






Llama 3.2-Vision 是一种多模态大型语言模型,有 11B 和 90B 两种大小,能够处理文本和图像输入,生成文本输出。该模型在视觉识别、图像推理、图像描述和回答图像相关问题方面表现出色,在多个行业基准测试中均优于现有的开源和闭源多模态模型。
本文将介绍开源的 ollama-ocr工具,它默认使用本地运行的 Llama 3.2-Vision 视觉模型,可准确识别图像中的文字,同时保留原始格式。
https://github.com/bytefer/ollama-ocr
Ollama-OCR 的特点
-
使用 Llama 3.2-Vision 模型进行高精度文本识别 保留原始文本格式和结构
-
支持多种图像格式:JPG、JPEG、PNG
-
可定制的识别提示和模型
-
Markdown 输出格式选项
Llama 3.2-Vision 应用场景
识别手写文本
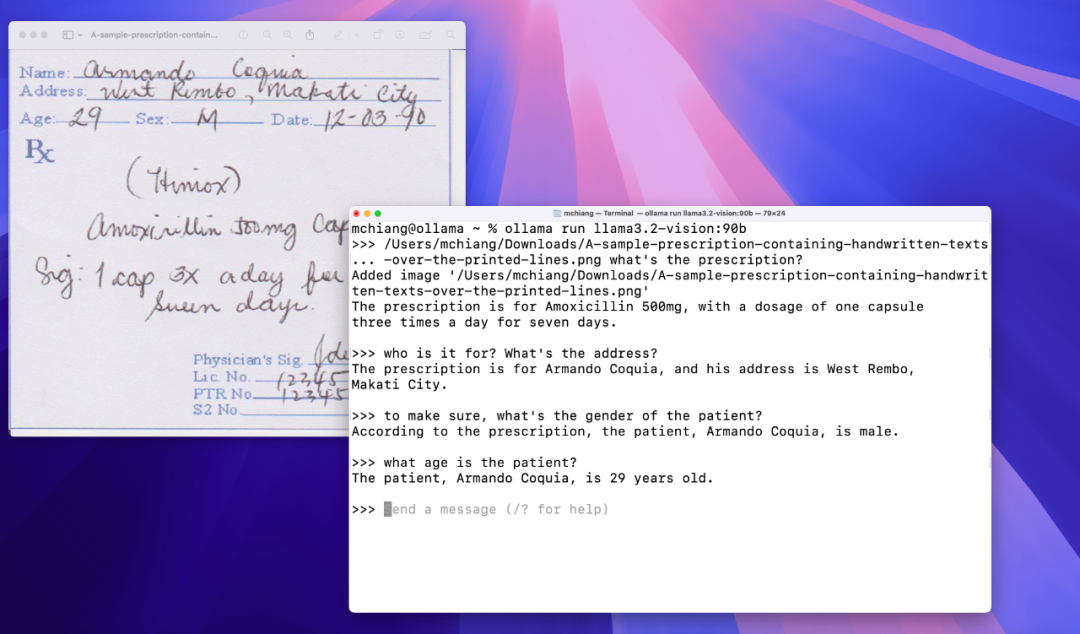
OCR 识别
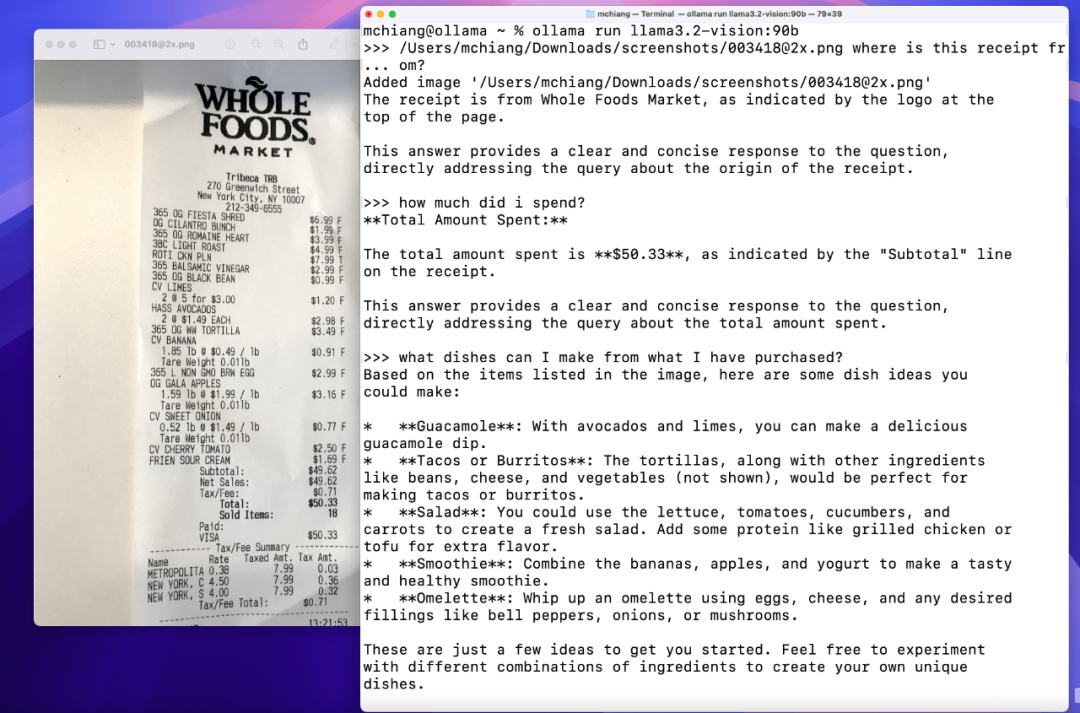
图片问答
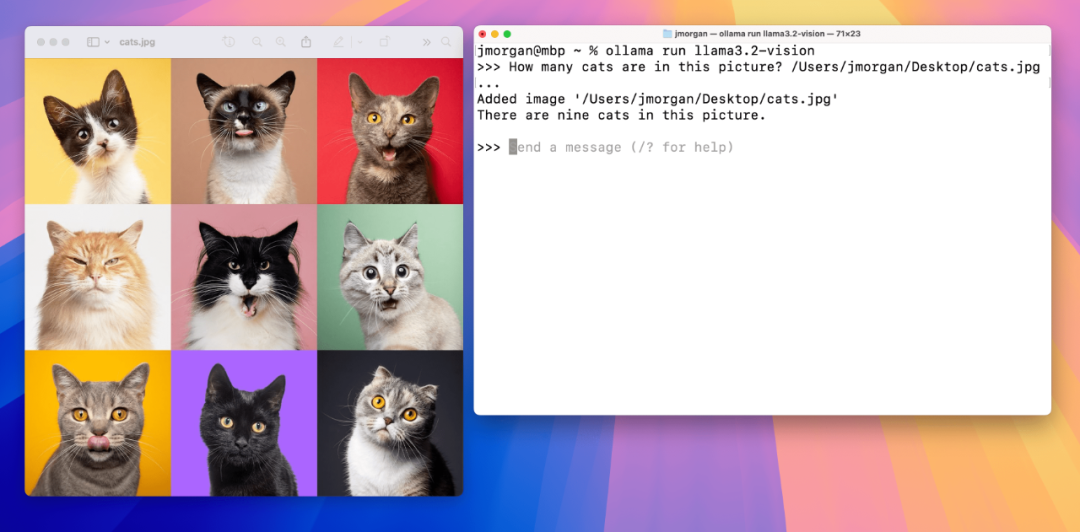
配置环境
安装 Ollama
在开始使用 Llama 3.2-Vision 之前,您需要安装 Ollama[2],这是一个支持在本地运行多模态模型的平台。请按照以下步骤安装:
1. 下载 Ollama:访问 Ollama 官方网站,下载适用于您操作系统的安装包。
