




目录
本节重点
- 理解应用层的作用, 初识HTTP协议
- 学会使用一些分析网络问题的工具和方法
应用层
之前谈过应用层就是程序员编写的一层,下面的传输层、网络层、数据链路层由os帮我们完成
应用层即A告诉B实际要完成什么任务,比如下载电影,比如下单等,而下面几层是如何保证将数据传输到B
再谈协议
协议就是一种约定:只有双方遵循一种协议,才能互相通信,就像两个会说话的人,一个说北方话一个说南方话那就沟通不了,只有两边都说普通话才行,对于socket api接口,在读写数据时,都是按“字符串”的方式发送接受的(字符串只是个形象描述),如果我们要传输一些“结构化的数据”怎么办
注意:接下来谈的是应用层的协议,我们要制作一个协议,客户端遵循服务器遵循,双方通过协议正常解析对方发来的消息/任务,才能进行下一步
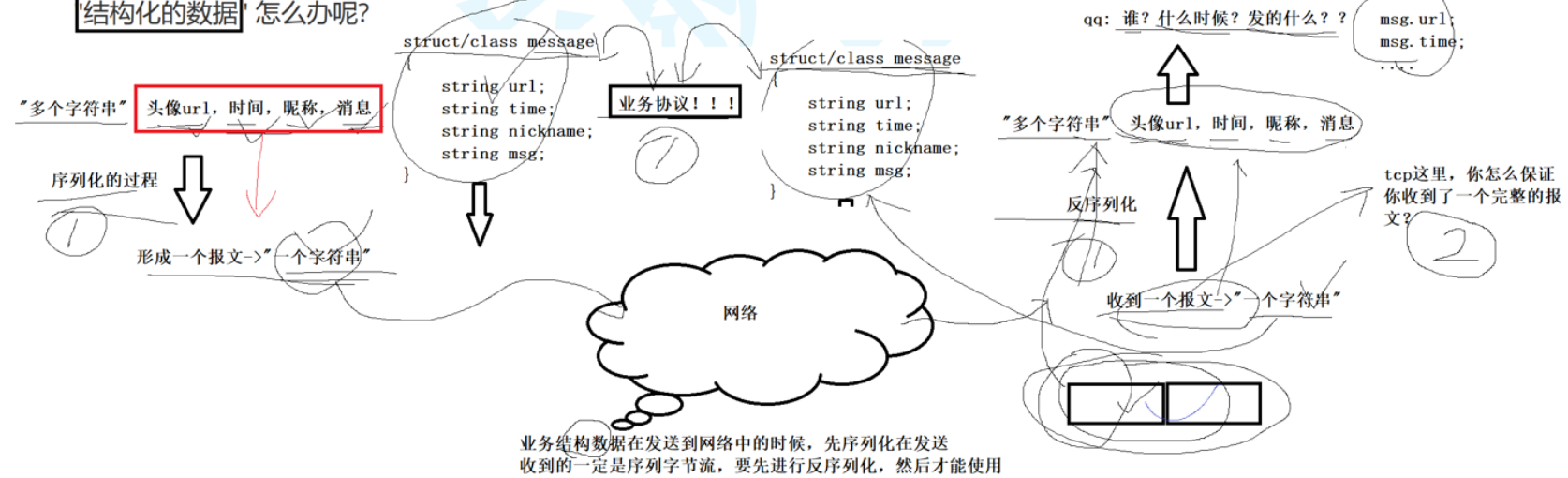
假设你不使用结构化的数据:
比如张三20北京市朝阳区
1. 你这样无法区分是张三2还是张三,是0岁还是20岁(有歧义)
2. 你需要单独规定用什么特殊字符来分隔每个字段(张三|20|北京市朝阳区)
3. 但是有些字段本身就包含|,比如北京市|朝阳区,那你解析的时候就会出现问题,而且字段为null怎么办?
4. 如果需要增加新的字段,比如电话,你所有的接收端的逻辑又要修改一遍
“纯字符串传输” 在极简单场景下可行,但会引入「解析歧义、扩展性差、兼容性低」的致命问题
序列化的本质不是 “转字符串”,而是给数据加「结构化约定」,让通信双方能无歧义地解析数据。
流程:
结构化数据--->序列化成一种特定的结构化约定---->传输------>反序列化解析成结构化数据
编写一个自定义协议的网络计算器
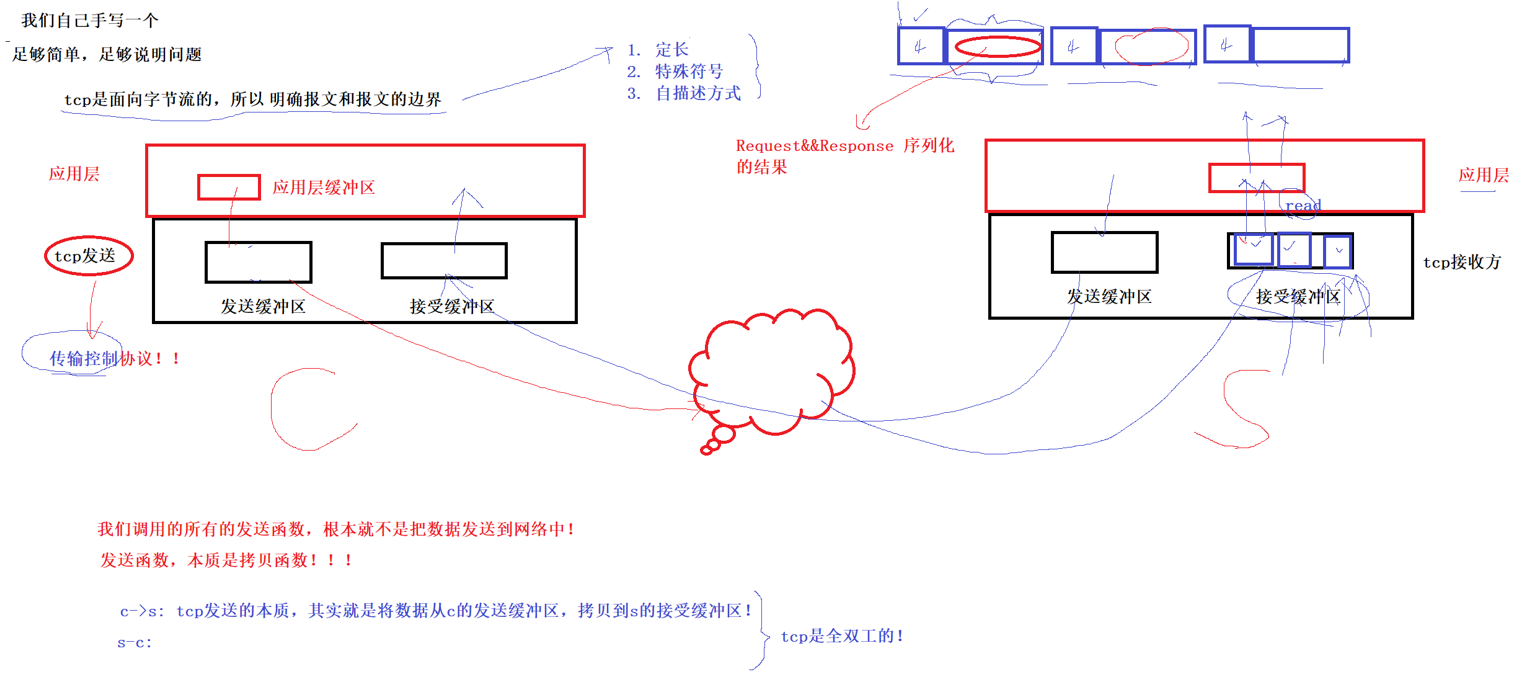
整个过程:我们需要将结构化的数据通过序列化,然后write写到tcp的发送缓冲区,不是由我们调用发送函数就发送到网络,而是拷贝到tcp的发送缓冲区,由os自主决定什么时候发,发多少,发错怎么办(有对应的机制,后面详讲),由于缓冲区是分开的,无论是客户端还是服务端发送和接收是互不干扰的,所以叫全双工。
tcp放到接收缓冲区之前由os帮我们处理好tcp层的报文,也就是解包+分用,我们接收缓冲区拿到的就是我们应用层规定的协议
当服务端的read忙其他时没有及时读,一下子积累了很多的报文,那我如何保证我读到的一个完整的报文,而不是半个,一个半呢???
