




 本文通过生产者消费者模式介绍Golang中chan的使用。涵盖无缓冲与带缓冲通道区别、for select是否耗CPU等前置知识,还详细阐述一对一、一对多、多对一、多对多四种生产消费场景的实现及注意事项,如避免死锁、线程安全等。
本文通过生产者消费者模式介绍Golang中chan的使用。涵盖无缓冲与带缓冲通道区别、for select是否耗CPU等前置知识,还详细阐述一对一、一对多、多对一、多对多四种生产消费场景的实现及注意事项,如避免死锁、线程安全等。
文章目录
代码地址:https://gitee.com/lymgoforIT/golang-trick/tree/master/28-producer-consumer
一、简介
channel是Go语言中一个很重要的特性,应用在众多的工作场景中,但是万变不离其宗,不外乎生产和消费。本文我们就是通过生产者消费者模式来了解channel在实际使用时都有哪些坑,以及如何规避这些坑,让我们在使用channel的过程中更加有底气,程序更加健壮。
主要知识点:
channel的特点和关闭原则- 不同的生产消费场景
channel该如何关闭 - 生产者消费者四种场景的具体实现(一对一、一对多、多对一、多对多)
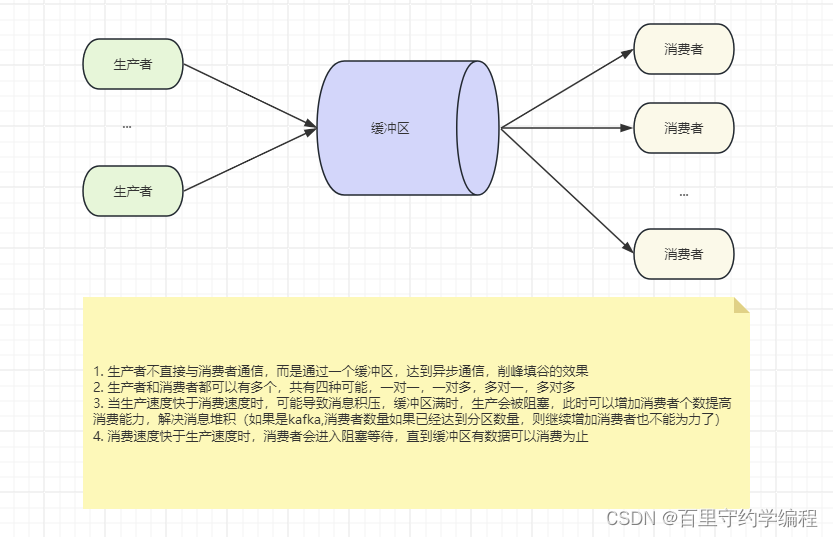
本文主要是想介绍channel在使用过程中的注意事项,所以不会有辅助业务场景逻辑(消息内容不复杂,不是JSON等结构),只会简单的生产数字和消费数字
二、前置工具代码:out.go 用于接收值,往控制台输出
1、本小节知识点总结
- 协程启动需要一定时间,主程序退出后,子协程也会跟着消亡
- 无缓冲通道与带缓冲通道以及
make(chan interface{})和make(chan interface{},1)的区别 for select机制,for不会一直循环消耗CPU,select执行一次,for才会执行一次。select{}会无限阻塞流程
-for range遍历channel机制signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)控制程序退出时机
2、无缓冲通道与带缓冲通道
目录结构很简单,如下;
- 首先,我们定义了一个
Out结构体作为缓冲区,缓冲区只需要有一个,所以用once实现了单例模式 - 然后我们提供了往缓冲区写消息的函数,以及从缓冲区消费消息的方法,并将消费到的消息打印到控制台
package out
import (
"fmt"
"sync"
)
// 定义一个缓冲区结构体
type Out struct {
data chan interface{}
}
// 缓冲区应该是唯一的,所以做成单例
var out *Out
var once sync.Once
// 在 NewOut 函数中,我们使用 once.Do 方法来执行一个初始化单例对象。
// 由于 once.Do 方法是基于原子操作实现的,因此可以保证并发安全,即使有多个协程同时调用 NewOut 函数,最终也只会创建一个对象。
// 因为once变量可以保证它的Do方法只被执行一次
func NewOut() *Out {
once.Do(func() {
out = &Out{data: make(chan interface{})}
})
return out
