



AI派在读学生小姐姐Beyonce
Java实战项目练习群
长按识别下方二维码,按需求添加
.jpg")
扫码添加Beyonce小姐姐

扫码关注
进Java学习大礼包
机器学习那些事儿 | 基础知识(一)
1. 常用基本术语
分类(classification):预测结果为「离散值」。回归(regression):预测结果为「连续值」。聚类(clustering):将训练集分为若干个「簇」(cluster),这些自动生成的簇可能对应一些潜在的概念划分。而这些概念我们事先是不知道的,学习过程中使用的训练样本不包含标记信息。二分类(binary classification):只涉及「两个类别」的分类任务。即:正类(positive class)和负类(negative class)。监督学习(supervised learning):训练数据含有标记信息。比如:「分类」、「回归」。无监督学习(unsupervised learning):训练数据不含有标记信息。比如:「聚类」。泛化(generalization)能力:机器学习得到的模型适用于新样本的能力。归纳偏好(inductive bias):机器学习算法在学习的过程中对某种类型假设的偏好。
2.模型评估常用术语
错误率(error rate):如果在个样本中有个样本分类错误,则错误率。精度(accuracy):。误差(error):学习器的实际预测输出与样本的真实输出之间的差异。训练误差(training error)/经验误差(empirical error):学习器在「训练集」上的误差。测试误差(testing error):学习器在「测试集」上的误差。泛化误差(generalization error):学习器在「新样本」上的误差。过拟合(overfitting):学习器学得“太好了”,导致泛化能力下降。欠拟合(underfitting):训练样本的一般性质尚未学好。
3.训练集和测试集划分方法
3.1留出法(hold-out)
直接将数据集划分为两个「互斥」集合,其中一个作为训练集,另外一个作为测试集,即:。
「留出法的注意点:」
训练/测试集的划分要尽可能保持「数据分布」的「一致性」(一般训练集占比为
2/3~4/5);「单次」使用留出法得到的估计结果不够可靠,一般采用采用若干次「随机划分」、「重复进行」实验评估后「取均值」作为最终结果。
3.2交叉验证法(cross validation)
首先,将数据集划分为个大小相似的「互斥」子集,即:。然后,每次用个子集的并集作为训练集,余下的那个子集作为测试集。
这样就可以获得组训练集/测试集,从而进行次训练和测试,最终返回这个个测试结果的「均值」。10折交叉验证示意图如图所示。
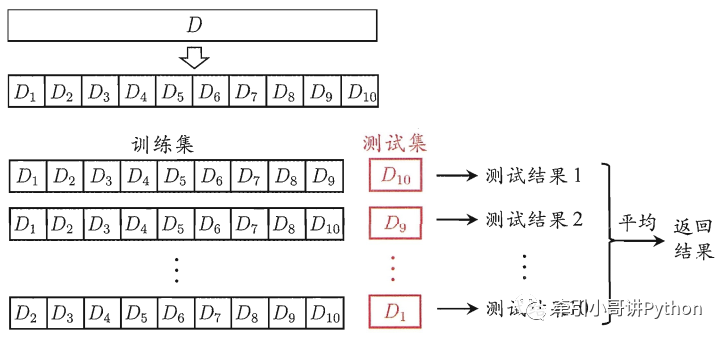
「交叉验证法的注意点:」
为了减小因样本划分带入的差别,折交叉验证通常要随机使用不同的划分「重复次」,最终评估结果是这次折交叉验证结果的「均值」;
假定数据集中包含样本,若令,则得到交叉验证法的特例:「留一法」(Leave-One-Out, LOO)。留一法不受样本随机划分方式的影响。但是数据量大时的计算成本较高。
3.3自助法(bootstrapping)
给定包含个样本的数据集,我们对它进行采样产生数据集:每次随机从中挑选-一个样本,将其拷贝放入,然后再将该样本放回初始数据集中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行次后,我们就得到了包含个样本的数据集,这就是自助采样的结果.
样本在次采样中始终不被采到的概率是,取极限得到
即通过自助采样,初始训练集中约有36.8%的样本未出现在采样数据集中。
「自助法的注意点:」
自助法在数据集「较小」,「难以划分」训练/测试集时很有用;
自助法产生的数据集改变了初始数据集的分布,「引入估计偏差」;
初始数「据量足够时」,留出法和交叉验证法更常用。
参考文献:《机器学习》——周志华
❞
文末福利
各位猿们,还在为记不住API发愁吗,哈哈哈,最近发现了国外大师整理了一份Python代码速查表和Pycharm快捷键sheet,火爆国外,这里分享给大家。
这个是一份Python代码速查表

下面的宝藏图片是2张(windows && Mac)高清的PyCharm快捷键一览图

怎样获取呢?可以添加我们的AI派团队的Beyonce小姐姐
一定要备注【高清图】哦
????????????????????

➕我们的Beyonce小姐姐微信要记得备注【高清图】哦
来都来了,喜欢的话就请分享、点赞、在看三连再走吧~~~


















 1278
1278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









