



“ 数据挖掘算法基于线性代数、概率论、信息论推导,深入进去还是很有意思的,能够理解数学家、统计学家、计算机学家的智慧,这个专栏从比较简单的常用算法入手,后续研究基于TensorFlow的高级算法,最好能够参与到人脸识别和NLP的实际项目中,做出来一定的效果。”
一、理解线性回归模型
首先讲回归模型,回归模型研究的是因变量(目标)和自变量(预测器)之间的关系,因变量可以是连续也可以离散,如果是离散的就是分类问题。思考房价预测模型,我们可以根据房子的大小、户型、位置、南北通透等自变量预测出房子的售价,这是最简单的回归模型,在初中里面回归表达式一般这样写,其中x是自变量,y是因变量,w是特征矩阵,b是偏置。
![]()
在机器学习推导里面引入线性代数的思想,将假设我们用一个表达式来描述放假预测模型,x代表一个房子的特征集,它是一个n×1的列向量,总共有m个特征集,θ是一个n×1的列向量,是我们想要求得未知数。
![]()
我们采用误差最小的策略,比如有预测表达式:y工资=Θ1*学历+Θ2*工作经验+Θ3*技术能力+.......+Θn*x+基本工资,预测的y值和实际值y_存有差距,策略函数就是使得m个特征集的(真实值y-预测值)的平方和最小。(差值可能是负数,所以采用平方和);
![]()
按照对于正规方程的求法,我们对θ 求偏导:
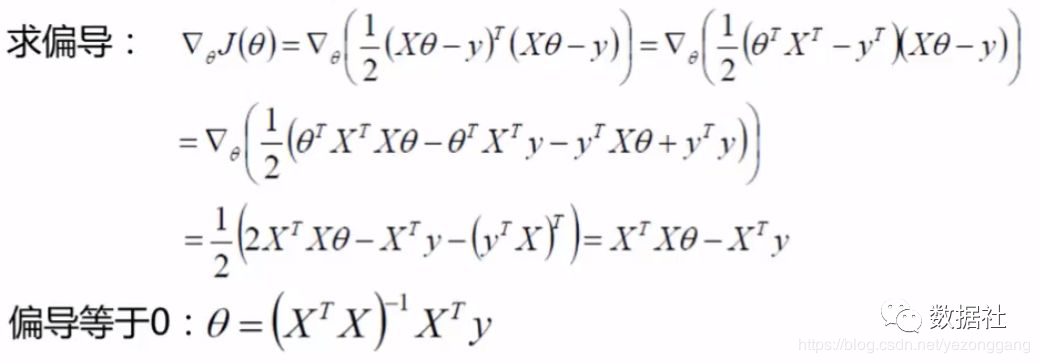
也就是,给定特征矩阵X和因变量y,即可以求使误差率最小的θ值,满足后续的回归模型。了解线性代数的童靴可以看出来问题,在θ的表达式中有求逆运算,需要保证矩阵可逆,这一般是无法保证的,这样就会造成θ无解,策略失效;
二、计算机的做法:梯度下降
常规的方程需要大量的矩阵运算,尤其是矩阵的逆运算,在矩阵很大的情况下,会大大增加计算复杂性。,且正规方程法对矩阵求偏导有一定的局限性(无法保证矩阵可逆),下面介绍梯度下降法,也就是计算机的解决方法,每次走一小步,保证这一小步是最有效的一步,可以想象自己正在下山,你不知道目的地(全局最小值)在哪,但是你能够保证自己每次走的都是最陡峭的一步;
我们的策略仍然保持不变,就是使得m个特征集的(真实值y-预测值)的平方和最小:![]()
梯度下降法实现:赋予初始θ 值,并根据公式逐步更新θ 使得J(θ) 不断减少,最终至收敛,对应的参数θ 即为解。为了推导方便,首先研究只有一个训练样本时,如何计算推导公式。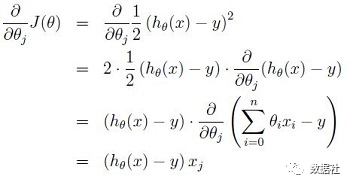
θ 的每个分量更新公式为:
![]()
推广到m个训练数据,参数更新公式为:
![]()
三、逻辑回归模型
逻辑回归与线性回归同属广义线性模型,逻辑回归是以线性回归为理论支持,是一个二分类模型,也可以推广多到分类问题,通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题,首先介绍一下Sigmoid函数:![]()
sigmoid函数图像是一个S曲线,取值在[0, 1]之间,在远离0的地方函数的值会很快接近0或者1,sigmoid函数的求导特性是:
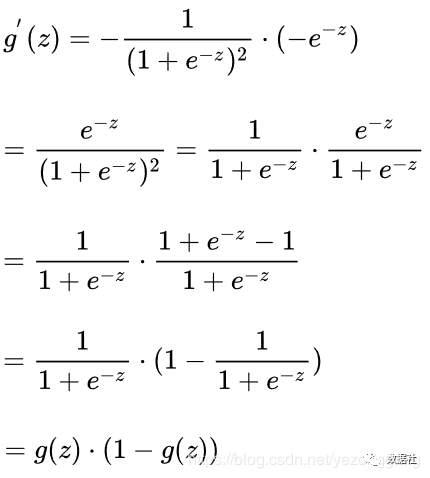
逻辑回归的预测函数是下图,只是在特征到结果的映射中加入了一层函数映射,先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0到1之间:
![]()
通过求似然函数,两边取log后,对θ求偏导:
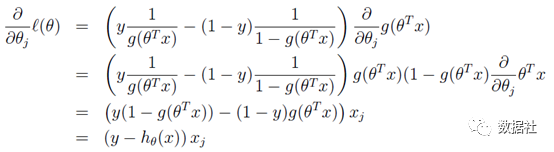 这样我们就得到了梯度上升每次迭代的更新方向,那么θ的迭代表达式为:
这样我们就得到了梯度上升每次迭代的更新方向,那么θ的迭代表达式为:![]()
发现同线性回归模型是同一个表达式,这并不仅仅是巧合,两者存在深层的联系;