}
// 往缓存取写入消息的方法
func Println(i interface{}) {
out.data <- i
}
// 消费消息,将消费到的消息输出到控制台
func (o *Out) OutPut() {
for {
select {
case i := <-o.data:
fmt.Println(i)
}
}
}
测试:
package main
import "golang-trick/28-producer-consumer/out"
func main(){
o := out.NewOut()
go o.OutPut()
out.Println(1)
out.Println(2)
out.Println(3)
out.Println(4)
out.Println(5)
out.Println(6)
}
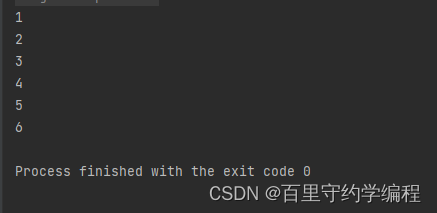
按照我们的惯有思维,上述main函数执行后,在控制台应该看不到输出,因为开启go协程需要一定的时间,而main方法执行结束后,子协程也会跟着消亡,也就是我们可能会以为o.OutPut()方法可能根本就没有机会执行,因此看不到输出,但实际执行结果如下,,在控制台看到了完整的输出:
这是为什么呢?原因就是我们将作为缓冲区的channel在初始化时,赋值的是一个无缓冲通道,对于无缓冲通道,往里写值后,是会阻塞的,直到有其他协程将该值取走。同样,从无缓冲通道取值也会一直阻塞,直到可以取出值为止。 看下面代码中的注释
func NewOut() *Out {
once.Do(func() {
// 这里的data赋值了一个无缓冲通道
out = &Out{data: make(chan interface{})}
})
return out
}
所以out包中的Println函数里面的代码 out.data <- i 会阻塞,等到有其他协程从out.data中就值取走为止,相当于我们的代码实现了同步通信机制,并不是异步通信。
当我们将无缓冲区通道改为带缓冲的后,再次执行main函数,就确实看不到任何输出啦。
func NewOut() *Out {
once.Do(func() {
// 这里的data赋值了一个带缓冲通道
out = &Out{data: make(chan interface{},65535)}
})
return out
}
ps:工作中还有注意 make(chan interface{})和 make(chan interface{},1)的区别哦,他们就是无缓冲和有缓冲的区别,无缓冲的是放入一个值后不取走会立马阻塞的,带一个缓冲的则放入一个值后并不会阻塞,除非第一个值还没有被取走的时候,又想放里面放第二个值,此时会阻塞。
3、 for select 会无限循环耗费CPU吗?
for select在日常工作中,是一个非常常见的代码结构,一般用户多路监听,以及超时退出等。那么 ,当select没有任何一路case有事件时,会无限的for循环嘛?答案是不会的。我们将代码稍加改造如下,改造点请看注释,注释以改造开头
首先为了避免主程序退出,我们对main函数做了改造,让其只有在我们操作kill命令时才终止程序
package main
import (
"golang-trick/28-producer-consumer/out"
"os"
