






一、简介
Protocol Buffers,是Google公司开发的一种数据描述语言,类似于XML能够将结构化数据序列化,是一种轻便高效的结构化数据存储格式,它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
它不依赖于语言和平台并且可扩展性极强。现阶段官方支持C++、JAVA、Python、Objective C、C#、Ruby、PHP、JavaScript八种编程语言,还可以找到大量的几乎涵盖所有语言的第三方拓展包。
通过它,你可以定义你的数据的结构,并生成基于各种语言的代码。这些你定义的数据流可以轻松地在传递并不破坏你已有的程序。并且你也可以更新这些数据而现有的程序也不会受到任何的影响。
Protocol Buffers经常被简称为protobuf。
二、protobuf的优缺点
参考: https://www.cnblogs.com/miaochuanjie/p/17434551.html
2.1、优点
- 性能高效:与XML相比,protobuf更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。序列化速度快。传输速度快。
- 语言无关、平台无关:protobuf支持Java、C++、Python 等多种语言,支持多个平台。
- 扩展性、兼容性强:只需要使用protobuf对结构数据进行一次描述,即可从各种数据流中读取结构数据,更新数据结构时不会破坏原有的程序。
- 使用方面:
- 使用简单,
proto编译器自动进行序列化和反序列化。 - 维护成本低:对平台只要维护一套对象协议文件,即
xx.proto文件。 - 可扩展性好:不必破坏旧的数据格式,就能对数据结构进行更新。
- 加密性好:
http传输内容抓包只能抓到字节数据。
- 使用简单,
2.2、缺点
- 不适合用来对基于文本的标记文档(如 HTML)建模。
- 自解释性较差,数据存储格式为二进制,需要通过proto文件才能了解到内部的数据结构。
三、编译
protoc就是protobuf的编译器,它把proto文件编译成不同的语言
下载:Releases · protocolbuffers/protobuf · GitHub
四、protobuf语法
参考:
https://www.cnblogs.com/miaochuanjie/p/17434551.html
4.1 基本规范
- 文件以.proto做为文件后缀,除结构定义外的语句以分号结尾
- 结构定义可以包含:message、service、enum
- rpc方法定义结尾的分号可有可无
- Message命名采用驼峰命名方式,字段命名采用小写字母加下划线分隔方式
- Enums类型名采用驼峰命名方式,字段命名采用大写字母加下划线分隔方式
- Service与rpc方法名统一采用驼峰式命名
4.2 字段规则
- 字段格式:
限定修饰符 | 数据类型 | 字段名称 | = | 字段编码值 | [字段默认值] - 限定修饰符包含 required\optional\repeated
- Required: 表示是一个必须字段,必须相对于发送方,在发送消息之前必须设置该字段的值,对于接收方,必须能够识别该字段的意思。发送之前没有设置required字段或者无法识别required字段都会引发编解码异常,导致消息被丢弃
- Optional:表示是一个可选字段,可选对于发送方,在发送消息时,可以有选择性的设置或者不设置该字段的值。对于接收方,如果能够识别可选字段就进行相应的处理,如果无法识别,则忽略该字段,消息中的其它字段正常处理。---因为optional字段的特性,很多接口在升级版本中都把后来添加的字段都统一的设置为optional字段,这样老的版本无需升级程序也可以正常的与新的软件进行通信,只不过新的字段无法识别而已,因为并不是每个节点都需要新的功能,因此可以做到按需升级和平滑过渡