此时我们应用层协议就需要发挥作用了,报文=报头+有效载荷,需要明确报文和报文的边界
1. 定长:直接用头几个字节来描述有效载荷有多长
2.特殊符合:分隔不同的报文
3.自描述方式:我是什么类型、有哪些字段、每个字段多长
这里采用定长的方式
总结:
我们需要定义协议,报文长啥样,服务端接收的时候可以进行区分报文和报文的边界(此时需要我们添加报头的设计)
序列化和反序列化:各个字段之间如何分开(这里采用特殊字符,自己编写)
两个结构体代表结构化数据:request请求(操作数x,y,操作符op),response回复(返回码表示计算成功失败,返回结果)
业务逻辑:

序列化和反序列化代码
注意:我们编写的是自己的,没有用第三方的,我这里使用了特殊字符比如空格来区分不同字段
//这里是request的序列化和反序列化
bool serialize(std::string *out){
*out = "";
// 结构化 -> "x op y";
std::string x_string = std::to_string(x);
std::string y_string = std::to_string(y);
*out = x_string;
*out += SEP;
*out += op;
*out += SEP;
*out += y_string;
return true;
}
// "x op yyyy";
bool deserialize(const std::string &in)
{
// "x op y" -> 结构化
auto left = in.find(SEP);
auto right = in.rfind(SEP);
if (left == std::string::npos || right == std::string::npos)
return false;
if (left == right)
return false;
if (right - (left + SEP_LEN) != 1)
return false;
std::string x_string = in.substr(0, left); // [0, 2) [start, end) , start, end - start
std::string y_string = in.substr(right + SEP_LEN);
if (x_string.empty())
return false;
if (y_string.empty())
return false;
x = std::stoi(x_string);
y = std::stoi(y_string);
op = in[left + SEP_LEN];
return true;
}
//这里是respon的序列化和反序列化
bool serialize(std::string *out){
*out = "";
std::string ec_string = std::to_string(exitcode);
std::string res_string = std::to_string(result);
*out = ec_string;
*out += SEP;
*out += res_string;
return true;
}
bool deserialize(const std::string &in){
// "exitcode result"
auto mid = in.find(SEP);
if (mid == std::string::npos)
return false;
std::string ec_string = in.substr(0, mid);
std::string res_string = in.substr(mid + SEP_LEN);
if (ec_string.empty() || res_string.empty())
return false;
exitcode = std::stoi(ec_string);
result = std::stoi(res_string);
return true;
}添加报头和去掉报头
我们从接收缓冲区读取的数据,需要区分不同的报文,所以需要这两个函数,这里我采用的是头部添加四个字节,这个四个字节叫报头,报头中描述有效载荷有多长,这样就能计算出整个报文多大
// "x op y" -> "content_len"\r\n"x op y"\r\n
// "exitcode result" -> "content_len"\r\n"exitcode result"\r\n
std::string enLength(const std::string &text)
{
std::string send_string = std::to_string(text.size());
send_string += LINE_SEP;
send_string += text;
send_string += LINE_SEP;
return send_string;
}
// "content_len"\r\n"exitcode result"\r\n
bool deLength(const std::string &package, std::string *text)
{
auto pos = package.find(LINE_SEP);
if (pos == std::string::npos)
return false;
std::string text_len_string = package.substr(0, pos);
int text_len = std::stoi(text_len_string);
*text = package.substr(pos + LINE_SEP_LEN, text_len);
return true;
}服务器主要核心逻辑代码
void handlerEntery(int sock, func_t func)
{
std::string inbuffer;
while (true)
{
// 1. 读取:"content_len"\r\n"x op y"\r\n
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
std::string req_text, req_str;
// 1.2 我们保证,我们req_text里面一定是一个完整的请求:"content_len"\r\n"x op y"\r\n
if (!recvPackage(sock, inbuffer, &req_text))
return;
std::cout << "带报头的请求:\n" << req_text << std::endl;
if (!deLength(req_text, &req_str))
return;
std::cout << "去掉报头的正文:\n" << req_str << std::endl;
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
func(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
std::string resp_str;
resp.serialize(&resp_str);
std::cout << "计算完成, 序列化响应: " << resp_str << std::endl;
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
std::string send_string = enLength(resp_str);
std::cout << "构建完成完整的响应\n" << send_string << std::endl;
send(sock, send_string.c_str(), send_string.size(), 0); // 其实这里的发送也是有问题的,不过后面再说
}
}客户端主要核心逻辑代码
void start()
{
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(_serverport);
server.sin_addr.s_addr = inet_addr(_serverip.c_str());
if (connect(_sock, (struct sockaddr *)&server, sizeof(server)) != 0)
{
std::cerr << "socket connect error" << std::endl;
}
else
{
std::string line;
