况下,分别抑制图像损失或文本损失进行训练,研究了损失函数各个组件的效果。
与之前只从文本嵌入对齐中学习的零样本检测(ZSD)工作相比,如文献[1]、[27]和[36],我们的方法能够结合双重损失并从文本和图像嵌入中学习。我们通过在保持其他超参数不变的情况下,分别抑制图像损失或文本损失进行训练,研究了损失函数各个组件的效果。
我们在表2中展示了我们的结果。我们发现,在65/15分割上,仅使用图像损失的性能比仅使用文本损失的性能更差,而在48/17分割上仅略有改善。但是,通过结合图像和文本损失,我们的方法显著优于仅文本学习的方法。这表明图像嵌入蒸馏的加入改进了给定嵌入空间的学习,我们相信对图像嵌入蒸馏的更优化的损失函数可能会进一步完善这种方法,并将这一点留作进一步研究。
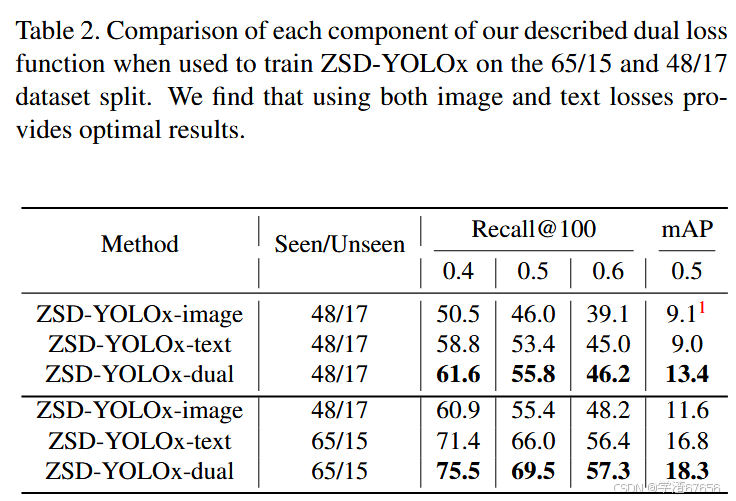
- 表2. 在65/15和48/17数据集分割上,使用所描述的双重损失函数的各个组件训练ZSD-YOLOx时的对比。我们发现,同时使用图像和文本损失可以提供最佳结果。
3.5. Inference on Unseen classes 对未见过类别的推理
在推断过程中,我们会使用一组新的参考文本嵌入,并且以训练时相同的方法来计算相似度矩阵 z。此外,我们还研究了如何修改经典的YOLO的后处理即名为Postprocessing的过程,目的是为了减少在检测未见类别时对已见类别物体赋予过高置信度的倾向,因为在objectness score中这些已见类别物体往往更受青睐
- 在目标检测任务中,模型需要识别图像中的物体,并给出每个检测到的物体的置信度分数。这个置信度分数表示模型认为检测到的物体属于特定类别的确定性。通常情况下,模型对于它在训练过程中见过的类别(即已见类别)会更加自信,因此在推理时会给这些已见类别的物体更高的置信度分数。
- 然而,这种倾向会导致一个问题:在进行零样本检测(ZSD)时,即检测那些在训练过程中未曾见过的类别(即未见类别),模型可能会错误地给已见类别的物体赋予过高的置信度,而忽视或降低对未见类别物体的置信度。这种现象称为“典型偏见”。
- 为了减少这种偏见,研究人员探索修改YOLO模型的标准后处理步骤。Postprocessing后处理步骤包括非极大值抑制(NMS)和置信度阈值过滤等,这些步骤决定了哪些检测结果会被保留下来作为最终输出。通过调整这些后处理步骤,研究人员试图使模型在检测未见类别时,不会过度偏好已见类别的物体,从而提高对未见类别物体的检测准确性。
总结来说,这句话的意思是,在零样本检测中,为了减少模型对已见类别物体的偏好,研究人员对YOLO模型的后处理步骤进行了调整,以期在检测未见类别物体时能够给出更公平、更准确的置信度分数。
- objectness score:是指模型对于某个区域是否包含目标物体的置信度。它是一个介于0和1之间的值,值越高表示模型越有信心该区域包含目标物体
3.5.1 Text embeddings during inference
由于COCO数据集中某些类别的模糊性,CLIP经常无法正确地嵌入(即生成准确的文本嵌入)某些类别的词汇。因此,在推理过程中,我们还包括了类别的定义,使用提示“a photo of class, definition, in the scene”来进一步纠正嵌入,并为每个类别提供更多的准确度吧。虽然这种方法确实提供了整体分数的提升,但并非所有类别的mAP都有所提高。与前面一样,我们还是在ZSD中对所有未见类别以及在广义零样本检测(GZSD,generalized zero shot detection)中对所有类别一视同仁的地应用这个prompt,因为基准测试必须遵循这些限制。
