






学习笔记3
关于训练神经网路的诸多技巧Tricks(完全总结版)-腾讯云开发者社区-腾讯云 (tencent.com)
(1)关于用gpu跑程序的步骤
有英伟达的驱动的前提下:
1)创建虚拟环境:2023最新pytorch安装教程,简单易懂,面向初学者(Anaconda+GPU)-优快云博客
2)nvidia-smi查看自己的电脑配置选择合适的CUDA版本
3)下载cuda版本的pytorch:https://pytorch.org/
4)检查
import torch
torch.cuda.is_available()
5)代码部分的实现:
1.申明用GPU
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
2.把model放到GPU上
net= Net ()
net.to(device)
3.把数据和标签放到GPU上
inputs, labels= inputs.to(device),labels.to(device)
(2)图像的数据预处理
1)类型:
-
爬取或搜索引擎采集:图像进行去重、删除无效样本等操作,
-
自行拍摄、实验提取:可能需要根据实验要求进行一些删除、增加的处理
2)确保:
1)全部样本的尺寸和通道是一致的
2)图像最终以Tensor形式被输入卷积网络
3)图像被恰当地归一化,即让像素值减去一个数(默认为均值)、再除以另一个数(默认是标准差)
4)方法:
-
Compose transforms专用的,类似于nn.Sequential的打包功能,可以将数个transforms下的类打包
-
CenterCrop 中心裁剪
-
Resize 尺寸调整,注意和裁剪区分开,这个与原图较为相似的信息,但图片尺寸会得到缩放。
-
Normalize 归一化,有两个参数,一个是mean,另一个是std,分别代表需要减去的值和需要除以的值
-
ToTensor 转化为张量
代码实现的例子:
from torchvision import transforms
# 定义图像预处理的组合方法
transform = transforms.Compose([
transforms.CenterCrop(100), # 中心裁剪到100x100大小
transforms.Resize((64, 64)), # 将图像调整为64x64大小
transforms.ToTensor(), # 转换为张量,并归一化到[0, 1]
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 归一化,将张量的值从 [0, 1] 缩放到 [-1, 1]
])
5)区分:
- 对表格数据而言,归一化是以特征为单位进行的,每个特征会单独减去自己这个特征的均值,再除以这个特征的标准差。
类transforms.ToTensor()已经带有归一化的功能:这个类会按照最大值255,最小值0对图片数据进行归一化,将所有图像的像素值压缩到[0,1]之间
- 对任意图像而言,归一化都是以通道为单位进行的,每个通道上的全部样本的全部像素点会减去通道像素的均值,再除以通道像素的标准差图像,在被归一化前必须被转化为Tensor。