"os/signal"
"syscall"
)
func main() {
o := out.NewOut()
go o.OutPut()
out.Println(1)
out.Println(2)
out.Println(3)
out.Println(4)
out.Println(5)
out.Println(6)
// 改造
sig := make(chan os.Signal)
// kill 默认会发送 syscall.SIGTERM 信号
// kill -2 发送 syscall.SIGINT 信号,我们常用的Ctrl+C就是触发系统SIGINT信号
// kill -9 发送 syscall.SIGKILL 信号,但是不能被捕获,所以不需要添加它
// signal.Notify把收到的 syscall.SIGINT或syscall.SIGTERM 信号转发给给定的通道sig
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM) // 此处不会阻塞
<-sig // 阻塞在此,当接收到上述两种信号时才会往下执行
}
此外就是消费的代码,我们在select外层,但还在for范围内加一行打印输出
// 消费消息,将消费到的消息输出到控制台
func (o *Out) OutPut() {
for {
select {
case i := <-o.data:
fmt.Println(i)
}
// 改造
fmt.Println("out put")
}
}
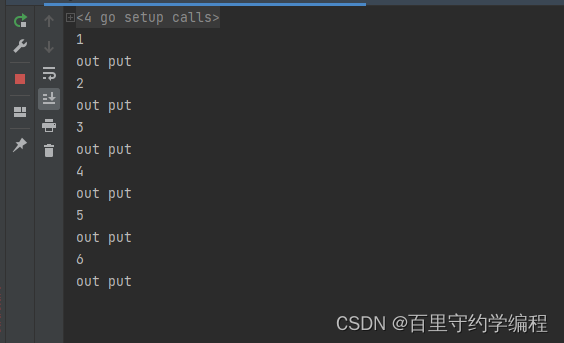
可以看到,只有在select每执行一次后,for才会循环一次,且主程序在等待我们的kill命令才会结束。
注意:select {}会永久阻塞,如下
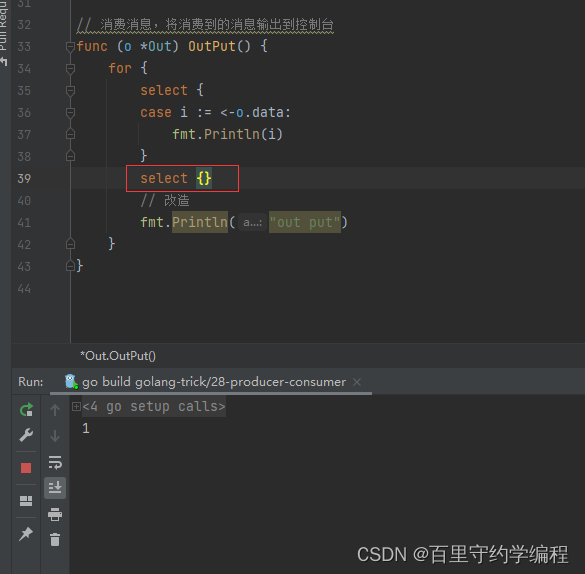
最后,本示例中可以使用for range替换掉for select ,for range 遍历通道,有值则遍历,无值则等待,通道被关闭后,也会将通道内所有值都消费完后,再自动退出for range循环
// 消费消息,将消费到的消息输出到控制台
func (o *Out) OutPut() {
for val := range o.data {
fmt.Println(val)
}
//for {
// select {
// case i := <-o.data:
// fmt.Println(i)
// }
//
// // 改造
// fmt.Println("out put")
//}
}
三、生产消费模式之一对一
1、本小节知识点总结
sync.WaitGroup传递时需要传递指针,而非值对象,否则会导致死锁sync.WaitGroup Add方法应该在协程外面使用- 生产完毕后,需要记得使用
close关闭通道,否则可能导致死锁,以为消费者的for range会一直在等待消费
2、one-one模式
代码如下:注释写的很详细也很重要,需要好好看哦
package one_one
import "golang-trick/28-producer-consumer/out"
// 为了方便,生产者生产任务,实际就是生产了一个ID,放到缓冲区中
// 消费者消费任务,打印Task中的ID。
