







目录
0.0、摆烂了好几天
这一节写了好久,关于这些被层层封装的基础知识,我也是一知半解。我又不想大段大段的使用书上的原话,所以消化了好长时间。而且就算揣摩了这么长时间,也还是没有写得让我自己满意。怎奈实力有限,或许这次有了感悟大约要下次才能发挥出来,所以各位大佬,且看且指教。
2.1、信息存储
本节最关键的是分清物理内存、虚拟内存,与之对应的还有地址、虚拟地址等如下表
| 物理内存 | 虚拟内存 |
| 物理地址 | 虚拟地址 |
| 物理内存大小 | 虚拟地址空间 |
| 硬件 | 操作系统 |
这些概念互有关系但不是依依对应的。
物理内存是实际的硬件,其物理内存大小是由硬件来决定,物理地址的唯一数字标识,也是由其硬件决定的。也就是说,其物理地址所标识的电子存储区域和电子存储区域的大小是会随着硬件厂家和型号改变的。
而虚拟内存是操作系统抽象出来的一片内存区域,其使用的虚拟地址会由操作系统对应到实际的物理地址。而且虚拟地址空间是一定的,也就是说,在同一个操作系统下,无论如何更换硬件,其虚拟内存空间的大小和虚拟地址所指向的虚拟内存位置是不会改变的。
这就引发了一个问题,既然物理内存大小是不确定的,那么为什么虚拟地址空间确实固定的呢。所以虚拟地址空间中的虚拟地址,不一定全部都有对应的物理地址。所以虚拟内存空间的定义是,所有可能的物理地址的集合。既然说到地址,那就不得不提一下指针了。众说周知,指针保存的是地址,那么这个地址是物理地址还是虚拟地址2.2呢?答案是虚拟地址.
2.1.1、十六进制表示法
这个太基础了就不过多解释了,这里主要说一些小技巧。
*牢记:0xA = 10、0xC = 12、0xF = 15。则0xB = 0xA + 1、0xD = 0xC + 1、0xE = 0xF - 1。为什么记ACF而不是计BDE?因为AF是平时经常会用到的,而C是取得一个中间数。0xF = 15、0xF = 15、0xF = 15。重要的事情说三遍。
*0B0001 = 1、0B0010 = 2、0B0100 = 4、0B1000 = 8。记住这这四位的十进制数,转化十六进制时将这四位的值相加就可以了。
*反过来十六进制转二进制就可以减8减4减2减1,够减就在对应位上计1,不够减就计0。
*然后是十六进制、二进制转十进制,这个就用计算器吧,就算掌握了方法也很费纸。
2.1.2、字数据大小
字长前面也说过,它于操作系统和硬件系统息息相关。而其实际用途是指明指明指针数据的标称大小。时至今日,市面上主流计算机包括但不限于个人电脑、笔记本、智能手机等通用型设备都已经全面升级为64位字长。而智能家电、计算机外部设备、部分嵌入式设备也都升级到了32位字长。然而随着科技的进步,未来的未来,字长一定会再次升级。作为一名有理想有追求的程序员,一定希望自己设计的程序流芳百世(可移植)。所以,了解字长对计算机系统以及程序设计的影响,是至关重要的。
字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说字节越大,能表示的最大虚拟地址空间越大。这个地址空间有多大呢?就等于0~(2的字长次方 - 1)。也就是32位系统约等于4GB,而64位系统约等于16EB约等于1700亿GB。当然目前个人计算机还用不到这么大的虚拟内存,但是在动则1~2GB,多则8GB的3D游戏面前,4GB的虚拟内存显然不够用,需要增加寻址范围。回忆一下虚拟内存的分布,如下图
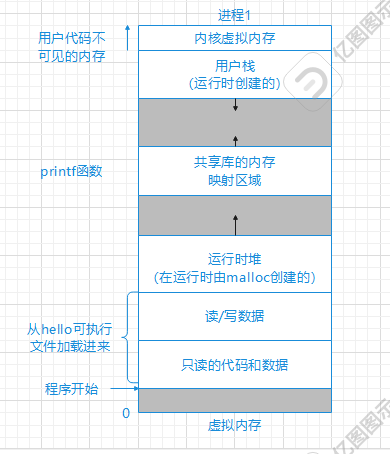
从图中可以看出,无论是使用32位系统,还是64位系统,用户的只读代码和数据,读/写数据、运行时堆的虚拟地址范围是相差不大的。但是,共享库的内存映射区、用户栈、内核虚拟内存,在不同的系统中的虚拟地址范围可能大相径庭。那么这于设计可移植的程序有什么关系呢?