3.5.2 Postprocessing
在生成预测结果时,我们首先按照YOLOv5标准后处理流程,应用了一个对象性(objectness)得分的阈值(Cutoff)0.001。这意味着只有当锚点的对象性得分高于0.001时,我们才会将其保留下来进行后续处理。对象性得分是模型对锚点包含物体的置信度的度量,通过设置这个阈值,我们可以过滤掉那些模型认为不太可能包含物体的锚点。
对于所有剩余的锚点,我们通过将它们的对象性得分乘以在训练中通过应用温度softmax计算出的每个锚点的最大相似度值来创建一个置信度值。
什么是温度Softmax Temperature,其他大佬的文章可以看下
在GZSD期间,我们分别计算已见类别和未见类别之间的相似度。这个过程类似于两次运行我们的检测器,一次使用已见文本嵌入,一次使用未见文本嵌入,但我们编写的后处理代码能够更高效地执行这一过程,在与ZSD检测的速度相比时,差异可以忽略不计。
然后,我们对这些生成的置信度分数应用0.1的阈值。对于剩下的这些预测,最终赋予的置信度分数就是计算出的最大相似度值,而不包括通常对已见物体有利的印象分加成。
对于我们的最终预测结果,我们使用了非极大值抑制(NMS)技术,并且设定了0.4的IOU阈值。在ZSD中,我们将最大检测数量限制为15;在GZSD中,限制为45。这个数值比通常设置为100的要低,因为我们的方法会产生大量的高置信度预测。
为了进行基准测试并计算Recall@100(即在最多返回100个检测结果的情况下的召回率),我们将最大检测数量增加到100,以便与之前论文中使用的基准测试规则保持一致,并将置信度阈值从0.1降低到0.001。[没有特别懂]
我们记录了后处理方法对ZSD的效果在表3中,对GZSD的效果在表4中。基线后处理指的是YOLOv5的标准后处理,它只应用了一个0.001的置信度阈值,通过将objectness score乘以最大类别得分来计算置信度分数,然后进行NMS。
为了公平比较,我们将基线后处理的NMS IOU阈值设为0.4,我们发现标准后处理在最大检测数量设为100时表现更好,因此我们将ZSD和GZSD的最大检测数量都设为100。
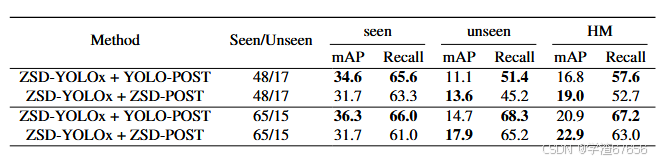
表3. 提出了后处理对ZSD基准测试效果的比较。"YOLO-post"代表典型的基线后处理,"ZSD-post"代表我们提出的后处理。

表4. 提出了后处理对GZSD基准测试效果的比较。"YOLO-post"代表典型的基线后处理,"ZSD-post"代表我们提出的后处理。
[总体感觉没什么用处]
3.6. Pretraining procedure|预训练过程
、
- 为了生成零样本检测训练所需的初始权重,我们在相同的seen类别数据集上,使用类别特定的标注信息训练了一个标准规模的YOLOv5模型。
这样做是为了使模型能够用类别特定的信息进行初始化。预训练过程与典型的YOLOv5模型相同,使用相同的架构和官方基础训练超参数。[yolov5代码]所有这些预训练过程都是用随机权重初始化的,并且仅在它们对应的已见标签数据集上进行训练。这个过程的主要目的是加快零样本检测模型的收敛速度,以便进行更快速的实验。
4. Experiments