// 实际工作中,生产者一般是生产一个JSON数据,消费者消费到JSON数据后进行自己的业务逻辑
// 这里为了演示,所以就定义了Task,直接往缓冲区中放入Task,这样消费者取出Task后,直接执行Task的run方法就当做是执行业务逻辑了
type Task struct {
ID int64
}
func (t *Task) run() {
// 使用到了我们out工具包中的方法模拟业务逻辑,实际其实跟直接使用fmt.Println效果一样,都是往控制台打印一下输出
// 不过是本次就是想学习生产消费模式,而这个out工具包其实也是一个简单的生产消费模式,所以用它
out.Println(t.ID)
}
// 定义缓冲区,大小为10,元素类型为Task
var taskCh = make(chan Task, 10)
// 定义需要发送的任务数量(实际工作中生产者不会断生产,消费者会一直消费)
// 这里定义能生产的数量,是为了演示后面通道关闭需要注意的很多细节
const taskNum int64 = 10000
// 生产 wCh:write chan
func producer(wCh chan<- Task) {
var i int64
for i = 1; i <= taskNum; i++ {
t := Task{
ID: i,
}
wCh <- t
}
// 生产完毕之后,可以关闭通道
close(wCh)
}
// 消费 rCh: read chan
func consumer(rCh <-chan Task) {
for t := range rCh {
if t.ID != 0 {
t.run()
}
}
}
// 启动执行
func Exec() {
go producer(taskCh)
go consumer(taskCh)
}
执行
package main
import (
"golang-trick/28-producer-consumer/one_one"
"golang-trick/28-producer-consumer/out"
"os"
"os/signal"
"syscall"
)
func main() {
o := out.NewOut()
go o.OutPut() // 用于打印输出到控制台
one_one.Exec() // one-one的生产和消费都在Exec中通过协程启动
sig := make(chan os.Signal)
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM) // 此处不会阻塞
<-sig // 阻塞在此,当接收到上述两种信号时才会往下执行
}
运行后可以看到输出了1-10000,但是我们并不知道生产和消费的两个协程是否都正常退出了呢?这时候介绍一个sync.WaitGroup组件,改造Exec方法如下:
// 启动执行
func Exec() {
wg := sync.WaitGroup{}
wg.Add(2)
go func() {
defer wg.Done()
producer(taskCh)
}()
go func() {
defer wg.Done()
go consumer(taskCh)
}()
wg.Wait()
// 上面两个协程都执行完毕后,下面这行输出才会打印出来
out.Println("执行成功")