如果输入transforms.ToTensor() 的数据原本是二维表,那其最大值可能会远远超出255,那经过归一化后数字范围也不会在[0,1]之间。为了避免这种情况的出现,我们可以提前将二维表的数据压缩到[0,255]之间
(3)数据增强
代码实现:
from torchvision import transforms
scale_range = (0.9, 1.1)
rotation_range = 10
translation_range = (0.1, 0.1)
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量,并归一化到[0, 1]
transforms.Normalize((0.5,),(0.5,))
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(degrees=rotation_range), # 随机旋转
transforms.RandomAffine(0, scale=scale_range), # 数据随机缩放
transforms.RandomAffine(0, translate=translation_range), # 随机平移
])
(4)利用train_test_split进行训练集、验证集、测试集的随机划分
例子:
数据形式为文本,且形式为数据和标签在一起
# 从总的数据集中(有规律)选取固定大小部分作为训练集验证集测试集的总和。如此处选取总数据集的前10000句作为需要使用的数据集。
# 两次使用train_test_split()将选取的固定大小的数据集,按照一定的比例,如8:1:1随机划分为训练集,验证集,测试集。
# 并分别将划分好的数据集进行写入到固定目录下
from sklearn.model_selection import train_test_split
def write_data(datapath, line_sen_list):
'''
datapath: 需要写入的文件地址
line_sen_list: 需要写入的文件内容行列表
'''
with open(datapath, 'w', encoding = 'utf-8') as o:
o.write(''.join(line_sen_list))
o.close()
def main():
raw_data_path = './output_s044_final_final_final.txt'
train_data_path = './train_80000.txt'
validate_data_path = './validate_10000.txt'
test_data_path = './test_10000.txt'
line_sen_list = []
with open(raw_data_path, 'r', encoding = 'utf-8') as f:
lines = f.readlines()
# 按某种规律选取固定大小的数据集
for line in lines[0:100000]:
line_sen_list.append(''.join(line))