在这一节,我们展示了基准测试的具体细节,并在零样本检测(ZSD)和广义零样本检测(GZSD)的标准下,将现有ZSD方法进行了比较。我们还探索了模型规模scaling,并与之前的最先进技术[36]相比,考察了我们的推理速度。
4.1. Dataset
在这部分中,我们对COCO数据集[19]上的零样本检测结果进行了基准测试,使用了Rahman等人[26]提出的65/15分割和Bansal等人[1]提出的48/17分割。这两个训练数据集是通过从COCO[19] 2014分割中移除所有的没见过的物体图像来生成的。由于过去的论文中对没有训练注释的图像的使用没有标准化,因此训练图像的数量略有变化。我们的论文不使用没有任何注释的训练图像,这使得65/15分割有61,598张训练图像,48/17分割有44,909张训练图像。
65/15分割的测试图像是通过取COCO 2014验证集中所有包含未见物体实例的图像,并移除已见物体实例注释来创建的,形成了一个包含10,098张图像的测试集。在GZSD评估期间,已见物体实例注释被加回到真实标签中。
48/17分割的测试集也是以同样的方式创建的,尽管只使用了随机抽样图像的一个子集。虽然我们不能保证所有先前的零样本检测论文都使用了相同的随机抽样子集进行48/17分割的零样本检测评估,但我们的验证集与之前的最先进技术Zheng等人[36]相匹配,该验证集在48/17分割测试集中有2,729张图像。
为了找到最好的训练方法和参数,我们创建了一个零样本检测的验证集,以免在标准测试集上调整参数。这个验证集包含了65/15分割中所有未见类别的图像,共有20,483张。我们没有对48/17分割做同样的处理,因为我们的方法已经在65/15分割上开发好了,直接应用到了48/17分割上。
虽然我们的方法在大多数recall基准测试中都有显著提升,我们还是选择mAP作为主要的评估指标,因为我们认为mAP@0.5对于COCO数据集上的零样本检测是一个更准确的评估指标。最初采用召回率主要是因为mAP@0.5的分数太低,无法进行比较。此外,将mAP@0.5作为零样本检测的主要指标,可以更精确地将零样本检测器与常规监督方法进行比较。
4.2. Benchmarking settings|基准测试
对于48/17分割和65/15分割,我们都对ZSD和GZSD的性能进行了基准测试。在ZSD中,推理过程中只存在unseen text embeddings ,模型只预测未见物体实例。我们报告了在不同交并比(IOU)阈值下的mAP@0.5和Recall@100。在GZSD中,验证时同时存在已见和未见文本嵌入,模型预测已见和未见物体实例。在GZSD中,我们还报告了不同IOU阈值下已见和未见mAP@0.5及Recall@100的调和平均数(HM)。与之前的ZSD论文类似,除非另有说明,mAP始终指的是mAP@0.5。请注意,除非本节另有说明,我们的模型都使用了我们提出的自标记(3.3)、双重损失函数(3.4)和自定义后处理(3.5.2)。
4.3. Implementation Details|执行细节
我们的代码实现基于ultralytics提供的PyTorch YOLOv5仓库。在模型架构方面,我们只对最终的检测层进行了修改,对于损失函数,我们只根据第3节描述的方法改变了类别相关的损失。我们的主要损失函数超参数是:Wt为1.05,Wi为1.21,边界框损失权重为0.03,类别损失权重为0.469,对象性损失权重为2.69。我们的主要SGD优化器超参数是:基础学习率(lr)为0.00282,动量为0.854,权重衰减为0.00038。我们的模型在没有预热的情况下,按照50个周期的余弦调度进行训练,并使用第3.6节描述的预训练权重进行初始化。对于所有向量嵌入的生成,我们使用了公开可用的ViT-B/32模型。