- Repeated:表示该字段可以包含0~N个元素。其特性和optional一样,但是每一次可以包含多个值。可以看作是在传递一个数组的值
-
singular:singular 表示该字段数量可以是 0 或者 1 个。该限制符不需定义,默认就是 singular 类型。
-
在proto3中,去掉了required和optional,对于原始数据类型字段不再提供 hasxxx()方法,只有单个字段或者重复字段。
- 数据类型
- Protobuf定义了一套基本数据类型。几乎都可以映射到C++\Java等语言的基础数据类型
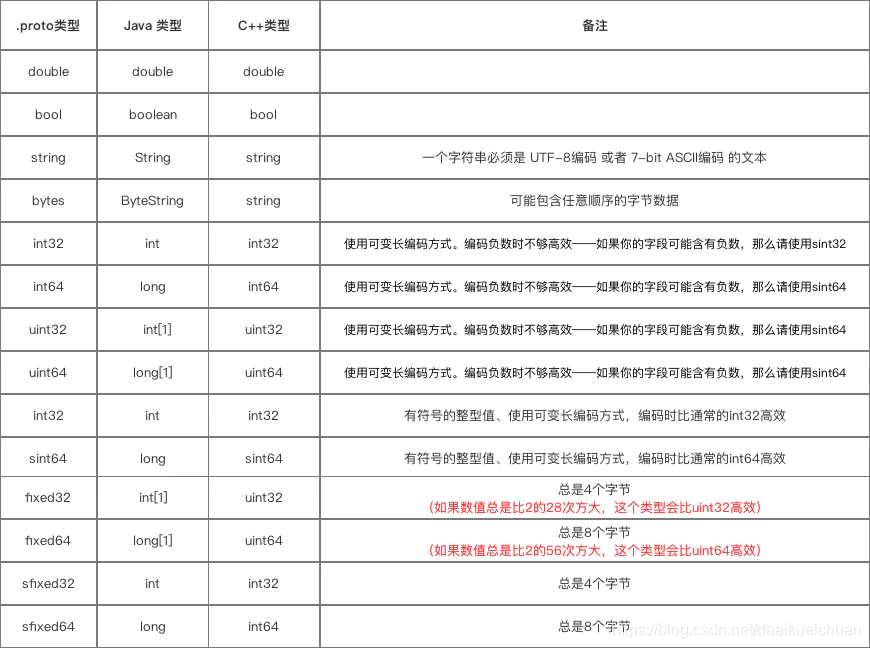
- N 表示打包的字节并不是固定。而是根据数据的大小或者长度
- 关于 fixed32 和int32的区别。fixed32的打包效率比int32的效率高,但是使用的空间一般比int32多。因此一个属于时间效率高,一个属于空间效率高
- Protobuf定义了一套基本数据类型。几乎都可以映射到C++\Java等语言的基础数据类型
- 字段名称
- 字段名称的命名与C、C++、Java等语言的变量命名方式几乎是相同的
- protobuf建议字段的命名采用以下划线分割的驼峰式。例如 first_name 而不是firstName
- 字段编码值
- 有了该值,通信双方才能互相识别对方的字段,相同的编码值,其限定修饰符和数据类型必须相同,编码值的取值范围为
1~2^32(4294967296) - 其中 1~15的编码时间和空间效率都是最高的,编码值越大,其编码的时间和空间效率就越低,所以建议把经常要传递的值把其字段编码设置为1-15之间的值
- 1900~2000编码值为Google protobuf 系统内部保留值,建议不要在自己的项目中使用
- 有了该值,通信双方才能互相识别对方的字段,相同的编码值,其限定修饰符和数据类型必须相同,编码值的取值范围为
- 字段默认值
- 当在传递数据时,对于required数据类型,如果用户没有设置值,则使用默认值传递到对端
4.3 关键字
- syntax 用于指定协议版本号,没有指定则默认为 proto2 版本。
- package 相等于 C++ 中的命名空间,为.proto文件添加package声明符,可以防止不同 .proto项目间消息类型的命名发生冲突。。
- import 引入其他的 proto 文件,可以使用其他 proto 文件中定义的消息类型。
- message 用于定义消息类型,相当于 C++ 中的 struct。
- enum 用于定义枚举类型,相当于 C++ 中的 enum
4.4 message
message用于定义结构数据,可以包含多种类型字段(field),每个字段声明以分号结尾。message经过protoc编译后会生成对应的class类,field则会生成对应的方法。
多个消息类型
一个.proto文件中可以定义多个消息类型,一般用于同时定义多个相关的消息,例如在同一个.proto文件中同时定义搜索请求和响应消息
syntax = "proto3";
// SearchRequest 搜索请求
message SearchRequest {
string query = 1; // 查询字符串
int32 page_number = 2; // 页码
int32 result_per_page = 3; // 每页条数
}
// SearchResponse 搜索响应
message SearchResponse {
...