std::string inbuffer;
while (true)
{
std::cout << "mycal>>> ";
std::getline(std::cin, line); // 1+1
Request req = ParseLine(line); // "1+1"
std::string content;
req.serialize(&content);
std::string send_string = enLength(content);
std::cout << "sendstring:\n" << send_string << std::endl;
send(_sock, send_string.c_str(), send_string.size(), 0); // bug?? 不管
std::string package, text;
// "content_len"\r\n"exitcode result"\r\n
if (!recvPackage(_sock, inbuffer, &package))
continue;
if (!deLength(package, &text))
continue;
// "exitcode result"
Response resp;
resp.deserialize(text);
std::cout << "exitCode: " << resp.exitcode << std::endl;
std::cout << "result: " << resp.result << std::endl;
}
}
}注意:代码中的bug是因为send无法保证一次性发一个完整的过去,有时候发送缓冲区满了就发不了了,比如100字节,可能只发了30字节,需要检查返回值
总结:序列化和反序列化自己写起来麻烦并且很挫,改动也麻烦,无非就是做一个工作,如何描述结构化的数据《--------》特定的结构化约定(可以想象成一种带特殊分隔符分隔字段的字符串,但这个说法不对)
所以对于序列化和反序列化有现成的解决方案,绝对不会自己去写,但协议需要,你需要规定x op y,需要规定报文
序列化和反序列方案
1.json
2.protobuf
3.xml
| 方案 | 格式类型 | 可读性(人类是否能直接看懂) | 示例(描述 “姓名张三、年龄 20”) |
|---|---|---|---|
| JSON | 文本格式 | 高(键值对结构,直接可读) | {"name":"张三","age":20} |
| Protobuf | 二进制格式 | 低(必须通过工具解析) | 二进制字节流(如 0A 06 E5 BC A0 E4 B8 89 10 14) |
| XML | 文本格式 | 高(标签化结构,语义清晰但冗余) | <User><name>张三</name><age>20</age></User> |
| 方案 | 序列化 / 反序列化性能 | 数据体积(同等内容) | 核心原因 |
|---|---|---|---|
| JSON | 中等 | 较大(冗余字段名) | 文本格式 + 键值对冗余 |
| Protobuf | 极高(比 JSON 快 10~20 倍) | 极小(仅存字段编号 + 值) | 二进制格式 + 无冗余字段名 |
| XML | 低 | 极大(冗余标签) | 文本格式 + 标签嵌套冗余 |
| 方案 | 开发成本 | 跨语言兼容性 | 版本兼容性(新增字段) |
|---|---|---|---|
| JSON | 极低(几乎所有语言内置解析库) | 极高(全语言支持) | 高(旧版本可忽略未知字段) |
| Protobuf | 中等(需定义.proto文件 + 编译) | 极高(官方支持多语言) | 极高(字段编号不变即可兼容) |
| XML | 高(需处理标签解析 + Schema 约束) | 高(全语言支持) | 中等(需兼容标签结构) |
| 方案 | 典型场景 |
|---|---|
| JSON | 前后端交互、轻量级接口对接、普通业务数据传输 |
| Protobuf | 高并发微服务、游戏服务器、物联网(低带宽)、大数据传输 |
| XML | 传统企业系统(如 SOAP 接口)、配置文件 |
综上,我们已经学习了应用层协议(自个编写的)
HTTP协议
通过之前的自定义应用层协议,可以很明确的知道http协议做的事情跟我们自定义的一样
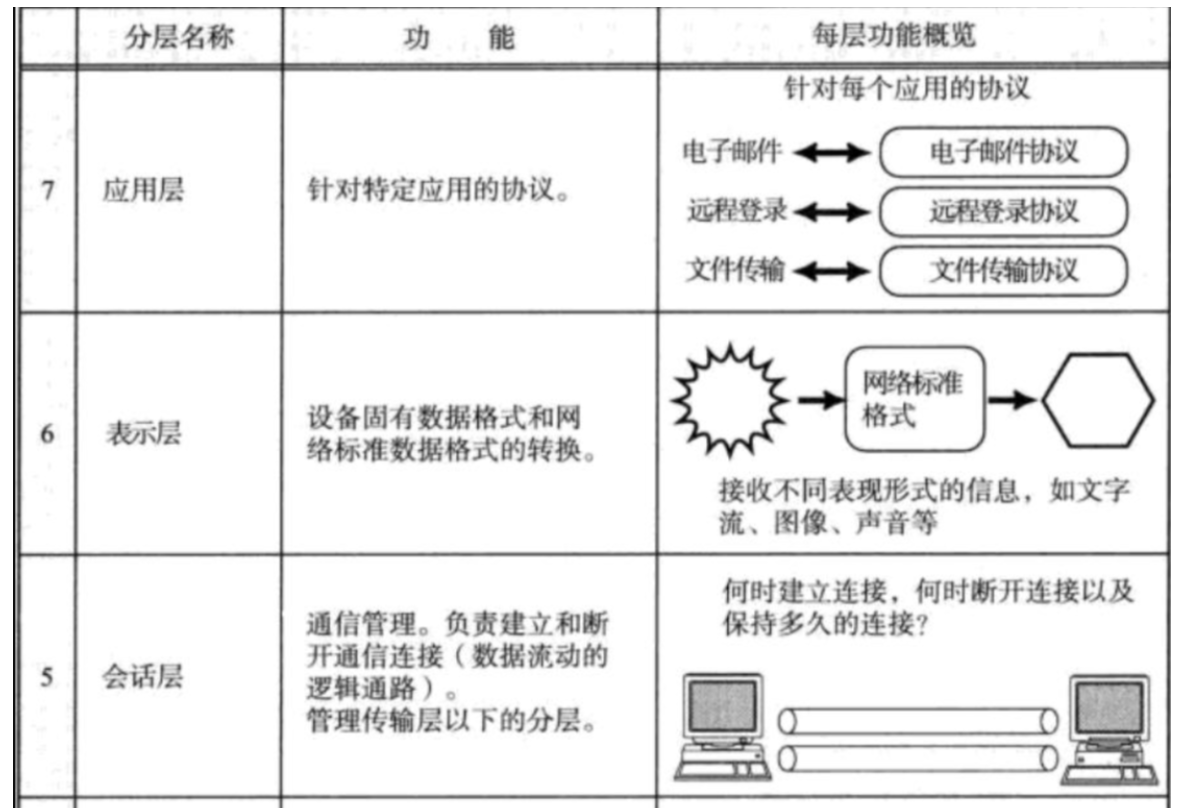
会话层:也就是我们的socket连接
表示层:添加报头,序列化反序列化等
应用层:你的业务逻辑,比如计算器业务
只不过是http协议人家已经帮我们做了这部分工作,直接拿来使用即可
http和https都是全球性的超文本信息交互生态系统(web)的通信协议
认识URL
平时我们俗称的“网址”其实就是说的URL

urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如:某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
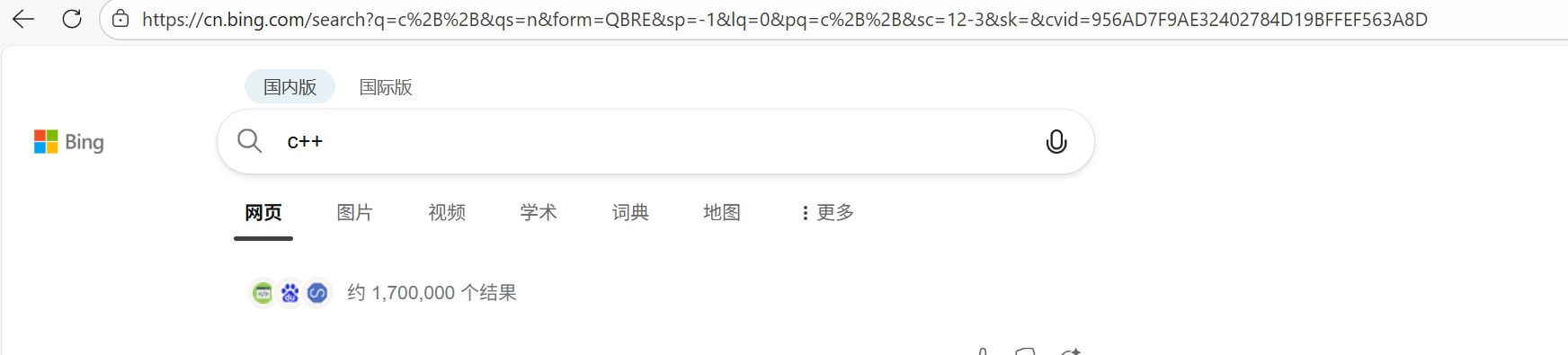
这里可以看到+已经是%2B,因为+的ASCII是43,转成16进制就是2B
urlencode就是将字符变成%XY格式
urldecode就是%XY格式变成字符
网上有工具自行查询一下
这个是允许携带特殊字符,使用urlencode,后面服务器收到请求之后在使用urldecode解码即可
HTTP超文本通信的整个大致流程
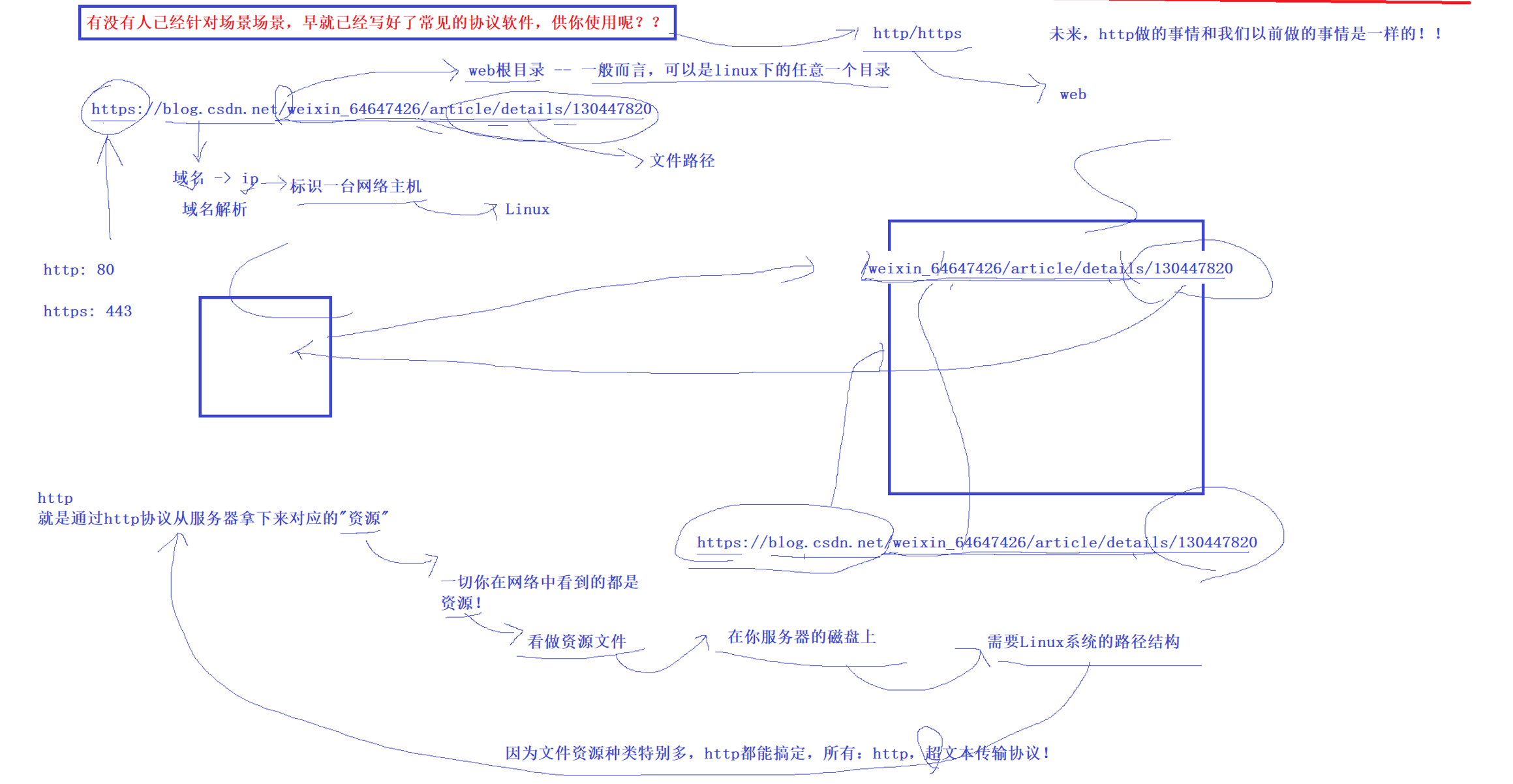
域名即ip地址
http的端口通常是80,https的端口通常是443(一般端口需要显示出来,只是浏览器省略)
域名后面/:注意这个是web根目录,不是你的Linux服务器的根目录,概念不一样
后面的一串路径:是你申请的资源的位置,比如这里是访问某个人的朋友圈,那就是一串id,得到之后后面返回给你id对应的朋友圈
由于所有的资源,无论是视频还是文本,http都能够搞定,所以叫做超文本协议
web:全球性的超文本信息交互生态系统
web是一个生态系统,它包含通信协议http和https,还有web客户端(比如浏览器),web服务器,web应用(网页版微信)
超文本:超文本就是支持视频文本等多样的数据形式,还有超链接,支持跳转,比如你点一个链接可以跳到别的网页
HTTP发展历史
| 版本 | 协议类型 | 核心特性 | 解决的核心痛点 |
|---|---|---|---|
| HTTP/0.9 | 文本 | 仅 GET 方法,纯文本传输 | 无(协议雏形) |
| HTTP/1.0 | 文本 | 多方法、多资源类型、状态码 | 支持图片等二进制资源传输 |
| HTTP/1.1 | 文本 | 持久连接、管道化、Host 必选 | 减少 TCP 连接开销,支持虚拟主机 |
| HTTP/2 | 二进制 | 多路复用、头部压缩、服务器推送 | 彻底解决 HTTP 层队头阻塞 |
| HTTP/3 | 基于 QUIC | 连接迁移、UDP 传输、内置 TLS 1.3 | 解决 TCP 层队头阻塞,提升安全性 |
HTTP 协议的演进始终围绕 「提升性能」和「增强安全」 两个核心目标:
- 从「文本协议」到「二进制协议」,提升解析效率;
- 从「短连接」到「持久连接」再到「多路复用」,提升并发能力;
- 从「明文传输」到「强制加密」(HTTP/3 内置 TLS),强化通信安全;
- 从「依赖 TCP」到「基于 QUIC」,解决底层传输的队头阻塞问题。
这里主要讲解1.0,提一嘴1.1,2.0不讲
HTTP的协议格式
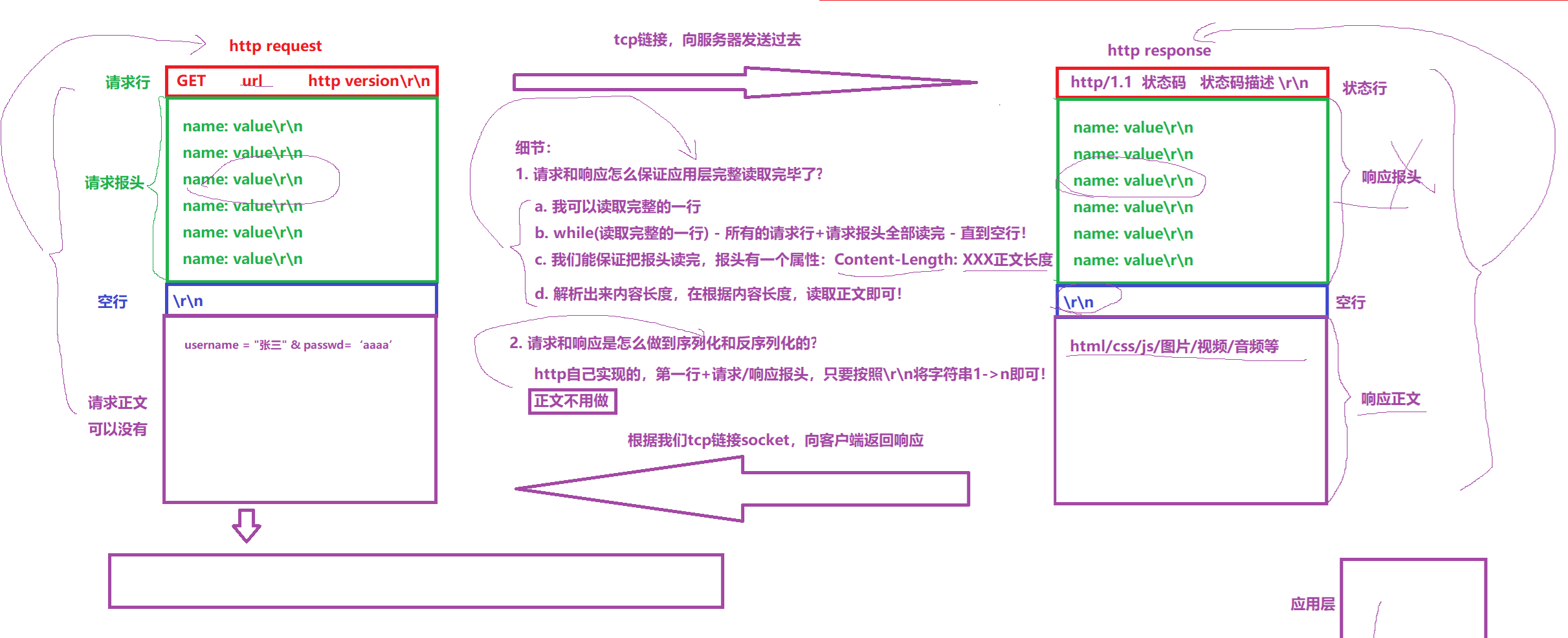
request第一行:[方法] + url + [版本]
GET就是方法,版本就是HTTP/1.0这样
下面多行:这是报头
这里面的字段都是name: value\r\n的形式(注意:后面有个空格)
比如有个字段Content-Length: 36,这个表示有效载荷的大小
报头最后一行是\r\n,表示报头结束,后面是有效载荷
每一个协议需要解决的问题:判断哪里是报头哪里是有效载荷
有效载荷(body):这个部分允许为空字符串

因为http的格式是\r\n,所以这里它使用分隔符来标记,这样能够拼接成字符串(序列化),后面服务器接收后再找\r\n就能够转换成结构化的数据(反序列化),为什么这里可以用分隔符,本质是因为你的请求中如果有特殊字符它早就通过urlencode转码了
response:第一行[版本] [状态码] [状态描述]
比如我们写一个函数,如果函数出错它需要设置错误码,让外面获取知道错误,这里的状态码也是告诉客户端完成的怎么样,类似我们的网络计算器中的exitcode
