



这是一道难度为一的题目。看题目就知道大致内容了,这个pyc文件是破损的,你能帮我恢复吗?
首先pyc文件里面存放的是字节码,python是一门解释型语言,他会先把.py文件转化成字节码,字节码存储在内存当中的PyCodeObject对象中,然后交给字节码虚拟机,由虚拟机一条一条的执行字节码指令。在程序解释时,Python解释器会把PyCodeObject写入.pyc文件中,在磁盘中保存,当这个程序再次运行时,就会先在磁盘中找,这样就变快了。这个原理就是这样,我们只需要知道,这个pyc文件是字节码文件,我们是无法直接看懂里面的内容的。
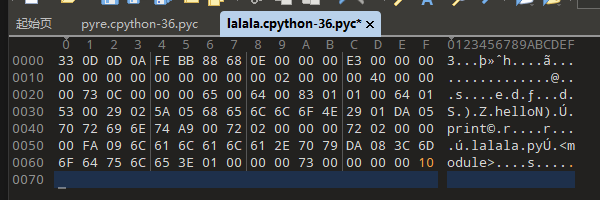
回到这个文件
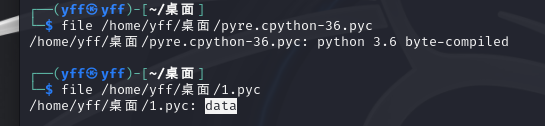
看到后面是-36,这个应该是python3.6环境下的,我们可以丢进kali里面用file命令语句来看看有什么内容,如果是出现了python 3.6 byte-compiled,这样的字眼,我们可以知道,这是在3.6环境下的完整的pyc文件。我们这道题目是不完整的,所以会出现这样data这样的字眼
那么我们就要修复文件喽,pyc文件的恢复基本是文件头部的Magic部分(就看前16个字节就好),呃,我遇到的题目都是这样,目前来说。所以我就顺着这个思路走下去。这是一个python3.6环境的文件,每个不停版本的python,他的头都是不一样的。一般来说,前2个字节是版本信息,第3到第4是0D和0A,第5到第8是标志位,决定后面的9到16是什么意思。如果5到8是零的话,那么第9到12是时间戳,13到16是文件大小。
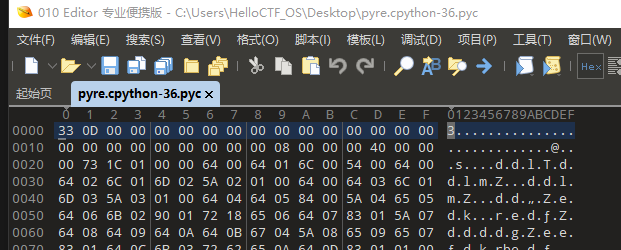
我们用010editor查看文件,可以看到,这里面前16个文件,很多都是零。那么我们就要知道一个正常的pyc的前16个字节是什么样子的。我这边想到的办法是,直接在对应版本自己写一个python文件再转化为pyc文件,查看头。但是题目有很多,这种python版本也有很多。我直接用的是anaconda来帮我管理python环境,有一篇博客讲的就很清楚,我引用在文章最后面。
![]() 这是我写的一个打印出“hello”的python文件,是在3.6环境下的。让我们在cmd中python -m py_compile 文件名.py,就会出现一个__pycache__文件夹,里面有你的pyc文件。我们在010editor中打开这个文件。
这是我写的一个打印出“hello”的python文件,是在3.6环境下的。让我们在cmd中python -m py_compile 文件名.py,就会出现一个__pycache__文件夹,里面有你的pyc文件。我们在010editor中打开这个文件。
前16字节明显完整多了,这边的话,其实把我这前16个字节全部换过去就行了的,我也试了,只要前4个字节和后面4个字节(在前16字节之间)和我这个一样就可以编译出来。
1.用uncompyle6:可以找找博客,这是在githup上面下载的。
直接uncompyle6.exe 文件名.pyc 这是直接在cmd中输出.py文件
或者uncompyle6.exe 文件名.pyc > 1.py 就会在本文件夹中出现一个1.py的文件
2.用pycdc:这边建议可以在kali上面安装,就会方便很多。如果是windows比较麻烦。
pycdc的使用就很简单了 直接./pycdc 文件名.pyc就可以了,就会出现一个.py文件
# uncompyle6 version 3.9.1
# Python bytecode version base 3.6 (3379)
# Decompiled from: Python 3.8.2rc2 (tags/v3.8.2rc2:777ba07, Feb 18 2020, 09:11:15) [MSC v.1916 64 bit (AMD64)]
# Embedded file name: pyre.py
# Compiled at: 2022-10-15 15:36:44
# Size of source mod 2**32: 609 bytes
from ctypes import *
from Crypto.Util.number import bytes_to_long
from Crypto.Util.number import long_to_bytes
def encrypt(v, k):
v0 = c_uint32(v[0])
v1 = c_uint32(v[1])
sum1 = c_uint32(0)
delta = 195935983
for i in range(32):
v0.value += (v1.value << 4 ^ v1.value >> 7) + v1.value ^ sum1.value + k[sum1.value & 3]
sum1.value += delta
v1.value += (v0.value << 4 ^ v0.value >> 7) + v0.value ^ sum1.value + k[sum1.value >> 9 & 3]
return (
v0.value, v1.value)
if __name__ == "__main__":
flag = input("please input your flag:")
k = [255, 187, 51, 68]
if len(flag) != 32:
print("wrong!")