}
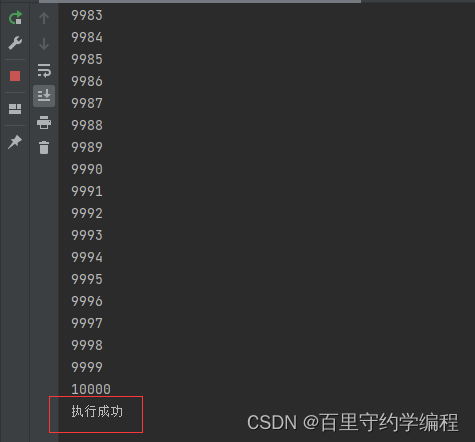
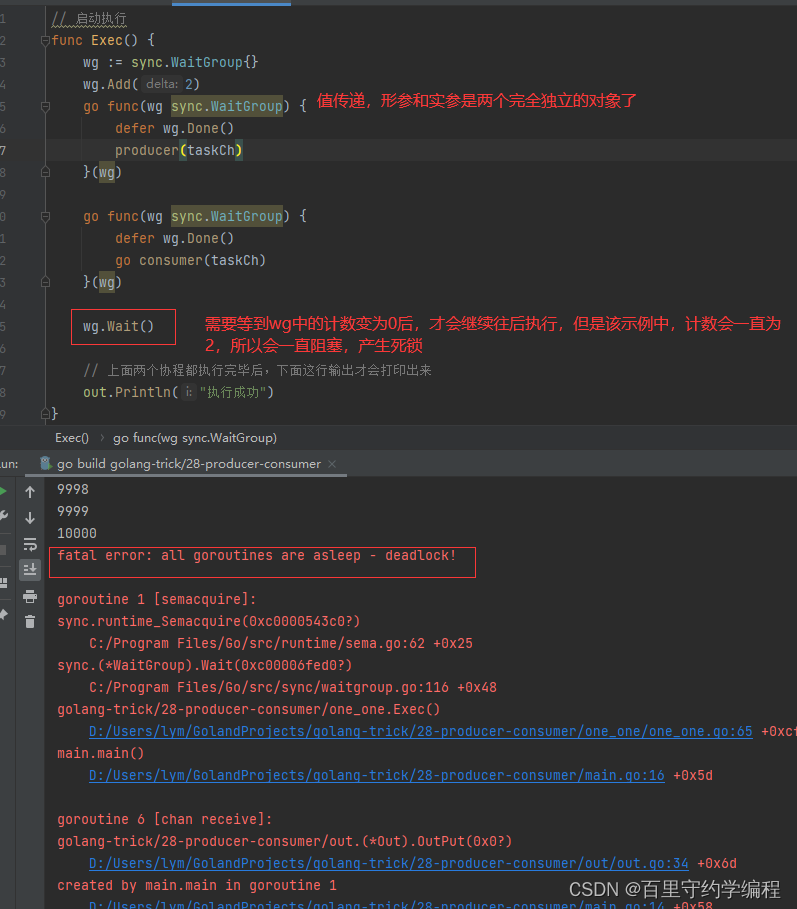
wg.Wait()等不到计数归零时会报死锁(比如wg进行了值传递)
注意点:有时候我们需要将wg传入到协程里面去,这个时候如果是值传递就会报错,如将代码改为如下形式后再执行
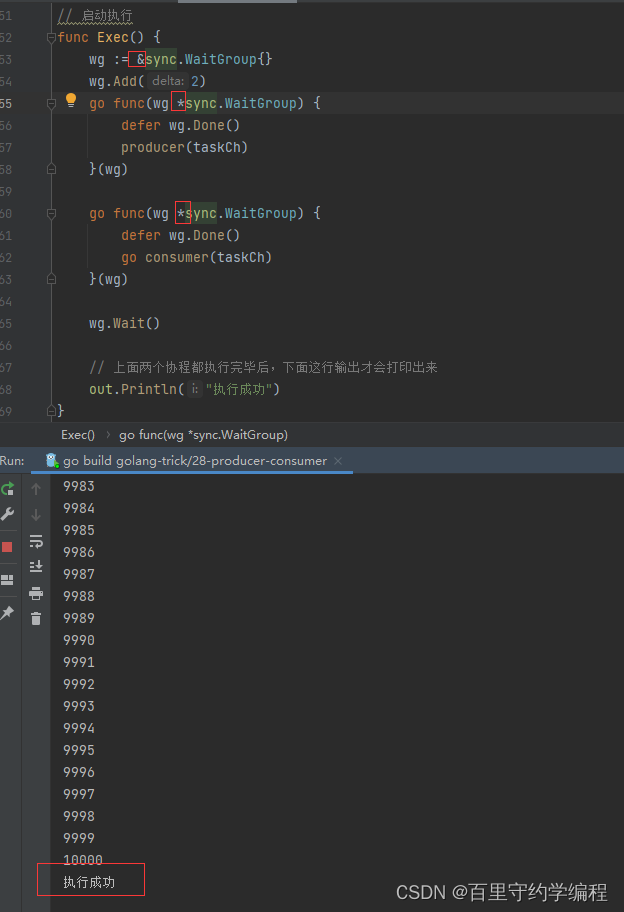
将wg改为引用类型后,再传递,然后执行就不会有问题了,如下
四、生产消费模式之一对多
1、本小节知识点总结
go中的chan是线程安全的,多个协程并发的去访问chan,是并发安全的,不用额外加锁
2、one_many 模式
新建one_many包和one_many.go文件,如下,其实one_many.go文件的内容和one_one.go的文件内容基本是一致的,主要就是Exec方法中,启动了多个消费者,以及wg.Add的位置调整了一下,因为不在是固定只启动两个协程,而是多个协程了,所以改为没启动一个前wg.Add(1)。
package one_many
import (
"golang-trick/28-producer-consumer/out"
"sync"
)
// 为了方便,生产者生产任务,实际就是生产了一个ID,放到缓冲区中
// 消费者消费任务,打印Task中的ID。
// 实际工作中,生产者一般是生产一个JSON数据,消费者消费到JSON数据后进行自己的业务逻辑
// 这里为了演示,所以就定义了Task,直接往缓冲区中放入Task,这样消费者取出Task后,直接执行Task的run方法就当做是执行业务逻辑了
type Task struct {
ID int64
}
func (t *Task) run() {
// 使用到了我们out工具包中的方法模拟业务逻辑,实际其实跟直接使用fmt.Println效果一样,都是往控制台打印一下输出
// 不过是本次就是想学习生产消费模式,而这个out工具包其实也是一个简单的生产消费模式,所以用它
out.Println(t.ID)
}
// 定义缓冲区,大小为10,元素类型为Task
var taskCh = make(chan Task, 10)
// 定义需要发送的任务数量(实际工作中生产者不会断生产,消费者会一直消费)
// 这里定义能生产的数量,是为了演示后面通道关闭需要注意的很多细节
const taskNum int64 = 10000
// 生产 wCh:write chan
func producer(wCh chan<- Task) {
var i int64
for i = 1; i <= taskNum; i++ {
t := Task{
ID: i,
}
wCh <- t
}
// 生产完毕之后,可以关闭通道
close(wCh)
}
// 消费 rCh: read chan
func consumer(rCh <-chan Task) {
for t := range rCh {
if t.ID != 0 {
t.run()
}
}
}
// 启动执行
func Exec() {
wg := &sync.WaitGroup{}
wg.Add(1)
go func(wg *sync.WaitGroup) {
defer wg.Done()
producer(taskCh)