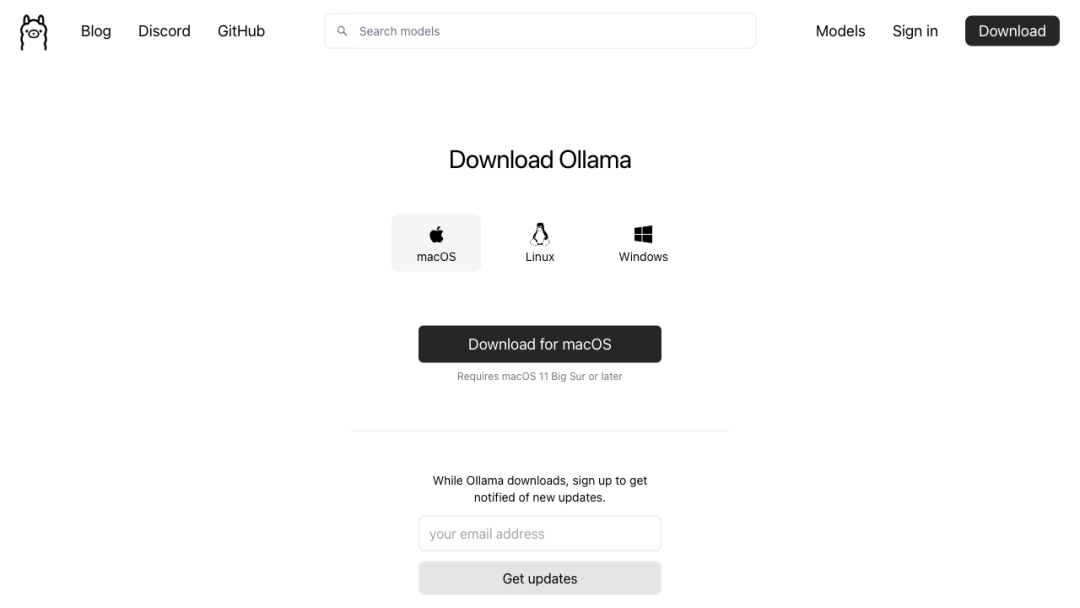
2. 安装 Ollama:根据下载的安装包,按照提示完成安装。
安装 Llama 3.2-Vision 11B
安装 Ollama 后,可使用以下命令安装 Llama 3.2-Vision 11B[3]:
ollama run llama3.2-vision
安装 Ollama-OCR
npm install ollama-ocr # or using pnpm pnpm add ollama-ocr
使用 Ollama-OCR
OCR
import { ollamaOCR, DEFAULT_OCR_SYSTEM_PROMPT } from "ollama-ocr"; async function runOCR() { const text = await ollamaOCR({ filePath: "./handwriting.jpg", systemPrompt: DEFAULT_OCR_SYSTEM_PROMPT, }); console.log(text); }
测试的图片如下:

输出的结果如下:
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of instruction-tuned image reasoning generative models in 118 and 908 sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.