f.close()
label_list = [0] * 100000 # 由于该数据形式为文本,且形式为数据和标签在一起,所以train_test_split()中标签可以给一个相同大小的0值列表,无影响。
# 先将1.训练集,2.验证集+测试集,按照8:2进行随机划分
X_train, X_validate_test, _, y_validate_test = train_test_split(line_sen_list, label_list, test_size = 0.2, random_state = 42)
# 再将1.验证集,2.测试集,按照1:1进行随机划分
X_validate, X_test, _, _ = train_test_split(X_validate_test, y_validate_test, test_size = 0.5, random_state = 42)
# 分别将划分好的训练集,验证集,测试集写入到指定目录
write_data(train_data_path, X_train)
write_data(validate_data_path, X_validate)
write_data(test_data_path, X_test)
if __name__ == '__main__':
main()
(5)shutil.copyfile复制文件到另一个文件夹中
1)shutil.copyfile(file1,file2)
file1为需要复制的源文件的文件路径,file2为目标文件的文件路径+文件名
src_file = 'C:\\A\\0.png'
dst_file = 'D:\\B\\1.png'
shutil.copyfile(src_file,dst_file)
2)shutil.copy(file,folder)
和上面的区别就是这个复制完后文件的名字可以一样
dst_file = './test_copy2'
src_file = './test_copy1'
current_list = glob.glob(os.path.join(src_file,'*'))
# 使用 glob.glob() 函数获取源文件夹中所有文件的路径,并将它们存储在 current_list 列表中
for x in current_list:
shutil.copy(x,dst_file)
补充:
巧用Python:用Python批量复制文件,方法有9种,方便快捷-优快云博客
(6)loss曲线诊断神经网络模型
1)相关的资料:
如何根据训练/验证损失曲线诊断我们的CNN-腾讯云开发者社区-腾讯云 (tencent.com)
2)情况出现:
过拟合的情况:
- 训练损失持续下降,验证损失开始上升
- 训练损失和验证损失均下降,但两者之间的差距越来越大
理想情况:
- 训练损失和验证损失均下降,且两者趋于平稳且差距较小
3)可能会出现的问题(图像分析):
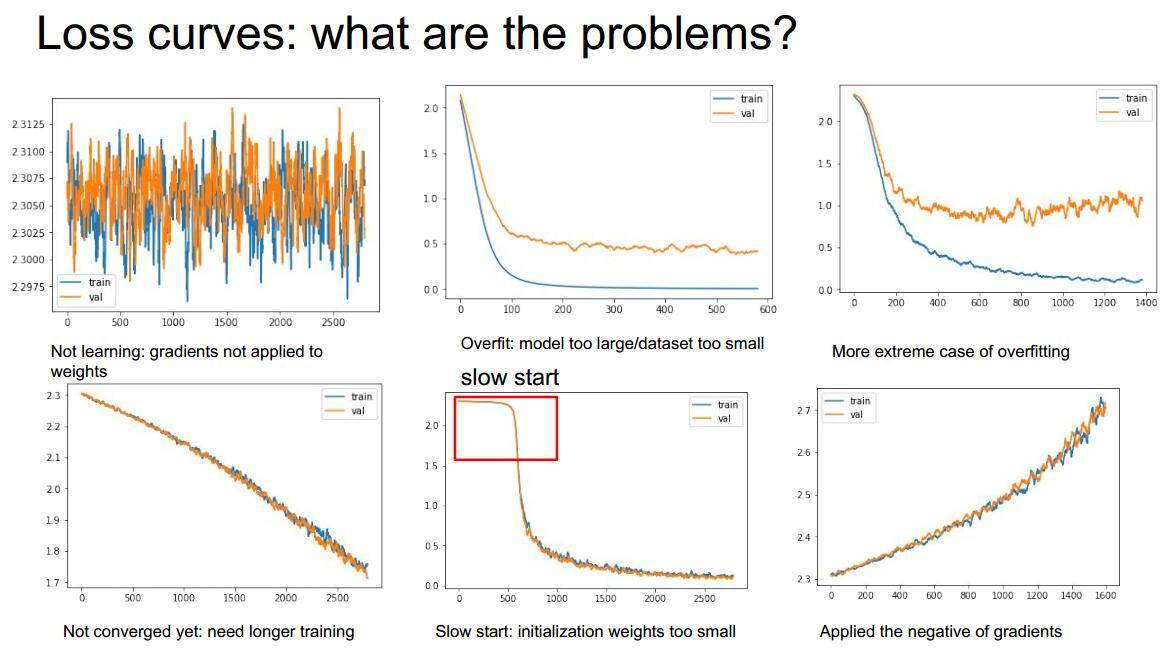
分析(从左到右):
- 图1 :显然的学习不到任何东西(可以适当smooth一下看的清楚一点);