}(wg)
var i int64
for i = 0; i < taskNum; i++ {
if i%100 == 0 { // 启动taskNum / 100 个消费者
wg.Add(1)
go func(wg *sync.WaitGroup) {
defer wg.Done()
go consumer(taskCh)
}(wg)
}
}
wg.Wait()
// 上面两个协程都执行完毕后,下面这行输出才会打印出来
out.Println("执行成功")
}
五、生产消费模式之多对一
1、本小节知识点总结
- 实际工作中,多对一的形式基本不会出现,本身就是想要削峰填谷,多对一的话,消费能力可能跟不上生产能力,得不偿失,会出现很多问题
- 多个生产者,如何关闭
channel呢?在所有生产者生产完毕后关闭channel,所以需要单独为生产者提供一个sync.WaitGroup - 协程里面想使用外部会变化的变量时,应该作为参数传入协程,否则可能会出现预期之外的结果
- 往已经关闭的通道写值会报错
2、many_one 模式
新建many_noe包和many_one.go文件
主要改动生产方法producer和执行方法Exec
- 为了演示,我们改造了一下
producer,多传了两个参数,startNum:从那个数字开始生成,nums:生产多少个数字,这样的话,多个消费者的生产结果合并起来还是从1-10000 Exec中启动多个生产者,但是只有一个消费者
注意看下面代码中注释的1,2,3,4
package many_one
import (
"golang-trick/28-producer-consumer/out"
"sync"
)
// 为了方便,生产者生产任务,实际就是生产了一个ID,放到缓冲区中
// 消费者消费任务,打印Task中的ID。
// 实际工作中,生产者一般是生产一个JSON数据,消费者消费到JSON数据后进行自己的业务逻辑
// 这里为了演示,所以就定义了Task,直接往缓冲区中放入Task,这样消费者取出Task后,直接执行Task的run方法就当做是执行业务逻辑了
type Task struct {
ID int64
}
func (t *Task) run() {
// 使用到了我们out工具包中的方法模拟业务逻辑,实际其实跟直接使用fmt.Println效果一样,都是往控制台打印一下输出
// 不过是本次就是想学习生产消费模式,而这个out工具包其实也是一个简单的生产消费模式,所以用它
out.Println(t.ID)
}
// 定义缓冲区,大小为10,元素类型为Task
var taskCh = make(chan Task, 10)
// 定义需要发送的任务数量(实际工作中生产者不会断生产,消费者会一直消费)
// 这里定义能生产的数量,是为了演示后面通道关闭需要注意的很多细节
const taskNum int64 = 10000
// 为了演示,我们改造了一下producer,多传了两个参数,startNum:从那个数字开始生成,nums:生产多少个数字
// 这样的话,多个消费者的生产结果合并起来还是从1-10000
func producer(wCh chan<- Task, startNum int64, nums int64) {
var i int64