输出 Markdown
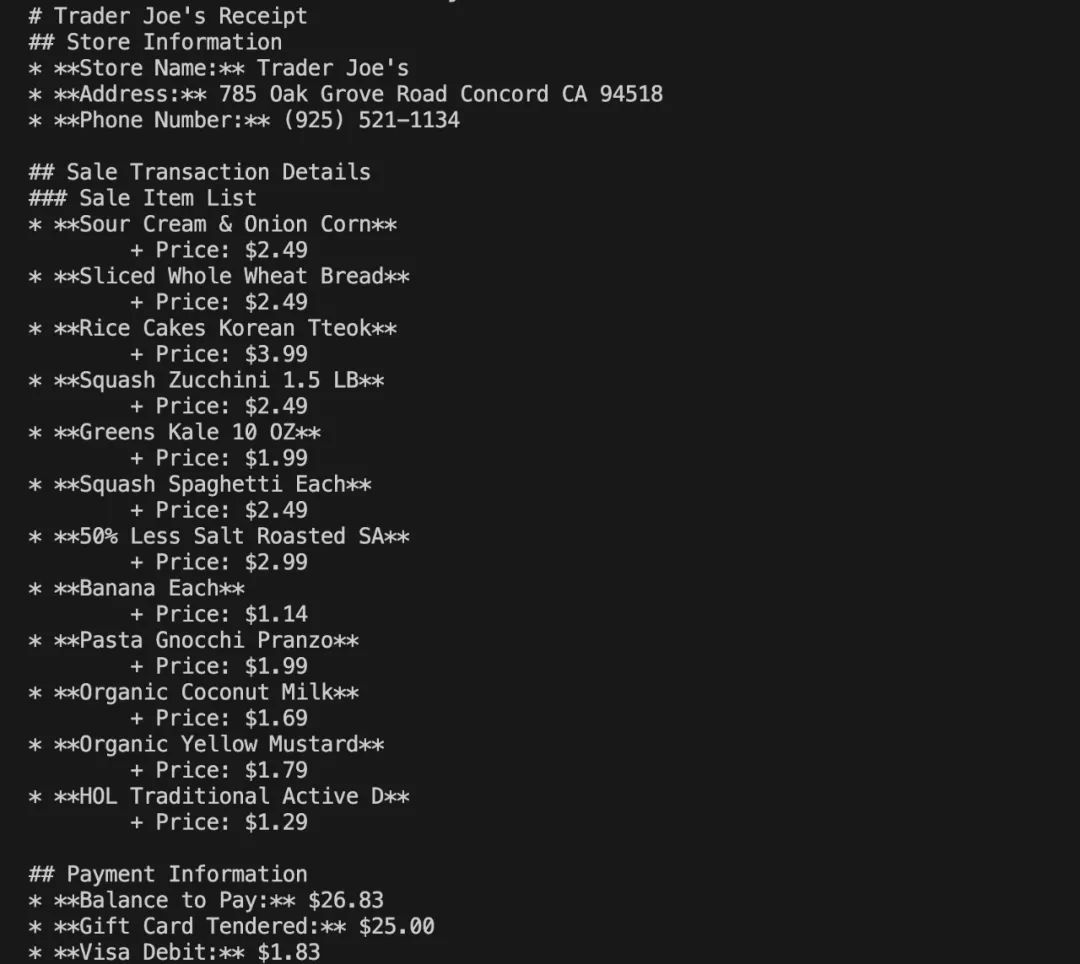
import { ollamaOCR, DEFAULT_MARKDOWN_SYSTEM_PROMPT } from "ollama-ocr"; async function runOCR() { const text = await ollamaOCR({ filePath: "./trader-joes-receipt.jpg", systemPrompt: DEFAULT_MARKDOWN_SYSTEM_PROMPT, }); console.log(text); }
测试的图片如下:

输出的结果如下:
ollama-ocr 使用的本地的视觉模型,如果你想使用线上的 Llama 3.2-Vision 模型,可以试试 llama-ocr[4] 这个库。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