方法说明
| 方法 | 核心语义 | 是否安全 | 是否幂等 | 允许请求体 | 典型使用场景 |
|---|---|---|---|---|---|
| GET | 读取 / 查询资源 | ✅ 安全 | ✅ 幂等 | ❌(规范) | 访问网页、查询数据(如 /api/user?id=1) |
| POST | 创建 / 提交资源 | ❌ 不安全 | ❌ 非幂等 | ✅ 允许 | 提交表单、创建数据(如 /api/user 创建新用户) |
| PUT | 全量更新资源(替换) | ❌ 不安全 | ✅ 幂等 | ✅ 允许 | 更新用户全部信息(如 /api/user/1 替换用户 1) |
| DELETE | 删除资源 | ❌ 不安全 | ✅ 幂等 | ❌(规范) | 删除数据(如 /api/user/1 删除用户 1) |
| PATCH | 增量更新资源(部分修改) | ❌ 不安全 | ✅ 幂等 | ✅ 允许 | 修改用户手机号(仅改一个字段,如 /api/user/1) |
| HEAD | 仅获取响应头(无响应体) | ✅ 安全 | ✅ 幂等 | ❌ 禁止 | 检查资源是否存在、获取文件大小 / 更新时间 |
| OPTIONS | 探测服务端支持的方法 | ✅ 安全 | ✅ 幂等 | ❌ 禁止 | 跨域请求(CORS)预检、查询接口支持的方法 |
| TRACE | 回显请求(调试用) | ✅ 安全 | ✅ 幂等 | ❌ 禁止 | 排查请求传输过程中的修改(极少用,易被攻击) |
- 安全性:执行该方法是否会「修改服务端数据」—— 安全方法(GET/HEAD/OPTIONS/TRACE)仅读取数据,不会改变服务端状态;不安全方法(POST/PUT/DELETE/PATCH)会修改数据。
- 幂等性:多次执行同一请求,是否得到相同的结果(服务端状态一致)—— 幂等方法(GET/PUT/DELETE/PATCH)多次调用和一次调用效果相同,非幂等方法(POST)多次调用可能创建多个资源(如重复提交表单创建两个用户)。
最常用的是GET和POST
状态说明
| 类别 | 首位数字 | 核心语义 | 典型场景 |
|---|---|---|---|
| 信息型 | 1xx | 临时响应,请求已接收,继续处理 | 100 Continue(预检通过) |
| 成功型 | 2xx | 请求已成功处理 | 200 OK、201 Created、204 No Content |
| 重定向 | 3xx | 需要客户端进一步操作(跳转) | 301 永久重定向、302 临时重定向、304 缓存命中 |
| 客户端错误 | 4xx | 客户端请求有误,服务端无法处理 | 400 参数错误、401 未授权、403 禁止访问、404 资源不存在 |
| 服务端错误 | 5xx | 服务端处理请求时出错 | 500 服务器内部错误、502 网关错误、503 服务不可用 |
| 业务场景 | 推荐状态码 | 原因说明 |
|---|---|---|
| 用户登录成功 | 200 OK | 通用成功,返回用户信息 |
| 注册新用户成功 | 201 Created | 资源创建成功,响应头返回新用户 URL |
| 删除用户成功 | 204 No Content | 成功但无需返回内容,减少带宽消耗 |
| 访问需要登录的接口 | 401 Unauthorized | 未授权,提示用户登录 |
| 普通用户访问管理员接口 | 403 Forbidden | 已授权但无权限,拒绝访问 |
| 接口参数校验失败 | 400 Bad Request | 客户端参数错误,明确指出错误字段 |
| 服务端代码抛空指针异常 | 500 Internal Server Error | 服务端未捕获异常,返回通用错误 |
| 高峰期接口限流 | 429 Too Many Requests | 客户端请求过频,提示重试时间 |
| 服务维护中暂停访问 资源不存在 | 503 Service Unavailable 404Not Found | 服务不可用,响应头加 访问不存在的页面、查询不存在的 ID |
HTTP 状态码的核心价值是「标准化的结果标识」—— 客户端(浏览器 / APP)可直接根据状态码做自动化处理(如 401 跳登录、304 用缓存、503 重试),无需解析响应体。
Header说明
高频请求头
| 头部名 | 核心语义 | 典型场景 |
|---|---|---|
Host | 指定请求的服务器域名 + 端口(HTTP/1.1 必选) | Host: www.example.com(虚拟主机核心,区分同一 IP 下的不同网站) |
User-Agent(UA) | 客户端标识(浏览器 / 设备 / 系统) | User-Agent: Mozilla/5.0 (Windows NT 10.0; Chrome/120.0.0.0)(服务端适配不同客户端) |
Content-Type | 请求体的数据格式 | application/json(JSON 数据)、application/x-www-form-urlencoded(表单)、multipart/form-data(文件上传) |
Content-Length | 请求体的字节长度 | Content-Length: 27(告诉服务端需读取多少字节的请求体) |
Authorization | 身份凭证(登录令牌) | Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9(JWT 令牌)、Basic dXNlcjE6密码Base64(基础认证) |
Cookie | 客户端携带的 Cookie(服务端之前设置的) | Cookie: uid=123; token=abc(维持登录状态) |
Accept | 客户端支持的响应数据格式 | Accept: application/json, text/html(优先要 JSON,其次 HTML) |
Accept-Encoding | 客户端支持的压缩方式 | Accept-Encoding: gzip, deflate(服务端压缩响应体,节省带宽) |
Referer | 请求的来源页面(从哪个页面跳转过来) | Referer: https://www.example.com/login(防盗链、统计来源) |
Cache-Control | 客户端的缓存要求 | Cache-Control: no-cache(不使用本地缓存,强制请求服务端) |
Origin | 跨域请求的源(协议 + 域名 + 端口) | Origin: https://blog.example.com(CORS 跨域预检核心) |
高频响应头
| 头部名 | 核心语义 | 典型场景 |
|---|---|---|
Content-Type | 响应体的数据格式 + 字符编码 | Content-Type: application/json; charset=utf-8(告诉客户端解析为 JSON,编码 UTF-8) |
Content-Length | 响应体的字节长度 | Content-Length: 1024(客户端按长度读取响应体) |
Set-Cookie | 服务端给客户端设置 Cookie | Set-Cookie: uid=123; Path=/; HttpOnly; Max-Age=3600(HttpOnly 防 XSS,Max-Age 设置有效期) |
Cache-Control | 服务端的缓存规则 | Cache-Control: max-age=86400(客户端缓存 24 小时)、no-store(禁止缓存) |
Location | 重定向的目标地址 | Location: https://www.new-example.com(配合 301/302 重定向) |
Server | 服务端软件标识 | Server: nginx/1.21.0(显示服务器类型,可隐藏提升安全性) |
Access-Control-Allow-Origin | 跨域允许的源 | Access-Control-Allow-Origin: *(允许所有域)、Access-Control-Allow-Origin: https://blog.example.com(仅允许指定域) |
Access-Control-Allow-Methods | 跨域允许的请求方法 | Access-Control-Allow-Methods: GET, POST, PUT(配合 OPTIONS 预检) |
Content-Encoding | 响应体的压缩方式 | Content-Encoding: gzip(客户端需先解压再解析) |