- 图2:是典型的过拟合现象;
- 图三:更严重的过拟合;
- 图四:等训练的epoch结束的时候,最右边的损失值还是下降的趋势,说明还没训练足够;
- 图五:开头经历了比较长的iterate才慢慢收敛,可能初始化权重太小,或者数据集中含有不正确的数据;
- 图六:越学习损失值越大,很有可能是“梯度向上”了
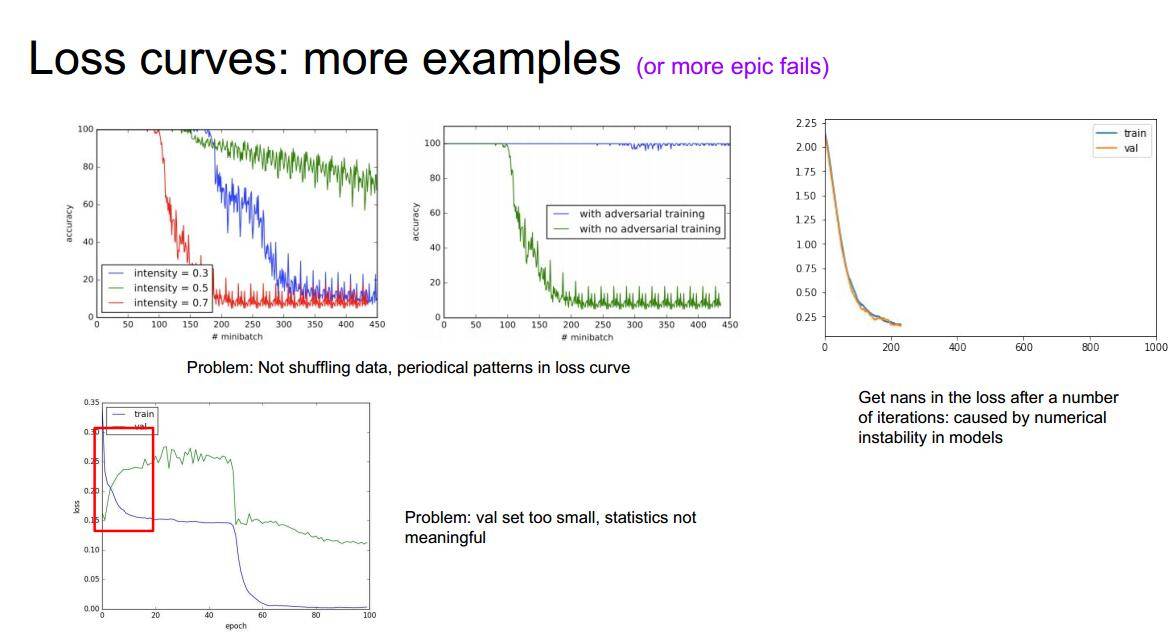
补充
左上一和二:没有对数据集进行洗牌,也就是每次训练都是采用同一个顺序对数据集进行读取;
右上一:训练的过程曲线消失,遇到了nan值,很有可能是模型设置的缘故;
最后一个图显示较小比例的val集设置会导致统计不准确,比较好的val设置比例是0.2。
(7)dataset和dataloader
【pytorch】shuffle,dataloader和enumerate - 知乎 (zhihu.com)
PyTorch学习笔记(4)–DataLoader的使用-优快云博客
(8)Batch Normalization
1)参考介绍:
什么是批标准化 (Batch Normalization) - 知乎 (zhihu.com)
Batch Normalization:批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法
2)背景:
举一个例子理解:比如x1=1,x2=20,w=0.1,那么输出x1 * w=0.1,x2 * w=2,当经过激活函数比如tanh之后会变成接近1和0.1, 接近于 1 的部分已经处在饱和阶段,BN就可以来解决问题。
3)原理:
把数据分成小批小批进行随机梯度下降, 而且在每批数据进行前向传递的时候, 对每一层都进行 normalization 的处理,它被添加在每一个全连接和激励函数之间。
4)效果:

没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 还进行了反 normalize 的手续.
(9)经典网络
——> lenet-5
参数大约有6万 5层
详细和代码见:
卷积神经网络:LeNet-5_lenet5卷积神经网络结构-优快云博客
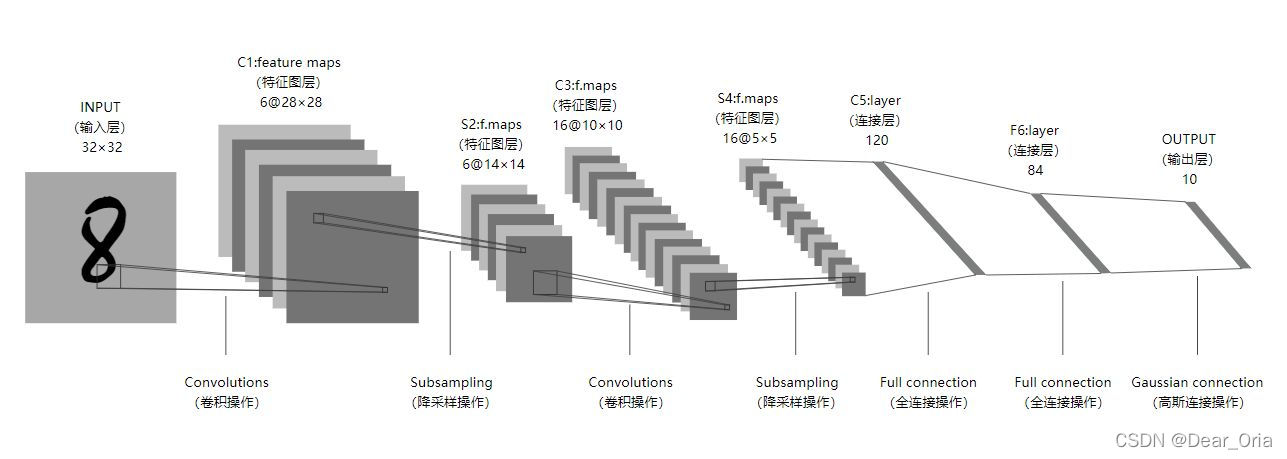
——> Alexnet
使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层
特点:
- 和letnet-5相比,它的参数要大得多,大约有6000万,而且它里面还用到了relu激活函数,采用修正线性单元(ReLU)的深度卷积神经网络训练时间比等价的tanh单元要快几倍
- 以往池化的大小PoolingSize与步长stride一般是相等的,这里反而重叠,类似于卷积,此操作可以有效防止过拟合的发生
- Dropout:全连接层中去掉了一些神经节点,将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合
- 对比letnet,有更深的网络深度,有利于性能的提高

c1 卷积–>ReLU–>池化 –> c2 卷积–>ReLU–>池化–> c3卷积–>ReLU–> c4 卷积–>ReLU–> c5 卷积–>ReLU–>池化–>