exit(-1)
a = []
for i in range(0, 32, 8):
v1 = bytes_to_long(bytes(flag[i:i + 4], "ascii"))
v2 = bytes_to_long(bytes(flag[i + 4:i + 8], "ascii"))
a += encrypt([v1, v2], k)
enc = [
4006073346L, 2582197823L, 2235293281L, 558171287, 2425328816L,
1715140098, 986348143, 1948615354]
for i in range(8):
if enc[i] != a[i]:
print("wrong!")
exit(-1)
print("flag is flag{%s}" % flag)
# okay decompiling pyre.cpython-36.pyc
这就是.py文件里面的样子。encrypt这个函数,就很明显了,有delta,有循环有异或,以及k列表里面刚刚好有4个数,可以确定是tea加解密了,如果看不出来的,需要去搜索这个加密,了解了才能知道。我们应该读完这段代码,就是有一定细节(反正我错了)要注意。这是3.6环境的python代码,所以L结尾的数字是以4字节int类型的。还有就是那两个有“ascii”的地方,由于bytes_to_long这成了大端模式,我们正常的python语言里用的是小端,这样反过来计算的话,我们在写脚本的时候要切换,或者要逆序得到的数据,这样才能出现正常的字符,不然会出现乱码。这边只是吧数组中的元素进行了大小端切换,所以我们只需要把元素进行逆序就好了。
然后就是语言的选择,我们既然以及知道要逆序代码, 数组中的元素每个都是int类型的4个字节,我们要的是字符串类型,也就是字符的这个char是一个字节,如果用的python这部分有点难处理,因为python很自由,内存不太严谨,所以我们选择c语言
#include <stdio.h>
#include<stdint.h>
void tea_my(uint32_t* v, uint32_t* k) {
uint32_t v0 = v[0];
uint32_t v1 = v[1];
uint32_t delta = 195935983;
uint32_t sum = delta * 32;
for (int i = 0; i < 32; i++)
{
v1 -= (v0 << 4 ^ v0 >> 7) + v0 ^ sum + k[sum >> 9 & 3];
sum -= delta;
v0 -= (v1 << 4 ^ v1 >> 7) + v1 ^ sum + k[sum & 3];
}
v[0] = v0;
v[1] = v1;
}
int main()
{
uint32_t k[4] = { 255,187,51,68 };
uint32_t enc[8] = { 4006073346, 2582197823, 2235293281, 558171287, 2425328816,
1715140098, 986348143, 1948615354 };
for (int i = 0; i < 8; i+=2)
{
tea_my(&enc[i], k);
}
char flag[32] = { 0 };
for (int i = 0; i < 8; i++)
{
flag[4 * i] = enc[i] >> 24;
flag[4 * i + 1] = (enc[i] >> 16) & 0xff;
flag[4 * i + 2] = (enc[i] >> 8) & 0xff;
flag[4 * i + 3] = (enc[i]) & 0xff;
}
for (int i = 0; i < 32; i++)
{
printf("%c", flag[i]);
}
}
对于函数部分,我们直接反着写就好了,tea语言的解密,主要是k数组里面的4个元素,还有enc中的元素,最重要的是传给函数tea_my的第一个参数,必须要是可以获取两个无符号的4字节的数,我们通篇也在使用uint32_t这个类型,函数里面异或的部分虽然复杂,但是完全不用看懂,直接抄就好了,后面的flag的值的取得就是通过>>操作符实现字节层面的逆序,这个在python中实现就有点困难了,最后代码运行,就可以得到flag了。
flag{Th1s_1s_A_Easy_Pyth0n__R3veRse_0}


















 3359
3359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