ETag | 资源的唯一标识(缓存校验) | ETag: "abc123"(配合 304,客户端请求时带If-None-Match: "abc123",服务端判断资源是否修改) |
Last-Modified | 资源最后修改时间(缓存校验) | Last-Modified: Mon, 15 Dec 2025 11:00:00 GMT(配合 304,客户端带If-Modified-Since校验) |
编写一个HTTP协议的网络服务器
服务端代码
#include <iostream>
#include <sys/socket.h>
#include <sys/types.h>
#include <cstring>
#include <arpa/inet.h>
#include <unistd.h>
#define DEFAULT_IP "0.0.0.0"
#define DEFAULT_PORT 7676
#define BACKLOG 5
class HttpServer{
private:
uint16_t _port;//端口号
std::string _ip;//ip地址
int _listenfd;//监听套接字
public:
HttpServer(uint16_t port=DEFAULT_PORT,std::string ip=DEFAULT_IP)
:_port(port)
,_ip(ip)
{}
//初始化服务器
void init(){
_listenfd = socket(AF_INET,SOCK_STREAM,0);//创建套接字,这个是ipv4,tcp
if(_listenfd<0){
std::cout<<"socket error:"<<errno<<strerror(errno)<<std::endl;
exit(1);//直接退出
}
struct sockaddr_in _addr;
bzero(&_addr,sizeof(_addr));//清零
_addr.sin_family = AF_INET;
_addr.sin_port = htons(_port);
_addr.sin_addr.s_addr = inet_addr(_ip.c_str());
if (bind(_listenfd, (struct sockaddr *)&_addr, sizeof(_addr)) < 0)
{
// bind失败
std::cerr << "bind error:" << errno << strerror(errno) << std::endl;
}
// listen监听模式
if (listen(_listenfd,BACKLOG) < 0)
{
// listen失败
std::cerr << "listen error:" << errno << strerror(errno) << std::endl;
}
std::cout<<"server init _listenfd="<<_listenfd<<std::endl;
}
void start(){
while(true){
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
//接收链接
std::cout<<"accept..."<<std::endl;
int client_fd = accept(_listenfd,(struct sockaddr*)&client_addr,&client_addr_len);
if(client_fd<0){
//accept失败
std::cerr<<"accept error:"<<errno<<strerror(errno)<<std::endl;
continue;
}
std::cout<<"client_fd="<<client_fd<<std::endl;
std::string client_ip=inet_ntoa(client_addr.sin_addr);
uint16_t client_port = ntohs(client_addr.sin_port);
char inbuf[1024] = {0};
int len = read(client_fd, inbuf, sizeof(inbuf) - 1);
if (len <= 0){
// 关闭套接字
close(client_fd);
break;
}
// 处理业务逻辑
std::cout << inbuf << std::endl;
// 构建一个响应返回出去
char outbuf[1024] = {0};
const char *html = "<html><body><h1>Hello World</h1></body></html>"; // 这个用于返回响应,html内容,浏览器会解析
sprintf(outbuf, "HTTP/1.1 200 OK\r\nContent-Length: %d\r\n\r\n%s", strlen(html), html);
write(client_fd, outbuf, strlen(outbuf));
close(client_fd); // 关闭
}
}
};
客户端代码
#include "http_server.hpp"
int main(){
HttpServer server;
server.init();
server.start();
}这只是一个简单的框架,简单的HTTP协议的框架,因为协议部分别人已经写好了,也就是应用层的协议别人做了,我们只需要获取各个字段去解析是啥意思,然后后端再去执行业务逻辑就行
浏览器(客户端)→ 构造HTTP请求(包含请求行/请求头/请求体)
→ 基于TCP发送给服务器 → 服务器解析HTTP请求 → 处理业务
→ 构造HTTP响应 → 基于TCP返回给浏览器
→ 浏览器解析响应 → 渲染页面/执行交互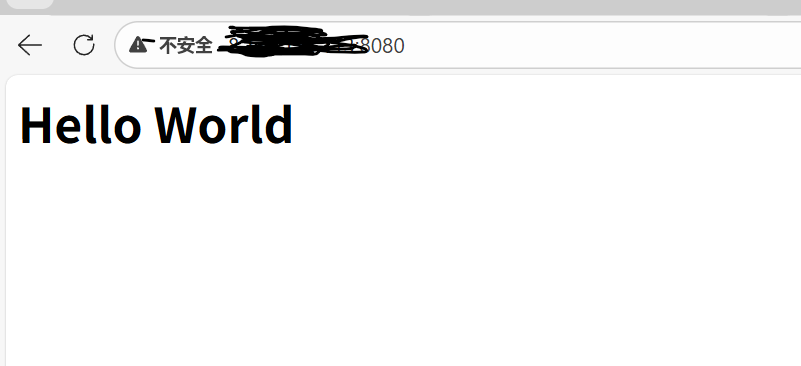

可以看到占有的文件描述符是4,因为3是socket创建出来的去监听了,所以是从小到大,所以只能是4去连接
GET:查询,请求某个资源
/favicon.ico:表示浏览器要获取服务器根目录下的
favicon.ico文件(这是网页的 “图标文件”,浏览器会自动请求这个文件,用来显示标签页图标);(一般来说就把你的网页的首页放在这里,别人访问的时候就可以去显示)HTTP/1.1:协议及版本
HOST:请求我们的服务器的什么,8080端口
Connection:这个是浏览器希望是长连接(注意我们的代码是close,短链接,所以会被服务器主动四次挥手断开连接)
User_Agent:表示 “发送请求的客户端是 Windows 10 系统 + Edge 浏览器(基于 Chrome 内核)”;服务器可以通过这个字段做 “浏览器 / 系统适配”(比如给移动端返回适配的页面)。
Accept:表示客户端能够收到的资源类型
为什么服务器发送的版本是1.1不是2等版本?
这个发送的协议的版本号取决于浏览器自身,不是由我们决定的,是浏览器自动适配的,因为我们的c++服务器返回去的是HTTP 1.1,如果支持更高版本,也是由浏览器和服务器之间通信协商完成的
这个请求的/favicon.ico是啥???
这里博主没有贴出来第一次,第一次请求没有这个目录,只有根目录
正常的浏览器会请求两次:第一次你输入ip:端口,请求web根目录,第二次浏览器自动请求小图标的资源,你需要放在/favicon.ico中,但是由于博主没有放,所以没有
这个请求时是长连接怎么解释???
这个是浏览器希望是长连接,但是是长还是短取决于我们的服务器,你也可以编写成长的
这里是一发一个请求响应之后关闭,你长连接的话可以使用一个连接去处理多个请求之后在关,这是取决于你的服务器的代码
如何理解web根目录???
请求的时候会携带请求的路径,比如之前我们请求的是/,那服务器收到之后就可以解析
一般来说服务器不会把web服务放在根目录下,比如你的进程放在/a/b/c下面,那别人传来一个/的时候你就需要解析,因为是/所以拼接再一次变成/a/b/c/,但是此时是一个路径,不是具体的文件,你需要特殊处理,判断一下如果前端传来/,那就去找/a/b/c/index.html,如果申请的是/register.html,那最后服务器拼接的时候就变成/a/b/c/register.html,然后服务器构建响应返回出去
所以web根目录其实就是一开始的路径/a/b/c,这是服务端做的识别
一般来说,会把所有的静态文件放在这个wwwroot目录下,后面请求啥我就加上./wwwroot即可,Web 根目录只存浏览器能直接请求、服务器能直接返回的静态文件,绝对不存服务器代码(如 C++/Java/PHP 源码)、配置文件(如数据库密码)、系统敏感文件!