要回答这个问题就不得不先来看看程序编译的一些特性了。相同的程序使用不同的字长编译方式所得到的机械码也是不同的。在以目标为32位机型和64位机型进行编译时,数据类型所占字节数会有如下差异。
| C语言类型 | 字节数 | ||
| 有符号 | 无符号 | 32位 | 64位 |
| long | unsigned long | 4 | 8 |
| char * | 4 | 8 | |
表中char * 为指针类型,其字节数跟随编译指定的机型的字长的字节数相同。指针类型本就是用来存放指针变量,这样设计我想不会有什么异议。
而long、unsigned long这两个类型的字节数也与编译指定的机型的字长的字节数相同,其设计目的是为了兼顾存储和运算。因为在32位机型中计算8字节的数据比计算4字节数据需要更多的步骤和消耗,而在64位系统中就不存在这个问题,且字节数会随字长切换以增减其占用空间大小,毕竟字长越大的系统,存储空间也就越大。根据这个特性,就很容易推断出 long/unsigned long 类型的应用场景了。它适合于与系统字长成正比例变化的数据类型,很可惜到目前为止我都没有碰到过这种类型,这也说明该类型不适合在日常应用级的开发。当然这只是在C语言中的情况,在其他语言中如Java中该类型固定为8字节。
在这里再次强调一次,程序的字长是由编译时选择的目标机型决定的。这就引发了一个很古老的问题——使用 int 类型存储指针变量。int 类型编译后的字节数与 指针类型对比如下表
| C语言类型 | 字节数 | ||
| 有符号 | 无符号 | 32位 | 64位 |
| int | unsigned | 4 | 4 |
| char * | 4 | 8 | |
在还没有64位设备时期,前辈们可能会使用 int 类型来存放指针变量。这在当时的所有系统中都是没有问题的。后来到了64位设备的时代,也就是现在。指针由原来的4个字节,变为了8个字节。int 类型就会有溢出的情况。在这种情况下共享库的内存映射区、用户栈、内核虚拟内存这几个区域的绝大多数情况之下是访问不到的。这就会发生运行时错误。当然这也仅仅只会发生在将这样的C程序编译成64位程序时,因为64位系统在运行32位程序时会为其分配4GB的内存虚拟空间的兼容环境。但是不要忘了,我们读本书的目的,就是要去写中间层,造福千万家。根据墨菲定律,如果没有注意到这个问题,只要使用这段程序的够多,这个运行时错误就一定会发生。如果你说“我的程序我自己知道就行了,我也不想给别人用”,那么这本书不适合你,出门左拐,AI开发比这个狂追酷炫吊炸天多了。
2.1.3、寻址和字节顺序
这里要提前了解一个程序对象的概念,程序对象指的是将一个或多个字节看作一个整体(对象),对其进行操作。如上表中的数据类型皆为程序对象,他们分别占有4个或8个字节。而这多个字节在内存中是连续存储的字节序。而这个对象的内存地址就是这个对象的第一个字节的内存地址。
除了程序对象在内存中的位置,还有一个很重要的概念,就是程序对象在这段内存中是如何排列的,也就是令人头秃的大小端序。在通信编程中经常会看到技术文档中有“大端序”、“小端序”的描述。虽然可以在要用到的时候上网查,但是在通信编程这种经常用到的领域,熟记它的规则会更有效率。那么巧妙记忆这个规则的方法,如下图。
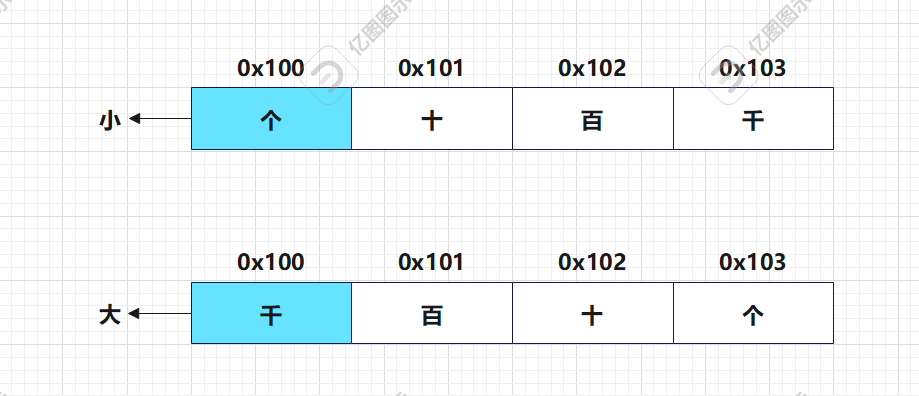
过多不说,记住口诀“个小千大”。书上又是“int”又是“十六进制”的虽然准确但是不方便记忆。我们只需要记住他的原则,数据类型和进制可以随意切换,才是一通百通的好方法。这里提醒初学者一点,上图不完全符合实际,只是方便联想记忆的模拟模型,将不重要的信息隐藏了起来,将重要的信息凸显出,这像是不是很像抽象?