}
嵌套消息类型
在单个.proto文件中可以定义多个消息体
- 支持嵌套消息,消息可以包含另一个消息作为其字段。也可以在消息内定义一个新的消息
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}- 内部声明的消息message名称只可在内部直接使用,在外部使用需要添加父级message名称(Parent.Type):
message SomeOtherMessage {
SearchResponse.Result result = 1;
}
- 另外,还可以多层嵌套
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Level 1
message Inner { // Level 2
int32 ival = 1;
bool booly = 2;
}
}
}更新消息类型
如果一个已有的消息类型已无法满足新的需求,比如需要添加一个额外的字段,但是同时旧版本写的代码仍然可用。在更新消息类型需要遵循以下规则:
- 不要更改任何已有字段的标识号。
- int32、uint32、int64、uint64,和bool是全部兼容的,这意味着可以将这些类型中的一个转换为另外一个,而不会破坏向前、 向后的兼容性。
- sint32和sint64是互相兼容的,但是它们与其他整数类型不兼容。
- string和bytes是兼容的,只要bytes是有效的UTF-8编码。
- 嵌套消息与bytes是兼容的,只要bytes包含该消息的一个编码过的版本。
- fixed32与sfixed32是兼容的,fixed64与sfixed64是兼容的。
4.5 枚举(Enum)
定义
proto3语法支持我们自己定义枚举类型,枚举类型在.proto文件中的编写规范如下:
- 枚举类型名称:使用驼峰命名法,首字母大写。例如:
MyEnum - 常量值名称:全大写字母,多个字母之间使用
_连接,例如:ENUM_CONST = 0; -
需要注意枚举类型的定义有以下规则:
-
枚举类型中第一个元素的值必须从0开始,而且proto3中删除了default标记,默认值为第一个元素。
-
当枚举类型是在某一个消息内部定义,但是希望在另一个消息中使用时,需要采用MessageType.EnumType的语法格式。
-
枚举的常量值在 32 位整数的范围内。但因负值无效因而不建议使用(与编码规则有关)
-
注意
将两个 具有相同枚举值名称 的枚举类型放在单个.proto?文件下测试时,编译后会报错:某某某常量已经被定义!所以这里要注意:
- 同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
- 单个.proto文件下,最外层枚举类型和嵌套枚举类型,不算同级。
- 多个.proto文件下,若⼀个文件引入了其他文件,且每个文件都未声明 package,每个.proto文件中的枚举类型都在最外层,也算同级。
- 多个.proto文件下,若⼀个文件引入了其他文件,且每个文件都声明了package,不算同级。
// ---------------------- 情况1:同级枚举类型包含相同枚举值名称--------------------
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
enum PhoneTypeCopy {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
}
// ---------------------- 情况2:不同级枚举类型包含相同枚举值名称-------------------
enum PhoneTypeCopy {
MP = 0; // 移动电话 // ⽤法正确
}
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
}
// ---------------------- 情况3:多⽂件下都未声明package--------------------
// phone1.proto
import "phone1.proto"
enum PhoneType {
MP = 0; // 移动电话 // 编译后报错:MP 已经定义
TEL = 1; // 固定电话
}
// phone2.proto
enum PhoneTypeCopy {
MP = 0; // 移动电话
}
// ---------------------- 情况4:多⽂件下都声明了package--------------------
// phone1.proto
import "phone1.proto"
package phone1;
enum PhoneType {
MP = 0; // 移动电话 // ⽤法正确
TEL = 1; // 固定电话
}
// phone2.proto
package phone2;
enum PhoneTypeCopy {
MP = 0; // 移动电话
}

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