for i = startNum; i < startNum+nums; i++ {
t := Task{ID: i}
wCh <- t
}
// 1. 关闭通道的操作不应该写在这里啦,因为有多个协程会调用producer了
// 某个协程关闭了channel,后面的协程进来producer尝试往channel写值,往关闭的channel写值会报错的
// close(wCh)
}
// 消费 rCh: read chan
func consumer(rCh <-chan Task) {
for t := range rCh {
if t.ID != 0 {
t.run()
}
}
}
// 启动执行
func Exec() {
wg := &sync.WaitGroup{}
// 2. 在所有生产者生产完毕后关闭channel,所以需要单独为生产者提供一个sync.WaitGroup
pwg := &sync.WaitGroup{}
var i int64
// 每隔100个数启动一个消费者
for i = 0; i < taskNum; i += 100 {
if i >= taskNum {
break
}
wg.Add(1)
pwg.Add(1)
// 3. i 需要作为变量传入,协程启动需要时间,而i还在变化,协程正式启动起来时,i的值已经不是我们期望的那个值了
go func(i int64) {
defer wg.Done()
defer pwg.Done()
producer(taskCh, i, 100)
}(i)
}
wg.Add(1)
go func() {
defer wg.Done()
consumer(taskCh)
}()
pwg.Wait()
// 4. 所有生产者都生产完毕后,关闭通道,而不是在producer()方法中关闭通道了,在那里关闭的话,会报错
// 因为可能某个协程关闭了通道,但另一个生产者还在尝试往里面写值,往已经关闭的通道写值会报错
close(taskCh)
wg.Wait()
out.Println("执行成功")
}
六、生产消费模式之多对多
1、本小节知识点总结
- 实际工作中,除一对多外,最常见的模式就是对多,当然,一对多也很常见,如一个消息队列只有一个生产者,但是有多个业务方会对齐进行消费,不过他们的消费是每个业务方都会整体消费一遍,而不是共同消费完所有消息。
- 实现生产者和消费者都是开启协程不退出的,不断的生产和消费,除非接收到外部让其退出的信号
- 当只作为信号通知,并不关心通道中的值时,可以使用
struct{}作为chan的类型,因为struct{}{}不占用内存 - 使用
select机制控制协程退出,close后的通道总是可读的,读完数据后,继续读,会读出对应类型的零值 - 关闭已经关闭的通道会报
panic
2、many_many 模式
新建many_many包和many_many.go文件
注意看下面代码中注释的1,2,3,4
package many_many
import (
"golang-trick/28-producer-consumer/out"
"time"
)
type Task struct {
ID int64
}
func (t *Task) run() {
out.Println(t.ID)
}
// 定义缓冲区,大小为10,元素类型为Task