为什么计算机的程序对象的存储方式会有大小端的差异呢?因为位是从大到小排序的,可以理解为大端序,所以使用大端序有存储连续性优势。而在大于字长的CPU计算时,需要从低字节计算到高字节,使用大端序会需要频繁跳转到程序对象的最后一个字节,导致性能的开销。总结:大端序适合存储与传输;小端序适合交给CPU进行计算,各有其适合的使用场景。这也很像人类书写时先写高位而计算时先算地位的方式,其没有优略,只有是否适合其使用场景。
平时尤其要注意网络传输、反汇编、强制类型转换&联合的时候的大小端序,因为他们都脱离了原系统对程序对象的解释。比如:
*网络传输,只能传输字节,在未特意设计的情况下,并不能知晓对方系统的大小段序,而在对程序对象进行打包时,从应用层层面是看不出程序对象是大端序还是小端序的。
*反汇编,将阅读机器级程序,机器程序中没有程序对象的概念,数据回以十六进制的形式暴露给开发人员。此时若不知道其是大端序还是小端序,就会极有可能导致阅读错误。
*强制类型转换&联合,会改变原程序对象的规则,所以一定要对改变前后完全了解,字节序就是其中之一。比如将32位的”0x12345678“转换为16位,在大端程序中是0x1234,在小端序中则是0x7856。
虽说字节序的问题不是每天都会遇到,但是作为有理想有最求的程序员,应当知道它的原理,在位数不多的遇见因它产生的BUG时候,要有这么一个职业直觉,先感应到可能是它的问题并求证解决。
2.1.4、表示字符串
字符串比较通用,不存在字节序问题,只需要注意一点,就是字符串以0x00结尾。
还有一些小技巧,如数字'x' = 0x3x、'a' = 0x61、'A' = 0x41。
这里要注意,在C语言中'a'和"a"是不同的,'a'是字符在内存中为【0x61】,而 "a"是字符串在内存中为【0x61 0x00】。
2.1.5、表示代码
借用书上的例子,如下C函数
int sum(int x, int y)
{
return x + y;
}在实例机器上编译时,生成如下字节表示的机器代码:
Linux 32 55 89 e5 8b 45 0c 03 45 08 c9 c3
Windows 55 89 e5 8b 45 0c 03 45 08 5b c3
Sun 81 c3 e0 08 90 02 00 09
Linux 64 55 48 89 e5 89 7d fc 89 75 f8 03 45 fc c9 c3
可以看出机器代码是不具备跨平台特性的,所以C语言在系统级编程的跨平台特性来源于其完善的语言生态。如
*GCC编译器支持将C语言编译成各种不同平台使用的机器代码;
*标准库提供丰富实用的轮子;
*操作系统提供统一的接口和运行环境;
*嵌入式系统提供统一的硬件访问接口。
...