四、回归模型使用
数据是2014年5月至2015年5月美国King County的房屋销售价格以及房屋的基本信息。数据分为训练数据和测试数据,分别保存在kc_train.csv和kc_test.csv两个文件中,其中训练数据主要包括10000条记录,14个字段:销售日期,销售价格,卧室数,浴室数,房屋面积,停车面积,楼层数,房屋评分,建筑面积,地下室面积,建筑年份,修复年份,纬度,经度。
数据集地址:https://github.com/yezonggang/house_price,按照流程完成模型建立:
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LinearRegression
# 数据读取
baseUrl="C:\\Users\\71781\\Desktop\\2020\\ML-20200422\\houre_price\\"
house_df=pd.read_csv(baseUrl+'train.csv' )
test_df=pd.read_csv(baseUrl+'test.csv')
house_df.head()
# 删除无关变量
house_df=house_df.drop(['saleTime','year','repairYear','latitude','longitude','buildingSize'],axis=1)
test_df=test_df.drop(['saleTime','year','repairYear','latitude','longitude','buildingSize'],axis=1)
# 模型建立
X_price=house_df.drop(['price'],axis=1)
# X_price.head()
Y_price=house_df['price']
Y_price.head()
LR_reg=LinearRegression()
LR_reg.fit(X_price, Y_price)
Y_pred = LR_reg.predict(test_df)
LR_reg.score(X_price, Y_price)
# 可以选择进行特征缩放
#new_house=house_df.drop(['price'],axis=1)
#from sklearn.preprocessing import MinMaxScaler
#minmax_scaler=MinMaxScaler().fit(new_house) #进行内部拟合,内部参数会发生变化
#scaler_housing=pd.DataFrame(minmax_scaler.transform(new_house),columns=new_house.columns)
#mm=MinMaxScaler()
#mm.fit(test_df)
#scaler_t=mm.transform(test_df)
#scaler_t=pd.DataFrame(scaler_t,columns=test_df.columns)
文末福利
各位猿们,还在为记不住API发愁吗,哈哈哈,最近发现了国外大师整理了一份Python代码速查表和Pycharm快捷键sheet,火爆国外,这里分享给大家。
这个是一份Python代码速查表

下面的宝藏图片是2张(windows && Mac)高清的PyCharm快捷键一览图

怎样获取呢?可以添加我们的AI派团队的程序媛姐姐
一定要备注【高清图】哦
????????????????????

➕我们的程序媛小姐姐微信要记得备注【高清图】哦
来都来了,喜欢的话就请分享、点赞、在看三连再走吧~~~


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