4.4. Comparison With Previous SOTA
我们用48/17和65/15两种分割对比先前的零样本检测方法,以65/15分割作为主要基准,因其稀有性和多样性,在此分割上开发了所有方法。
4.4.1 零样本检测比较
表5. 我们在COCO数据集的两个分割上与之前最先进ZSD工作的比较。"已见/未见"指的是数据集的分割。我们的方法显著超越了其他所有工作。
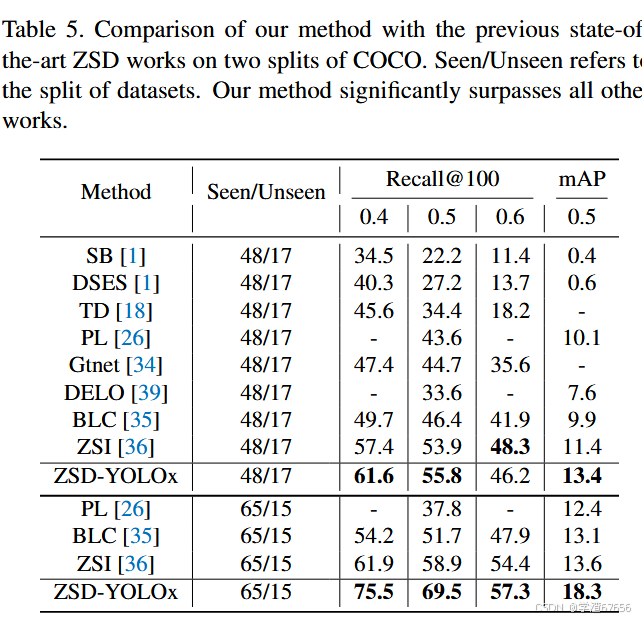
我们在表5中比较了零样本检测(ZSD)任务下的结果。我们观察到,在48/17数据集分割下,我们的方法比之前最先进的方法[36]提高了2.0 mAP,即提高了17.6%。在65/15分割下,我们的方法超过了之前得分最高的零样本检测方法[36] 4.7 mAP,或者说提高了约34.6%。我们的方法在65/15分割下显示出更显著的提升,主要是因为蒸馏过程受益于65/15分割中更多样化的标签集,并且我们所有的方法都是在65/15数据集分割下开发的。
4.4.2 广义零样本检测
- 表6. 该表展示了我们的方法和之前最先进技术在广义零样本检测(GZSD)任务上的Recall@100和mAP性能。HM表示已见和未见类别的调和平均值。
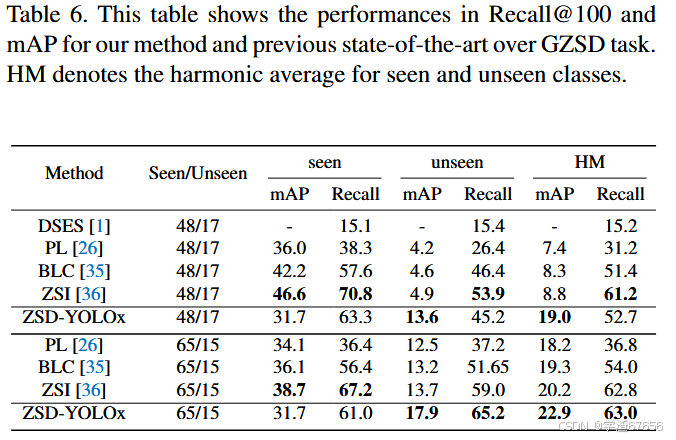
我们在表6中比较了GZSD任务的结果。在GZSD的设置下,我们的方法开发集中在未见类别的mAP(平均精度均值)和HM mAP(调和平均mAP)上,并且在这两个指标上以及在两个数据集分割中都超越了之前最先进的方法[36]。在48/17数据集分割中,我们的方法在未见类别的mAP上提高了8.7%,或者在HM mAP上提高了177.6%,以及在主要的GZSD基准HM mAP上提高了10.2%或者116.0%。在65/15数据集分割中,我们的方法在未见类别的mAP上提高了4.2,或者说提高了30.7%。对于调和平均(HM)mAP,我们的方法提高了2.7 mAP,或者说提高了13.4%。
4.4.3 Speed Benchmarking
- 表7. 比较我们的方法与之前最先进技术[36]在COCO数据集的65/15和48/17分割上的推理速度。模型速度是针对单个批次大小和由每个模型的GPU内存使用量决定的多个批次大小进行评估的。批次大小在第3列的括号内列出。由于列出的ZSD方法在不同分割间的推理时间差异可以忽略不计,所有速度评估都是在65/15数据集分割上进行的。由于3.3节中解释的原因,ZSD-YOLOl模型没有包含在我们的扩展实验中。
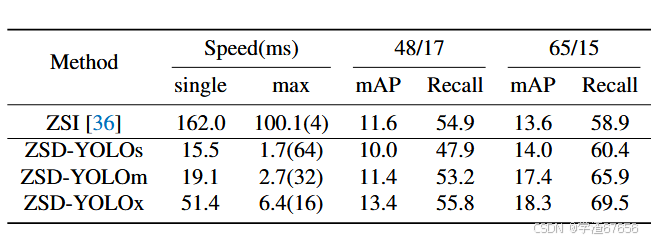
我们在表7中展示了我们的模型扩展结果,并与之前最先进的方法[36]进行了比较。在评估所有模型的推理速度时,我们只计算了模型产生批次输出所需的时间,这包括了我们模型的余弦相似度计算和带温度的softmax操作,但不包括如非极大值抑制(NMS)这样的后处理。
我们在单个V100 GPU上进行基准测试,批次大小为1,并根据每个模型的GPU内存使用情况进行缩放。与之前最先进的[36]相比,我们的最佳模型ZSDYOLOx在单张图片推理上快了3倍以上,同时mAP也提高了4.7。