所谓的前后端交互
前端:写好这个wwwroot目录,所有的样式前端去完成,
后端:处理静态资源请求:根据请求路径(比如
/login.html),从wwwroot里读取对应的文件返回;处理动态业务请求:接收前端的接口请求(比如/api/login),执行业务逻辑(验证账号密码),返回 JSON 格式的动态数据;
注意:一个网页不是仅仅有一个请求就能够完成的,一个网页包含很多资源(图片/文字等等),一个资源就需要一个http请求,所以一次连接需要多个请求才能完成网页的渲染
实用小工具telnet
telnet 是 TCP 协议的极简客户端工具,核心作用是「建立 TCP 连接、发送原始数据、接收服务器响应」—— 对咱们写 C++ HTTP 服务器来说,它是排查「端口连通性」和「HTTP 协议交互」的 “利器”,比浏览器更纯粹(不处理 HTML、不自动发 /favicon.ico 请求),能直接看到底层的请求 / 响应数据。
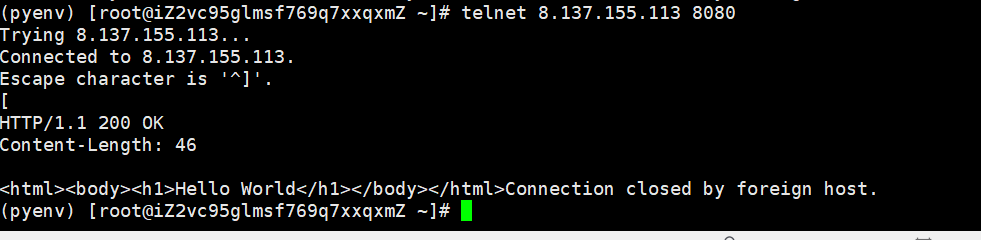
telnet ip 端口:这个就是使用这个小工具来连接你的服务器,后面就是建立成功
然后你可以自定义请求,这样可以避开浏览器自动帮你构建的,可以用来测试
然后输入[ 这个服务端就会构建响应返回去给你,可以看到最纯粹的底层响应数据
前端学习网站
可以去这个网站学习关于一个html的语法,简单搭建一个自己的网站
框架流程(理解GET和POST)
无非就两种情况:
1.获取资源:就是我们前面说的
2.上传资源(交互):html中有一种表单(可以在w3shool网站查询),就比如你登录时提交用户名和密码,后面需要把账户和密码发给服务器,服务器查询之后是对的再返回合法的界面,否则就是登录失败返回错误

这是一个表单,学过html的应该知道,我们填写相应的信息之后就会构建一次请求交给服务器

action:你要提交到哪个资源路径下
method:提交方法
下面就是表单:展示给用户看就是需要提交账户和密码
submit:就是提交按钮,写完之后就能够点击登录按钮
这样浏览器就会构建一次响应,后端就能够收到,然后解析进行判断
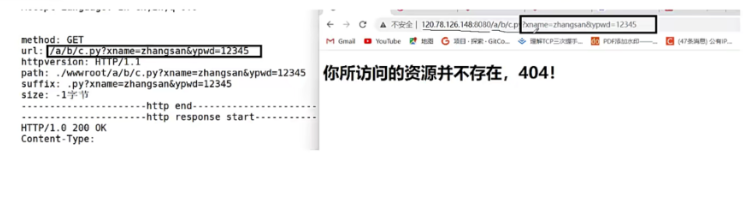
这个登录action最后会拼接到你的web根目录下形成url,?后面是你提交的参数,前面是提交到哪里(访问的资源),由于我们是随便写的,所以访问的资源不存在。
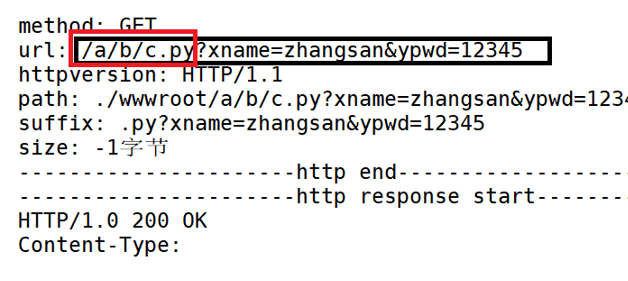
对于GET方法,浏览器会把提交的参数放在url中,?后面就是我们提交的参数
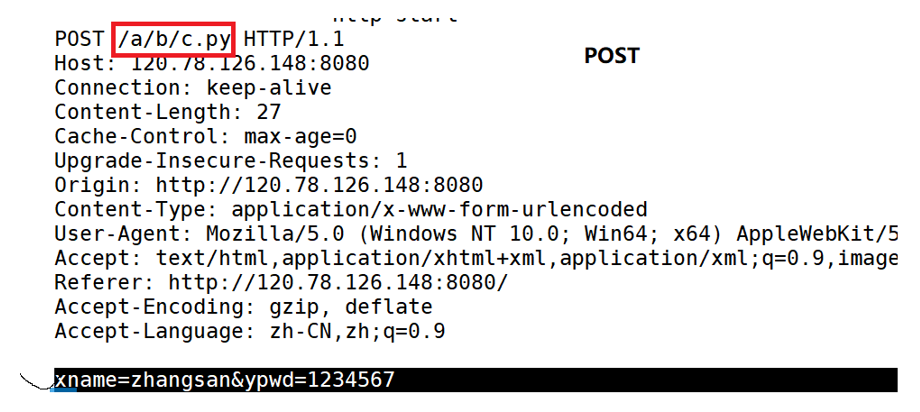
对于POST方法,浏览器不会把提交的参数放在url中,会放在body部分,然后浏览器上端的就不会有参数(用户名和密码)

那对于其他的方法重要吗???有必要学吗???
其实没必要,我们只需要根据url中的?前面是申请的资源,后面是参数
有些情况可能是c++编写我们的服务器,而后端处理数据可以交给python等语言
通过url传参,url?前面可以告诉我们访问什么资源,?后面传参,最后程序执行完
我们在构建响应返回出去
对于这个方法我们可以构建一个哈希map,然后把全部的方法都存进去,形成一个string-func_t的kv模型,未来客户端只要传一个string(解析url),就可以返回一个func_t方法,这就叫功能路由
讲解状态码301和307
有时候我们需要进行跳转页面,比如你有两个网站,一个是以前开发的,后面又做了一个新的,但是大家都是只知道旧的,并且旧的客户很多,你需要把旧的移到新的
此时就需要重定向
301:永久重定向,资源 “永久搬家” 了(比如旧网址废弃,换成新网址);浏览器会永久缓存这个重定向关系(下次再访问旧地址,直接跳新地址,不会再问服务器)。
307:临时重定向,资源 “临时搬家”(比如服务器维护,临时把请求转到备用服务器);浏览器不会缓存这个重定向关系(每次访问旧地址,都会先问服务器 “要不要重定向”)。