var taskCh = make(chan Task, 10)
// 用于发送退出生产的信号,由于只是信号,只关心通道有没有值,所有类型使用struct{},不占任何字节内存
var done = make(chan struct{})
const taskNum int64 = 10000
func producer(wCh chan<- Task, done chan struct{}) {
var i int64
for {
if i >= taskNum {
i = 0 // 模拟生产者在不断的发送
}
i++
t := Task{ID: i}
// 使用select控制协程退出
select {
case wCh <- t:
case <-done:
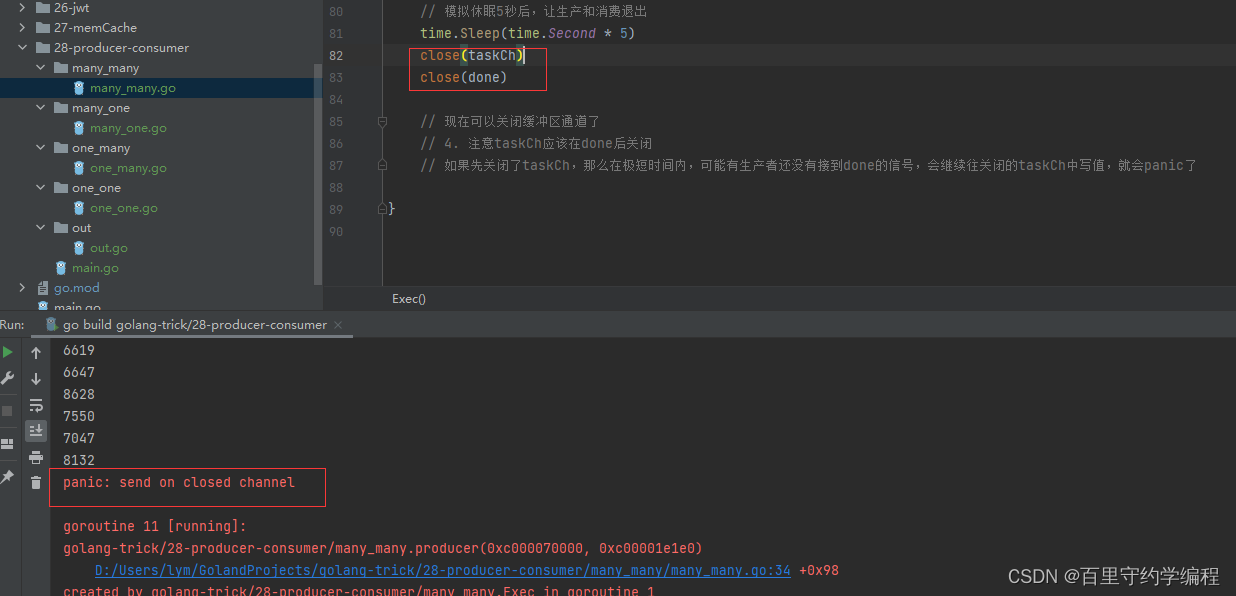
// 1. 关闭缓冲区通道不能写在这里,因为有多个生产者协程可以执行到这里,他们都来关闭一次通道的话肯定panic,因为关闭已经关闭的通道会panic
// close(wCh)
out.Println("生产者退出")
return
}
}
}
func consumer(rCh <-chan Task, done chan struct{}) {
for {
select {
case t := <-rCh:
if t.ID != 0 {
t.run()
}
case <-done: // 2. 当done被关闭后,生产者和消费者的对应case就都能取出值了,因为close后的通道总是可读的,读完数据后,继续读,会读出对应类型的零值
// 3. 当接收到done的退出信息时,缓冲区中的消息可能还没有消费完成呢,所以我们继续将缓冲区的消息消费完后才退出比较合理
for t := range rCh {
if t.ID != 0 {
t.run()
}
}
out.Println("消费者退出")
return
}
}
}
func Exec() {
go producer(taskCh, done)
go producer(taskCh, done)
go producer(taskCh, done)
go producer(taskCh, done)
go producer(taskCh, done)
go producer(taskCh, done)
go consumer(taskCh, done)
go consumer(taskCh, done)
go consumer(taskCh, done)
go consumer(taskCh, done)
go consumer(taskCh, done)
go consumer(taskCh, done)
// 模拟休眠5秒后,让生产和消费退出
time.Sleep(time.Second * 5)
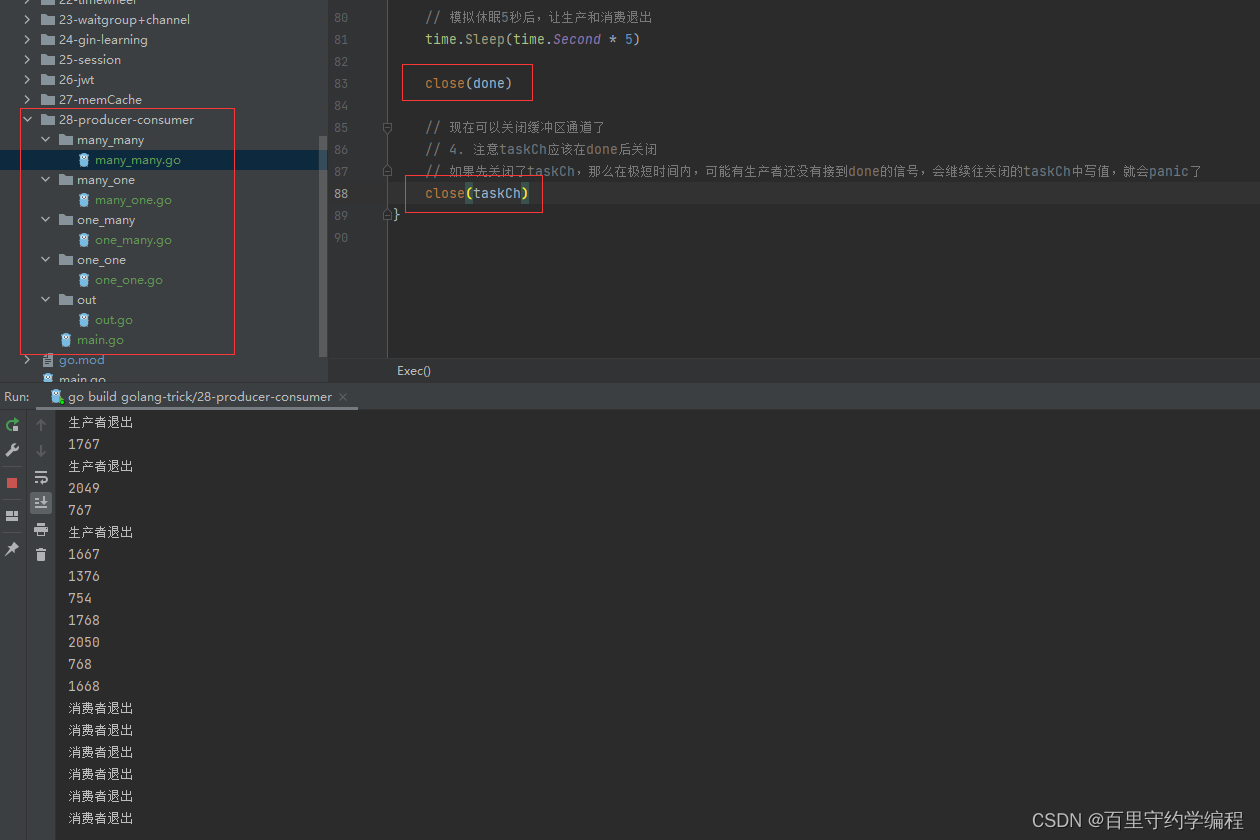
close(done)
// 现在可以关闭缓冲区通道了
// 4. 注意taskCh应该在done后关闭
// 如果先关闭了taskCh,那么在极短时间内,可能有生产者还没有接到done的信号,会继续往关闭的taskCh中写值,就会panic了
close(taskCh)
}

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