此外,我们最小的模型规模在64的批次大小下平均推理时间为1.7毫秒,仍然在65/15分割上表现优于Zheng等人[36]。为了衡量相对模型性能,我们专注于48/17数据集分割,因为我们在65/15分割下开发的方法可能在特定数据集分割中对某些模型规模略有偏好,尽管我们仍然报告65/15的扩展结果作为参考。
在标准YOLOv5扩展中,YOLOv5m和YOLOv5x在mAP方面分别比YOLOV5s提高了13.9%和24.2%。相比之下,我们提出的ZSD-YOLOm和ZSD-YOLOx在mAP方面分别比ZSD-YOLOs提高了14.0%和34.0%。ZSD-YOLOx的更大提升可能归因于我们的方法主要是为了优化那个模型规模,因此我们的实验表明标准检测器的扩展可以很好地转移到我们的ZSD方法上。
4.5. Qualitative Results
- Figure 2. Selected examples of our results for zero shot detection produced by our ZSD-YOLOx model. Well detected images are in the top row while poorly detected images are displayed in the bottom row.图2. 展示了我们的ZSD-YOLOx模型产生的零样本检测结果的精选示例。检测效果好的图片位于顶行,而检测效果差的图片显示在底行。

我们在图2中展示了我们的零样本检测器在COCO 65/15测试数据集分割上的一些示例。我们发现我们提出的模型能够在各种情况下检测多样化的未见类别,并用精细的边界框标记它们。
左上角的图像展示了我们的模型即使在“熊”被草和阴影遮挡的情况下,也能为这个未见类别创建精细的边界框。中间顶部的图像揭示了我们的模型检测部分物体的能力,例如位于左下角的“马桶”。
最后,右上角的图像展示了我们的模型在嘈杂背景下区分多个相似和重叠的“火车”类别物体的能力。在检查我们模型在底部行显示的错误时,我们主要看到已见类别的误检问题,即被识别为未见类别。在底部行显示的图像中,我们看到“键盘”被检测为“鼠标”,“人”被检测为“滑雪板”,“狗”被检测为“熊”。进一步的研究将需要更好地过滤掉不在给定嵌入集中的物体,以避免被检测到。
5. 结论
我们介绍了ZSD-YOLO,这是一个零样本检测器,它在利用COCO[19]数据集的两个主要零样本检测设置上超越了之前所有的零样本检测结果。此外,我们设计了一种自标记方法,可以在不需要新数据或标签的情况下提高零样本检测的性能。
我们探索了traditional scaling approaches对零样本检测任务的影响,并发现typical model scaling可以很好地应用到我们的架构中,从而创建一系列高效准确的零样本检测器。零样本检测是一个新兴的研究方向,在计算机视觉领域有很多潜在的应用,未来可能会出现"Generalized object detector"(广义物体检测器)。我们希望我们的工作能够建立一个强大的零样本检测基线,利用图像和文本loss组成部分来激发关键零样本检测领域的进一步研究。


















 3144
3144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