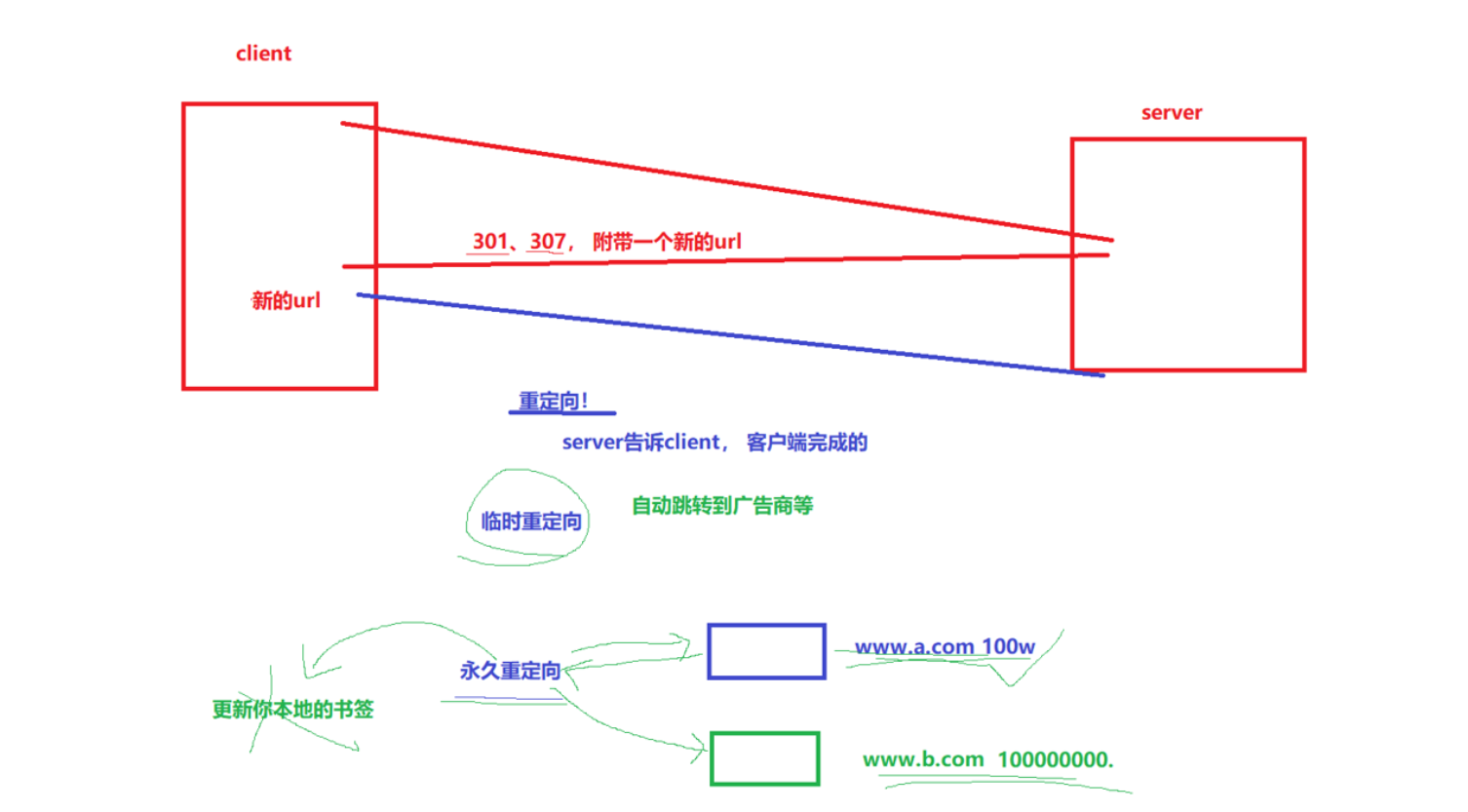
构建响应的时候有一个字段Location
Location | 重定向的目标地址 | Location: https://www.new-example.com(配合 301/302 重定向) |
长链接
场景:以前的http1.0其实频繁的请求没问题,因为图片啊啥的都很小,但现在不一样,图片大,频繁的请求就慢,每次都要建立链接去申请资源,所以http请求就发展,为了减少tcp面向连接频繁创建连接的问题------>长连接技术,也就是用同一条链接,当你请求完一个之后不释放,还接着用这个链接请求
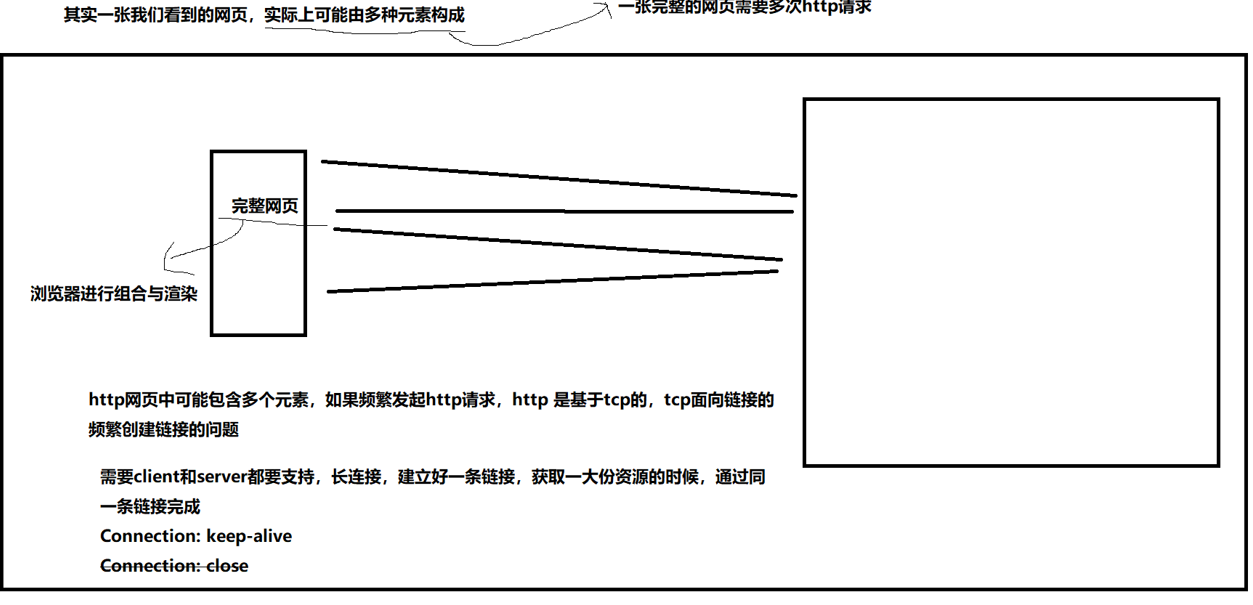
Connection: keep-alive是支持长连接,只有服务器返回给客户端说支持,客户端也要告诉服务器支持,双方协商都支持才可以,close是短链接
会话保持
现象:比如你登录bilibili时你已经登录过了,然后在新建一个哔哩哔哩在登这时候就不用扫码它已经记住你了,即使你关掉浏览器,在重新打开哔哩哔哩也可以记住,但换一个浏览器就不认识了,只要你在同一个浏览器当中就记住
http的定位是超文本传输,也就是什么资源都可以从服务器中拉取到本地
由于http协议是无状态的,也就是不会记录你以前的请求,比如你这次请求登录,下一次请求查订单,服务器默认不知道这两个请求是同一个用户发的,http根本不记录用户的登录状态然后维护起来,http不猜测也不记录
会话保持” 是 ** 让服务器 “记住用户状态”** 的技术(比如用户登录后,后续请求不用重复输入账号密码),核心解决 “HTTP 是无状态协议” 的痛点
Cookie 是实现浏览器端状态存储的核心技术,也是会话保持的基础 —— 简单说,它是「服务器下发给浏览器、浏览器自动保存并随后续请求携带的小型文本数据」,用来解决 HTTP 无状态的问题。
- 用户首次登录:
- 浏览器发送
POST /api/login请求,携带账号密码;- 服务器验证通过后,生成
Set-Cookie响应头(比如Set-Cookie: sessionid=abc123; Path=/; HttpOnly)(服务器可以通过这个字段控制控制 Cookie 的有效期、作用范围、安全性,常用属性),返回给浏览器;- 浏览器处理:
- 自动解析
Set-Cookie头,把sessionid=abc123保存到本地;- 用户后续请求:
- 浏览器访问该域名下的任意路径(比如
/api/userinfo),会自动在请求头里加Cookie: sessionid=abc123;- 服务器识别用户:
- 解析请求头里的 Cookie,通过
sessionid找到对应的用户信息,确认 “这是已登录用户”。
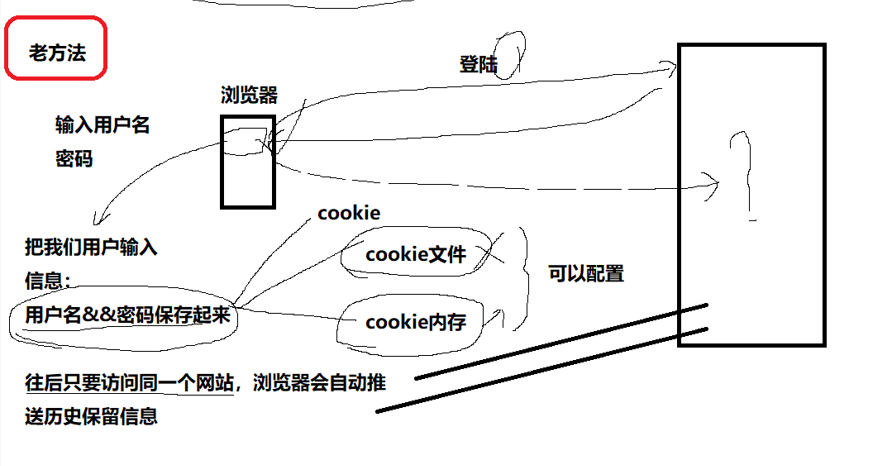
浏览器是一个进程,你关闭浏览器就相当于关闭进程
如果是cookie内存,那你的进程关闭,cookie就没了,你存储的信息就没了,下一次还需要登录
如果是cookie文件,进程关闭不影响文件,下一次启动还会有
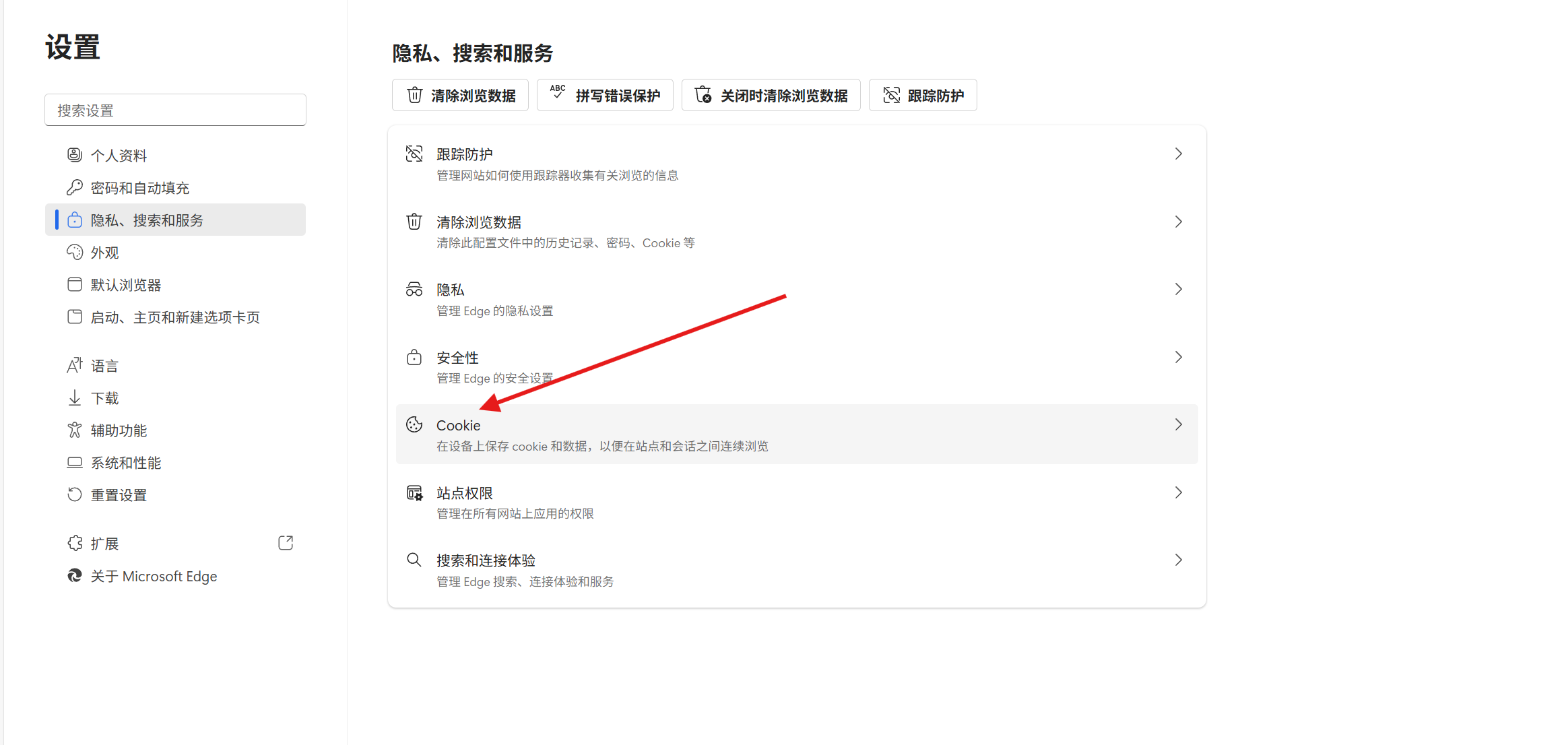
以下是实验,先登录记录cookie,然后删掉cookie,再接着跳转页面
已经登录过
删除cookie
但是此时发现跳转网页看视频,不会弹出来登录信息,这个原因的本质是不只是cookie这种验证方式,b站还做了很多种验证方式
比如B 站 Web 端登录后,除了下发普通登录 Cookie,还会返回