Fc6全连接–>>ReLU–>Dropout–> Fc7全连接–>>ReLU–>Dropout
——> VGG -16
介绍:层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。13个卷积层和5个池化层,3个全连接层。它没有很多的参数,是专注于构建卷积层的简单网络
- 卷积-卷积-池化-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接
- 通道数分别为64,128,512,512,512,4096,4096,1000。卷积层通道数翻倍,直到512时不再增加。通道数的增加,使更多的信息被提取出来。全连接的4096是经验值,当然也可以是别的数,但是不要小于最后的类别。1000表示要分类的类别数。
使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力,池化层的池化核为2*2
特点 :图像缩小的比例和信道数量增加的比例是有规律的
卷积可以代替全连接,适用各种尺寸的图片
只用到3x3的卷积层和2x2的池化层,比较简洁美观
缺点: 即训练时间过长,调参难度大。 需要的存储容量大,不利于部署(就是将训练好的VGG16模型应用到实际场景中
(10)残差网络
背景:
- 梯度消失:
很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
- 网络退化:
假设一个只需要18层就能达到最优性能的模型有34层,我们希望模型能够自动将多余的16层学习成恒等映射,即这些层的输出与输入相同。但模型很难学习将这些层学习成恒等映射的参数,而可能会学习到与恒等映射不相符的参数,导致性能下降。这就是所谓的网络退化现象,而不是过拟合所导致的。
残差网络Resnets
思想就是背景所说的,希望冗杂多余的层学习恒等映射
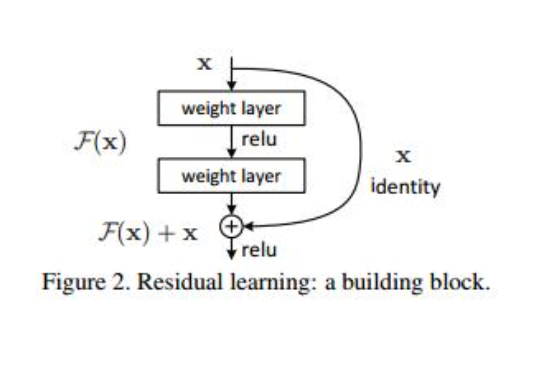
增加了 x 项,那么该网络求 x 的偏导的时候,多了一项常数 1(对x的求导为1)
在第二层进行线性变化激活之前对F(x)添加了x的输入值,这条路径叫做shortcut
(10)残差网络
背景:
- 梯度消失:
很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
- 网络退化:
假设一个只需要18层就能达到最优性能的模型有34层,我们希望模型能够自动将多余的16层学习成恒等映射,即这些层的输出与输入相同。但模型很难学习将这些层学习成恒等映射的参数,而可能会学习到与恒等映射不相符的参数,导致性能下降。这就是所谓的网络退化现象,而不是过拟合所导致的。
残差网络Resnets
思想就是背景所说的,希望冗杂多余的层学习恒等映射
增加了 x 项,那么该网络求 x 的偏导的时候,多了一项常数 1(对x的求导为1)
在第二层进行线性变化激活之前对F(x)添加了x的输入值,这条路径叫做shortcut

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