这么多的耕耘,才换来C语言在系统级编程的跨平台特性,所以我们也应当更了解我们所在的生态,才能为我们所在的生态做出贡献,使我们所在的生态能够稳定可持续发展。
2.1.6、布尔代数简介
布尔代数只有真和假,也表示为1和0,在计算机中正好可以用一个位(bit)来表示。而其预算与普通代数也完全不同,分别有与、或、非、异或,具体如下表。
| 运算 | 与 | 或 | 非 | 异或 |
| 英文 | AND | OR | NOT | XOR |
| 符号 | & | | | ~ | ^ |
| 命题逻辑符号 | ∧ | ∨ | ¬ | ⊕ |
| 说明 | 同1则1,否则0 | 有1则1 ,否则0 | 0则1,1则0 | 相同则1,不同则0 |
由于布尔代数是研究真假的代数,所以在判断语句中用的最多。而其只有1和0两个值,在以字节为最小操作单位的计算机系统中,如果一个字节只用来表示一个布尔值,则会浪费掉8分之7的空间。这也是扩展位向量运算的原因之一。
什么是位向量?位很好理解,而向量就是有长度和方向的量,可以理解为将几个不同的量合并成一个向量,计算时分别计算各个量,表达时统一表达为向量;或者理解为将一个量分解成几个与之相关的几个量,未分解前的量则为向量,计算时分别计算分解后的量,计算完后再合并成一个向量量。所以向量不止运用与物理领域,只要是将几个量看作一个对象或将一个对象分解为几个量,运算时分别计算几个量,这个对象就叫向量。也叫做有序的数值序列,其一定是有序的且有多个数值。如:向量A + 向量B = (A1 + B1) 运算 (A2 + B2) = 向量C。然后来看位向量,就是将几个位合并成一个向量,计算时每个位分别计算 。向量运算在线性代数中也很常见,所以向量是早期物理学对有序的数值序列的叫法。而如今诸多领域中,在不考虑物理学时,将向量叫做有序的数值序列更为贴切。
2.1.7、C语言中的位级运算
准确来说是C语言中的位级逻辑运算。并没什么好说的,非常常用且简单。只需要记得,计算时将任意进制的数转换为二进制,计算完后再还原成对应进制就可以了。还有几个衍生概念如下
*每个元素都是它自身的加法逆元(a ^ a = 0)
*位级运算的一个常见用法就是实现掩码运算,所谓掩码,就是只看想看的部分,将想看的地方设置成1,其他地方设置成0,在于所要观察的数据进行 & 操作,就可以频闭掉无关数据。无关数据可能属于其他层级或模块等,使用掩码提取出本单元需要的数据后,可以很方便的做对比、计算等操作。
2.1.8、C语言中的逻辑运算
这里的逻辑运算与位逻辑运算不同,它不是一个向量(有序数值序列),而是无论任何数据类型,无论所占用字节数。其整体为0则为0(false),其他情况全为1(true),比如0x00为0(false)、0x01到0xFF为1(true)。其运算符有&&、||、!,前两个很好理解是与和或,最后一个是非,又称作取反,与“=”同用“!=”表示不等于。所以有"if(!x)"的用法,其意为如果x不等于0。需要注意的是,逻辑运算符还有很多如上例中的简写,如“a&&5/a”本写法表示当a不等于0时5除以a。利用了逻辑运算得到一个true的答案后就不会在继续后续计算的特性,避免了除数为0的错误运算。但是更好的写法还是展开来写清楚意图,如 "a != 0 ? 5/a : 0"。当然还可以写做“if(a != 0) 5/a”。以上是伪代码,主要是理解其思想。写代码需要以清晰为主,不使用刁钻的特性也可以更好的向下兼容。毕竟不能保证每个使用这段代码的人都能知道这个特性,且跨平台与版本更迭也不一定尊崇这个特性。所以从长远来看,简单通用才是最重要的,不然自己踩到自己的雷才是有苦难言了。
2.1.9、C语言中的位移运算
位移运算就更加简单了,“<<”是左移、“>>”右移。需要注意的是右移时分为逻辑右移和算数右移,在算数右移时,其首位为1时填充1,首位为0时填充0。具体为什么,这与有符号的整数有关,需要用到补码的知识后面会涉及到。
关于这几个运算的小节其实没有什么过多的东西可以说,更重要的是做做练习题,在练习题中去感受数学的巧妙——“居然还可以这样”奇妙幸喜。书上讲解的篇幅也比练习题的篇幅还要少,数学的事本来就没有什么好讨论的,算得出来就算得出来,算不出来就算不出来,没有啥讨价还价的余地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