refresh_token字段并由浏览器相关机制存储。这个refresh_token相当于 “Cookie 刷新凭证”,有效期比普通 Cookie 更长。当你手动删除 Cookie 后,B 站网页会通过前端逻辑检查 Cookie 状态,若发现 Cookie 缺失或失效,会自动调用专门接口,用保存的refresh_token重新获取新的 Cookie。在你跳转网页的短时间内,这个刷新流程会静默完成,所以你察觉不到需要重新登录。还有很多种情况,这个取决于他们是如何处理的
可以找一些小网站,小网站就不会有多种方式,博主尝试csdn是会重新登录的,大家试试
cookie信息泄漏问题
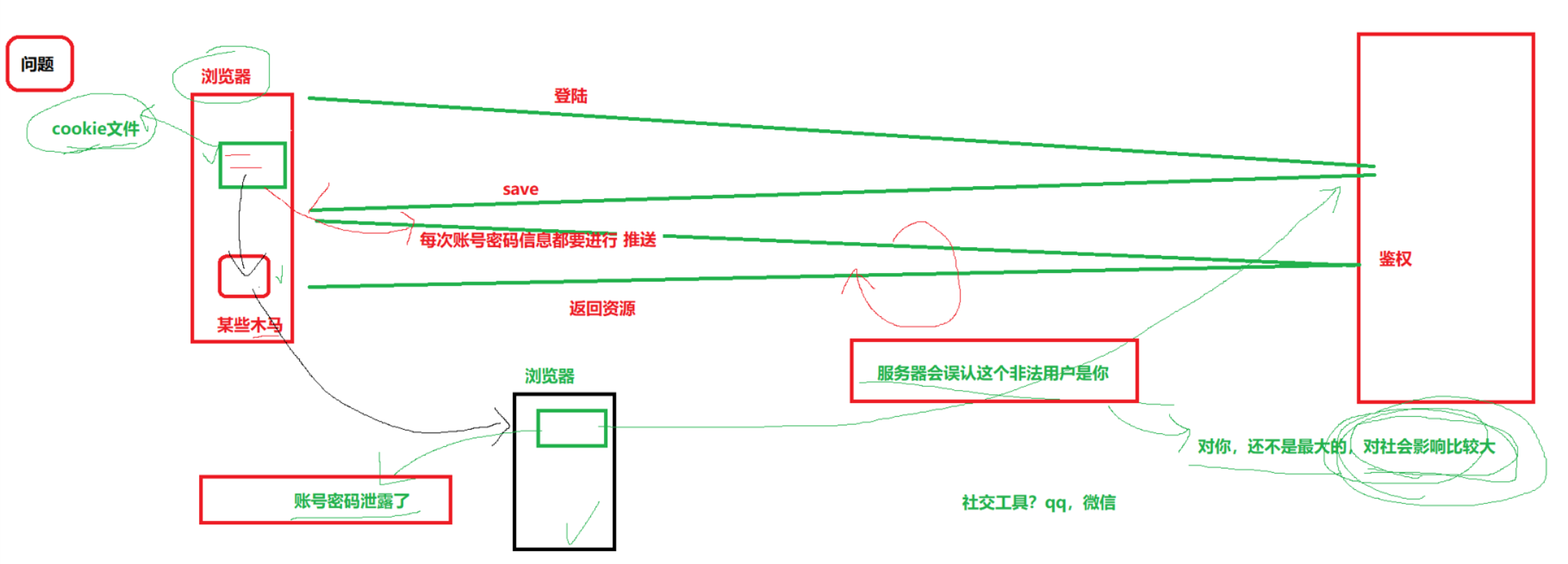
如果cookie文件当中存储了账户和密码,此时就会很危险,如果中了木马病毒,账户密码泄漏,非法用户就可以使用你的cookie去登录服务器,服务器无法判断是非法用户
如何解决这个因为中了木马病毒而导致信息泄漏问题???
不是因为cookie文件,是因为我们把隐私信息放在了客户端,不要觉得自己的安全意识高,用户对自己的信息的保护能力是有限的(qq号被盗就是因为有些人点击了一些非法链接,下载了木马病毒)
解决方案:不要把信息放在客户端,把信息放在服务器
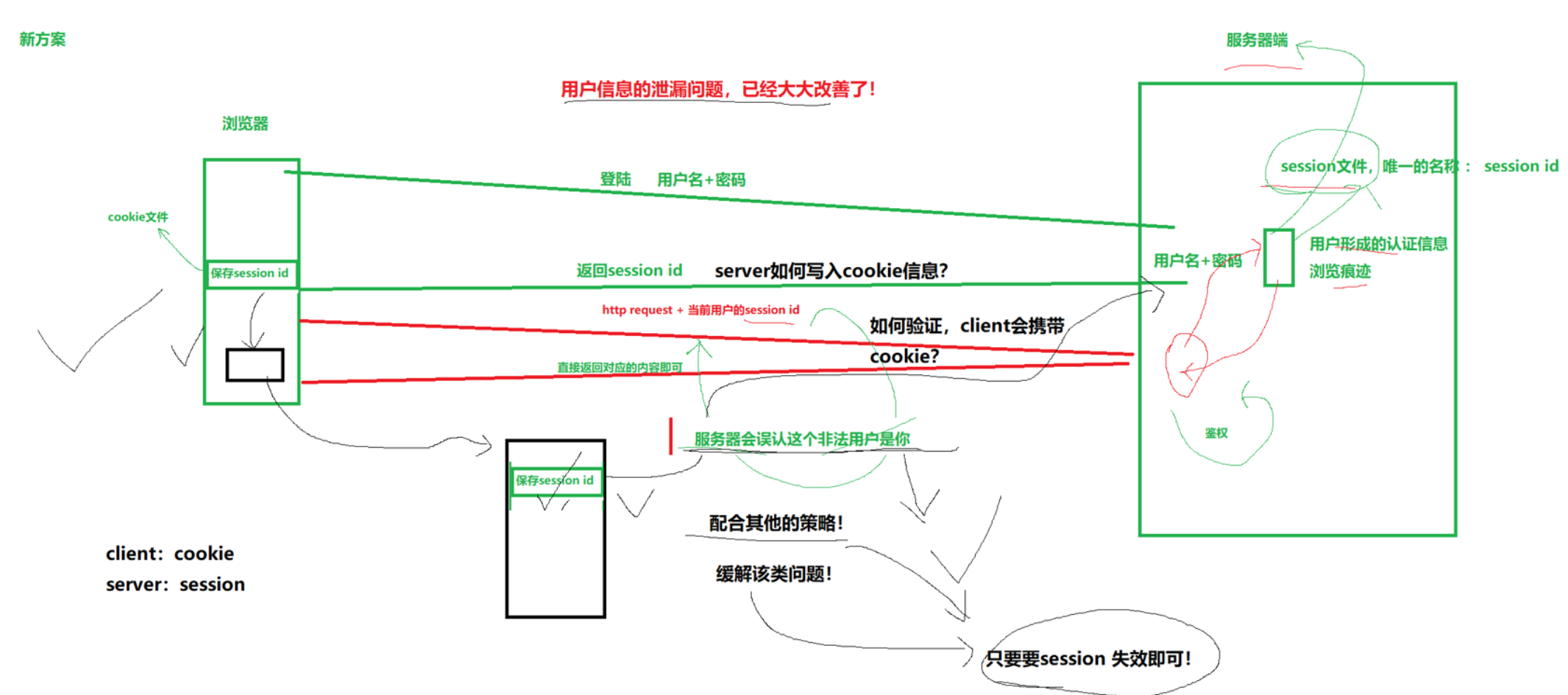
流程:
客户端发送用户名+密码去登录,服务器收到请求之后核对(查询数据库),错误返回失败,正确就存储,随机生成一个sessionid,这个id和用户信息绑定,然后存储在一个session文件
然后给客户端返回Set-Cookie:sessionid,后续浏览器解析这个字段,然后把sessionid存储在浏览器的cookie文件当中,跳转页面的时候,浏览器直接把这个sessionid附带传给服务器,服务器会去session文件当中,去核对
解决问题:
解决了客户端明文存储账户和密码的问题,防止中了木马病毒之后,泄漏个人信息
但是如果依旧会被盗取sessionid,然后服务器依旧无法判断是否为非法用户
但区别在于:偷
sessionid的风险可控,偷明文密码的风险是毁灭性的sessionid被盗取,只能浏览个人主页或者发发消息等操作
密码被盗取,别人可以改你的密码,”永久掌控账户“
服务器防范措施:
sessionid被盗取,服务器也是有相应的措施的,比如ip对比,一旦发现异地登录就让你校验,一旦发现设备更改,比如之前用苹果17,一下子切换苹果11,比如用户操作习惯等等只需要让sessionid失效即可,Set-Cookie中有个字段Max-Age中可以设置id过期时间
实用小工具postman、fiddler、curl
Postman 是一款专门用于测试 HTTP/HTTPS API 的工具,简单说就是「模拟前端发送请求、验证后端接口是否正常工作」的利器,是后端开发、测试、前端联调的必备工具。
我们可以不用先写前端页面,直接使用这个工具去测试我们的接口是否可以正常使用
Fiddler 是一款免费的 HTTP/HTTPS 抓包工具,核心作用是「监听、捕获、修改客户端与服务器之间的所有 HTTP 流量」—— 简单说,它是夹在浏览器 / 客户端和服务器之间的 “中间人”,能清晰看到请求和响应的每一个细节,比 Postman 更侧重 “流量分析 / 调试”,和 Postman 互补使用。
注意:fiddler是充当了中间层,也就是代理,浏览器先发给fiddler,fiddler先解析拿到之后在转发给服务器,因为这个fiddler是在你的本地机器上,所以能够抓取你测试机器发出去的数据包
这两款软件可以自行下载研究
curl 是一款命令行形式的 HTTP / 网络工具(也有库版本 libcurl),核心作用是「在终端里发送 HTTP/HTTPS 请求、传输数据」,无需图形界面,是后端开发 / 运维调试接口、自动化脚本的必备工具 —— 和 Postman(可视化界面)、Fiddler(抓包)定位不同,但能完美互补

















 3193
3193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









