




 本文探讨了中国教育体系的问题,指出高等教育与现实社会需求的脱节,导致部分专业毕业生就业困难。作者以自身经历为例,提出教育应更注重实践和通用技能的培养,并建议面临困境的学生及时调整方向。文章还分析了宏观经济形势,强调教育改革的必要性。
本文探讨了中国教育体系的问题,指出高等教育与现实社会需求的脱节,导致部分专业毕业生就业困难。作者以自身经历为例,提出教育应更注重实践和通用技能的培养,并建议面临困境的学生及时调整方向。文章还分析了宏观经济形势,强调教育改革的必要性。
文章目录
1、前言
1.1、现象
- 众多远山农村子弟,努力考学,却因专业天坑导致就业困难
- B乎上几乎所有专业都在劝退
- 阶级固化话题热议
- 不少重本理工科毕业生从事与本专业无关的工作,比如转行、销售
- 研究生同学 与
实验室经历了6年的爱情长跑,毕业后竟然被迫与实验室分手
1.2、受害
- 而本人亦是劝退专业的巨大受害者之一,科研无路,毕业失业,被迫转行。
1.3、理想破灭
- 娃时的科学家梦想,中学时期对量子力学的执着,一切美好追求终在大学幻灭!
- 不禁让我思考:读书有什么用?
2、教育是什么?
- 狭义上指 专门组织的学校教育;
- 广义上指 影响人的身心发展的社会实践活动。
2.1、初等教育
- 没有专业、职业指向性的基本教育。
- 包括:幼儿教育、小学教育、普通中等教育
2.2、中等教育
- 在初等教育基础上继续实施的教育。
- 包括:全日制普通中学(主要)、中等职业学校、中等专业学校、中等师范学校、中等技工学校、职业中学、成人中专、职业高中、成人高中…
2.3、高等教育
- 完成中等教育的基础上进行的专业教育和职业教育,是培养高级专门人才和职业人员的主要社会活动。
- 包括:以高层次的学习与培养、教学、研究和社会服务为其主要任务和活动的各类教育机构
2.4、中国教育
- 近现代中国教育是从西方引进,而西方而那套数理化生源自第二次工业革命,主要服务于工业制造。
- 然鹅二战后又经历了2次巨大的技术革命【计算机和互联网】,教育体系却难以跟上,尽管在90年代已经看到计算机课程引进小学,但实际上因为设备昂贵,很多地区而难以实现,不少90后到了大学才开始学习如何开关机!
- 对于小初高教育,我认为中国是成功。
填鸭式教育成功给全民扫盲,也让寒门子弟有跨越阶级的机会。
相比之下,欧美教育不能全民扫盲,而且还加剧阶级固化。
3、中国大学有多垃圾?
- 中国小初高成功地将勤奋学习的山村学子送上大学,而中国大学却把辛辛学子打回原形
- 教师与社会脱节:教师只管自己饭碗,懂什么教什么,更甚者限制学生自由!
- 大学教材垃圾:
1、密密麻麻的文字,讲解没有深入浅出;
2、原理不说清,导致学生只能靠死记硬背,尤其医学类;
3、不重实践;
4、不重视数学:不少理工科专业竟然把【线代、概率统计、离散数学】砍掉;
5、部分专业天坑(生化环材医),通用性低,导致转行困难。
4、分析当前宏观经济
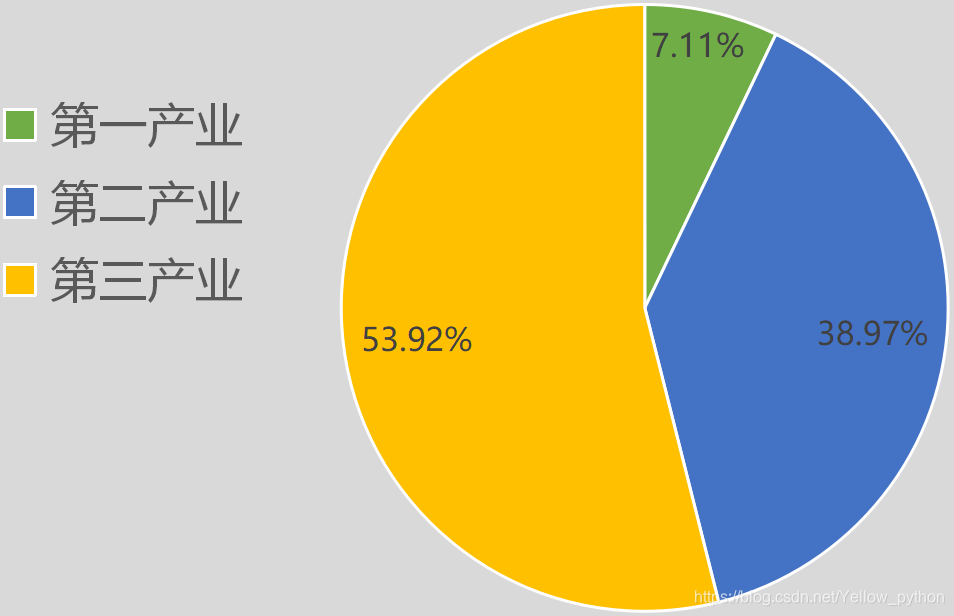
- 2019年三次产业GDP占比,显然制造业占比不高,服务业占比过半,反映目前社会需求
- 由此可见我们当年那套【第二次工业革命】留下来的教育体系有bug,不能满足目前社会的产业结构
- 2017年10月18日十九大报告中强调,我国社会主要矛盾已经转化为人民日益增长的美好生活需要和不平衡不充分的发展之间的矛盾,而不是娃时那套人民日益增长的物质文化需要同落后的社会生产之间的矛盾。
5、出路
5.1、选错专业怎么办?
- 在错误的方向上越是努力,沉没成本越大,越难抽身。
除非家境优渥及信念坚定,否则要及早转行。
5.2、先博后渊
- 选择比努力更重要。只有博学才能有更多选择。
- 多去书店或图书馆,博览群书:https://blog.youkuaiyun.com/Yellow_python/article/details/80920008
5.3、优先学习通用技能
- 小初高的语数英物化生政史地是根基。
- 在此基础上,计算机、经济、金融、会计、房地产、建筑、工商管理、医学常识…
- 目前主流:IT、金融、房地产
5.4、实践出真知
- 正所谓:春宵一刻值千金,绝知此事要躬行。
- 注重实践,同时也要结合理论。
结语:
世界本不公平,我愿尽我之力 减少不公平


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











